# Ensuring Tenant Scoping in Kong Konnect Using Row-Level Security
Vincent Le Goff
Senior Staff Software Engineer, Kong
In the SaaS world, providers must offer tenant isolations for their customers and their data. This is a key requirement when offering services at scale. At Kong, we've invested a lot of time to provide a scalable and seamless approach for developers to avoid introducing breaches in our systems.
In this article, we'll explore the challenges of tenant scoping and how we address them effectively.
## What cards do we have in our hand?
### Separated databases
This approach provides a pure data isolation as the data is separated from the rest of the stack. This is how you can reach the maximum isolation of the data.
However, resource requirements and operational costs are high, which can trickle down to the product itself.
### Shared database, separate schema
Putting all tenants in the same database but in separate schemas reduces the resource requirements and is easier to manage at a scale from an operational point of view. However, regarding the application side, it still creates operational costs. This means, for example, a data migration will still have to run on all schemas — same problem as separate databases.
### Shared database, shared schema
If all the tenants use the same database and schema it means that the data of all tenants are all together. This can scale as much as we want based on the application consumption.
However, we have a data isolation issue here. Because all tenants are mixed together in the same datastore, we need a security layer to ensure that applications can't leak organizations' data.
One possibility would be to have a “trust the programmer” approach, where we rely on the engineering team's diligence to write and properly review the code. But we all are humans and make mistakes.
To address this security issue, there's the concept of row-level security, which puts us in between shared database, shared schema and shared database, separate schema.
## Row-level security
Row-level security (or RLS) defines the practice of applying security checks in a datastore per row, meaning that the actor of the query will only process the data they’re supposed to have access to. This is more fine-grained than database-level security or schema-level security that the two previously mentioned approaches would apply.
Depending on how you manage your user, you might choose different approaches for user management/permission. Here we're going to take the simple approach of having one admin user and one RLS user.
-- Create the admin user
CREATE USER "myapp_admin" WITH LOGIN PASSWORD 'myapp_admin';
GRANT USAGE ON SCHEMA public TO "myapp_admin";
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO "myapp_admin";
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO "myapp_admin";
-- explicitely set the bypass rls for the admin user
ALTER ROLE myapp_admin BYPASSRLS;
-- create the RLS user
CREATE USER "myapp_rls" WITH LOGIN PASSWORD 'myapp_rls';
GRANT USAGE ON SCHEMA public TO "myapp_rls";
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA public TO "myapp_rls";
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT, INSERT, UPDATE, DELETE ON TABLES TO "myapp_rls";
We need to alter the role of `myapp_admin` to be sure it can bypass row-level security policies for some specific operations like data migrations.
### Schema design
To achieve tenant isolation, some design considerations are needed when creating the tables. We need to add a column for the tenant identifier, which we'll call “tenant_id”. Depending on the database design, it can either be a NOT NULL column or a foreign key to the tenant table in the database. In Konnect we're using a microservice architecture, which means that the tenant table is only in our identity service; this leads us to use a NOT NULL column without a foreign key in the design.
Example:
CREATE TABLE IF NOT EXISTS apis (
Id uuid NOT NULL, name text NOT NULL, tenant_id uuid NOT NULL DEFAULT, CONSTRAINT apis_pk PRIMARY KEY (id)
);
### Table RLS policies
Now that the table has been properly created, we need to create the policies. This includes the functions to be applied by the policies and the policies themselves.
We'll first define the functions we need, set get and unset.
In the function, you can see we're using the “set_config” API from PostgreSQL which allows us to store data in the context of the session or the transaction. In the current implementation, we're storing it at the SESSION level and not the transaction. This is because we ensure via the connection pooling that we're scoping the session per tenant.
-- setting the tenant in session scope
CREATE OR REPLACE FUNCTION set_tenant(tenant TEXT) RETURNS VOID AS
$$
DECLARE
v_value UUID;
BEGIN
v_value := tenant::UUID;
PERFORM set_config('app.current_tenant', tenant,false);
END;
$$ LANGUAGE plpgsql SECURITY DEFINER
STABLE;
-- un-setting the tenant in session scope
CREATE OR REPLACE FUNCTION unset_tenant() RETURNS VOID AS
$$
BEGIN
PERFORM set_config('app.current_tenant', '',false);
END;
$$ LANGUAGE plpgsql SECURITY DEFINER
STABLE;
-- Get the current tenant value that is set in the session context
CREATE OR REPLACE FUNCTION get_tenant() RETURNS UUID AS
$$
DECLARE
v_value UUID;
v_s_value TEXT;
BEGIN
v_s_value := current_setting('app.current_tenant',true);
IF v_s_value = '' THEN
RETURN NULL;
END IF;
v_value := current_setting('app.current_tenant',true):: UUID;
RETURN v_value;
END ;
$$ LANGUAGE plpgsql SECURITY DEFINER
STABLE;
After bootstrapping the functions that the policies will use, we have to apply a policy to it to ensure the tenant isolation. The policy would look like so:
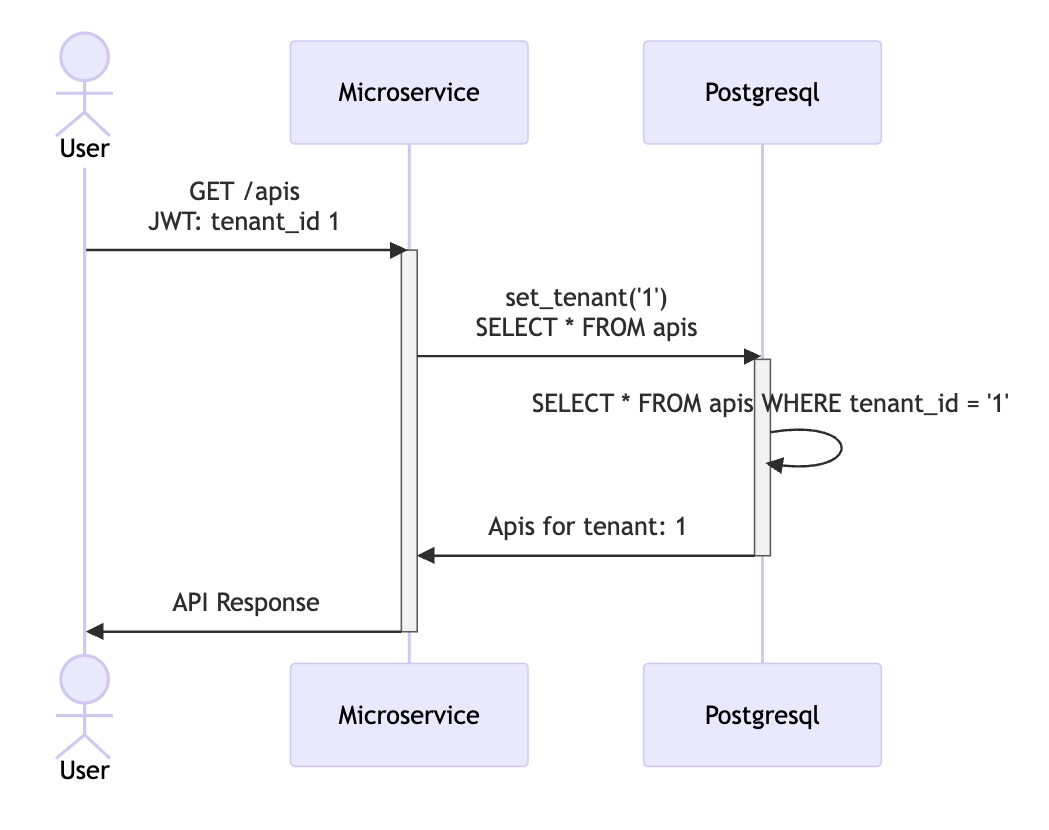
CREATE POLICY apis_policy ON apis USING (tenant_id = get_tenant());
For example: `Select * from APIs where name = “bar”;` will end up being processed as `Select * from APIs where name = “bar” and tenant_id = get_tenant();`
By extension, a statement like this `Select * from apis where tenant_id = “01b0616c-4ad2-4aa1-be81-dfd34d194d8f”; `will end up `Select * from apis where tenant_id = “01b0616c-4ad2-4aa1-be81-dfd34d194d8f”` and `tenant_id = get_tenant();` leading to no result if the two IDs are different.
The same applies on any SQL query like `INSERT`, `UPDATE` etc. In the case of those, if the constraint isn't met by having a `tenant_id` different from the result of `get_tenant();` the query will error out.
Then we enable it:
ALTER TABLE apis ENABLE ROW LEVEL SECURITY;
On another note, we would prefer to set the `tenant_id` directly using the function rather than using the application layer to set it. Like this:
CREATE TABLE IF NOT EXISTS apis (
Id uuid NOT NULL, name text NOT NULL, tenant_id uuid NOT NULL DEFAULT get_tenant(), CONSTRAINT email_domain_pk PRIMARY KEY (id)
);
## Concept of the flow
### Transitioning to row-level security policies
This can be achieved smoothly if you have strong end-to-end test suites. At Kong we heavily rely on end-to-end tests and our test spins a new tenant for every run. With this approach, we're sure that when we switch a non-RLS user to an RLS user if there's an issue in a query / code it will be spotted in our continuous integration.
## Implementations
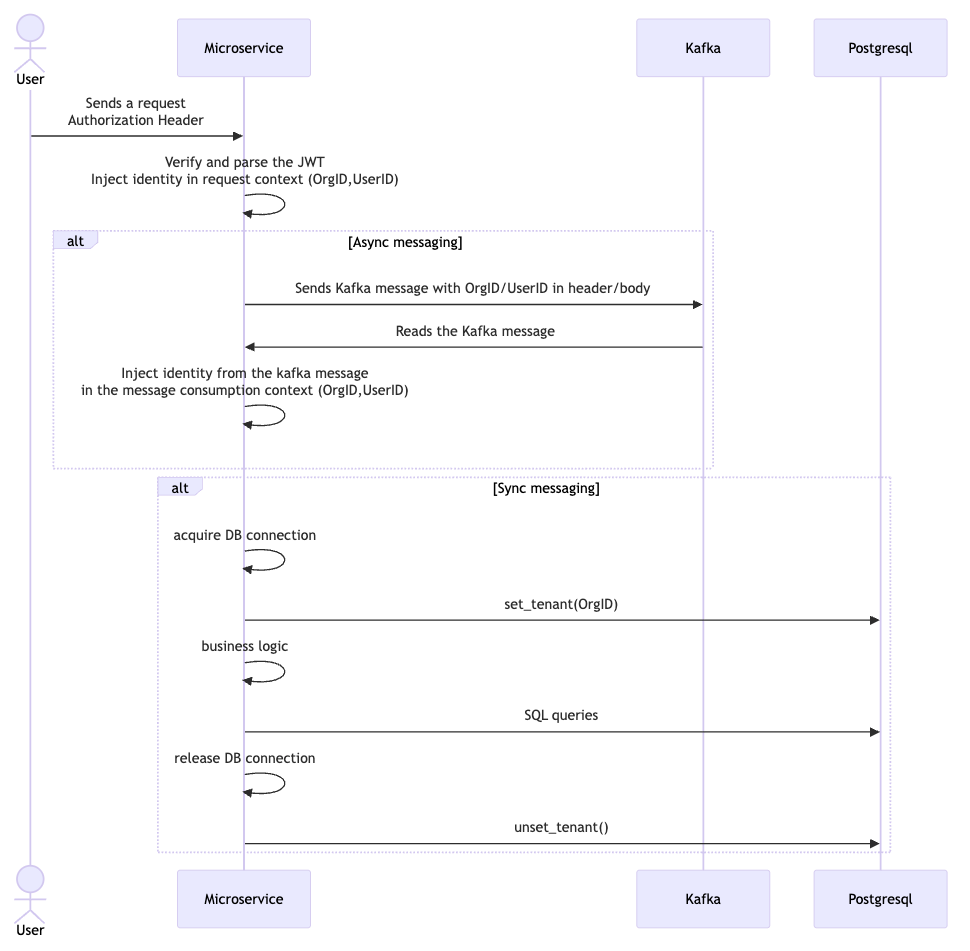
At Kong, we use Golang and TypeScript as primary languages for our microservices. We developed for both of these languages tooling to ensure the RLS adoption is smooth and secure. Let's dive into the Golang approach for this post.
In the PSQL functions we're setting the config per sessions and not per transaction. This is because both languages rely on connection pooling; which provides us a hook to set and unset the tenant when acquiring the connection.
// AuthN is a middleware ensuring the request is authenticated and injects the identity// within the request contextfunc AuthN(authenticationService AuthenticationService) func(next http.Handler) http.Handler { return func(next http.Handler) http.Handler { return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {// trying to authenticate the request identity, err := authenticationService.AuthenticateRequest(r)
// Request hasn't been authenticated, we return 401 if err != nil { http.Error(w,"Unauthenticated",401)
return
}// Adding the identity within the request context ctx := auth.ContextWithIdentity(r.Context(), identity)
// overriding the current context of the request with the newly// hydrated context with our identity r = r.WithContext(ctx)
// continuing the request flow next.ServeHTTP(w,r)
})
}}
Below is the example of how a pgxpool would be configured regarding the RLS part:
func configureRLS(pgxConfig *pgxpool.Config, l *zap.Logger) { pgxConfig.BeforeAcquire = func(ctx context.Context, c *pgx.Conn) bool { tenantID, err := getContextTenantID(ctx)
if err != nil {// Case when there's no auth in the context return true} _, err = c.Exec(ctx, fmt.Sprintf("SELECT set_tenant('%s')", tenantID))
if err != nil { l.Error("could not set tenant on postgres connection", zap.Error(err))
}// always return true, otherwise this will end up creating and destroying postgres connections in a loop return true} pgxConfig.AfterRelease = func(c *pgx.Conn) bool { _, err := c.Exec(context.Background(),"SELECT unset_tenant()")
if err != nil { l.Error("could not unset tenant on postgres connection", zap.Error(err))
} return err == nil
}}func getContextTenantID(ctx context.Context) (uuid.UUID,error) {// retrieve the tenant ID from the context ...
}
When you read the line returning "true” when no auth in the context it seems like a code smell, but we're talking about two different things in that case. When the auth is not set, there won't be an invocation of “set_tenant” psql function, meaning it won't return any data from a table that has a security policy enabled. We want to always return true in our case otherwise the connection won't be acquired but it should be from the pool point of view.
Then you can use the pgxpool to execute queries seamlessly.
## Conclusion
Row-level security might initially seem challenging to implement, but it's essential when using a tenant-shared schema.
Without RLS you can't ever be sure that the tenant has been properly isolated and put all your trust in the code and in your test suites. With RLS you have the insurance that database queries are properly tenant scoped.
Traditional agreement processes were slow and heavily manual. Documents were often created in office tools, shared through email, printed, signed physically, and stored across multiple systems. Tracking the status of agreements required manual follo
Paige Rossi
# APISecOps Tutorial: Delivering APIs Securely Together with Kong Konnect and Red Hat OpenShift Service on AWS (ROSA)
Red Hat OpenShift is the industry's leading enterprise Kubernetes platform that runs ubiquitously across on-prem, and the cloud. With Red Hat OpenShift Service on AWS (ROSA) , a managed Red Hat OpenShift platform that runs natively on AWS, it is
Danny Freese
# 3 Ways to Protect Your APIs With Kong Konnect and Fastly (Signal Sciences)
Fastly's next-gen WAF (formerly Signal Sciences ) integrates with Kong Konnect to block malicious requests to your services. Kong Gateway provides a robust and secure enterprise API management platform to front web traffic. In partnership, Fastly
Claudio Acquaviva
# Local Previews and Agent-Driven Authoring for Your Konnect Dev Portal
What it is
The Konnect Dev Portal Toolkit is a free extension published by Kong Inc. on the Visual Studio Code Marketplace (ID konghq.vscode-konnect-dev-portal-toolkit) and on Open VSX.
Konnect Developer Portals are how teams publish API document
Adam DeHaven
# Kafka in a DMZ: Protecting AWS MSK with Kong Event Gateway
The MSK exposure problem
Amazon MSK brokers live in private subnets by default. That's the right default. Kafka's protocol wasn't designed for untrusted networks — it has no concept of rate limiting, no built-in field-level encryption, and its ACL
Hugo Guerrero
# How to Set Up Prepaid Credits in Kong Konnect Metering & Billing
The core of this system rests on a foundational principle: currency-specific credit balances are never directly modified. Rather than a simple mutable counter, which is prone to race conditions and opaque manual adjustments, we utilize a comprehensi
Dan Temkin
# How to Test Gateway APIs Directly from Kong Konnect with Insomnia
What You'll Build
To explore the new integration, I'll build a realistic API platform workflow using Konnect, Kong Gateway, and Insomnia.
By the end of this tutorial, I'll have:
A Konnect Control Plane (KongAir Dev)
A local Kong Gateway Data Pl
Juhi Singh
# Automating Agreement Workflows with Kong Konnect and Docusign for Developers
Traditional agreement processes were slow and heavily manual. Documents were often created in office tools, shared through email, printed, signed physically, and stored across multiple systems. Tracking the status of agreements required manual follo
Paige Rossi
# APISecOps Tutorial: Delivering APIs Securely Together with Kong Konnect and Red Hat OpenShift Service on AWS (ROSA)
Red Hat OpenShift is the industry's leading enterprise Kubernetes platform that runs ubiquitously across on-prem, and the cloud. With Red Hat OpenShift Service on AWS (ROSA) , a managed Red Hat OpenShift platform that runs natively on AWS, it is
Danny Freese
# 3 Ways to Protect Your APIs With Kong Konnect and Fastly (Signal Sciences)
Fastly's next-gen WAF (formerly Signal Sciences ) integrates with Kong Konnect to block malicious requests to your services. Kong Gateway provides a robust and secure enterprise API management platform to front web traffic. In partnership, Fastly
Claudio Acquaviva
# Local Previews and Agent-Driven Authoring for Your Konnect Dev Portal
What it is
The Konnect Dev Portal Toolkit is a free extension published by Kong Inc. on the Visual Studio Code Marketplace (ID konghq.vscode-konnect-dev-portal-toolkit) and on Open VSX.
Konnect Developer Portals are how teams publish API document
Adam DeHaven
# Kafka in a DMZ: Protecting AWS MSK with Kong Event Gateway
The MSK exposure problem
Amazon MSK brokers live in private subnets by default. That's the right default. Kafka's protocol wasn't designed for untrusted networks — it has no concept of rate limiting, no built-in field-level encryption, and its ACL
Hugo Guerrero
# How to Set Up Prepaid Credits in Kong Konnect Metering & Billing
The core of this system rests on a foundational principle: currency-specific credit balances are never directly modified. Rather than a simple mutable counter, which is prone to race conditions and opaque manual adjustments, we utilize a comprehensi
Dan Temkin
# How to Test Gateway APIs Directly from Kong Konnect with Insomnia
What You'll Build
To explore the new integration, I'll build a realistic API platform workflow using Konnect, Kong Gateway, and Insomnia.
By the end of this tutorial, I'll have:
A Konnect Control Plane (KongAir Dev)
A local Kong Gateway Data Pl
Juhi Singh
# Automating Agreement Workflows with Kong Konnect and Docusign for Developers
Traditional agreement processes were slow and heavily manual. Documents were often created in office tools, shared through email, printed, signed physically, and stored across multiple systems. Tracking the status of agreements required manual follo
Paige Rossi
# APISecOps Tutorial: Delivering APIs Securely Together with Kong Konnect and Red Hat OpenShift Service on AWS (ROSA)
Red Hat OpenShift is the industry's leading enterprise Kubernetes platform that runs ubiquitously across on-prem, and the cloud. With Red Hat OpenShift Service on AWS (ROSA) , a managed Red Hat OpenShift platform that runs natively on AWS, it is
Danny Freese
# 3 Ways to Protect Your APIs With Kong Konnect and Fastly (Signal Sciences)
Fastly's next-gen WAF (formerly Signal Sciences ) integrates with Kong Konnect to block malicious requests to your services. Kong Gateway provides a robust and secure enterprise API management platform to front web traffic. In partnership, Fastly
Claudio Acquaviva
# Local Previews and Agent-Driven Authoring for Your Konnect Dev Portal
What it is
The Konnect Dev Portal Toolkit is a free extension published by Kong Inc. on the Visual Studio Code Marketplace (ID konghq.vscode-konnect-dev-portal-toolkit) and on Open VSX.
Konnect Developer Portals are how teams publish API document
Adam DeHaven
# Kafka in a DMZ: Protecting AWS MSK with Kong Event Gateway
The MSK exposure problem
Amazon MSK brokers live in private subnets by default. That's the right default. Kafka's protocol wasn't designed for untrusted networks — it has no concept of rate limiting, no built-in field-level encryption, and its ACL
Hugo Guerrero
# How to Set Up Prepaid Credits in Kong Konnect Metering & Billing
The core of this system rests on a foundational principle: currency-specific credit balances are never directly modified. Rather than a simple mutable counter, which is prone to race conditions and opaque manual adjustments, we utilize a comprehensi
Dan Temkin
# How to Test Gateway APIs Directly from Kong Konnect with Insomnia
What You'll Build
To explore the new integration, I'll build a realistic API platform workflow using Konnect, Kong Gateway, and Insomnia.
By the end of this tutorial, I'll have:
A Konnect Control Plane (KongAir Dev)
A local Kong Gateway Data Pl
Juhi Singh
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.