## 🚧 The challenge: Scaling GenAI with governance
While building a GenAI-powered agent for one of our company websites, I integrated components like LLM APIs, embedding models, and a RAG (Retrieval-Augmented Generation) pipeline. The application was deployed using a Flask API backend and secured with API keys.
However, post-deployment, several operational challenges emerged:
- - Escalating LLM usage costs
- - Security risks from exposed API keys and prompt injection
- - Limited observability into prompt flows, token usage, and latency
- - Difficulty in maintaining and scaling the API infrastructure
It became clear that while the GenAI logic was sound, the API layer lacked enterprise-grade governance. That’s when I turned to Kong Gateway, specifically its AI Gateway capabilities.
## 🤖 Why Kong Gateway for GenAI?
Kong isn’t just a traditional API gateway; it now offers a dedicated [AI Gateway](https://konghq.com/products/kong-ai-gateway)AI Gateway designed to meet the unique demands of GenAI workloads. Here’s what makes it ideal:
- - AI Manager: Centralized control plane for LLM APIs
- - One-Click API Exposure: Secure and governed API publishing
- - Secure Key Management: Store secrets in Kong Vault
- - Prompt Guard Plugin: Prevent prompt injection attacks
- - Semantic Routing: Route prompts based on intent/context
- - RAG Pipeline Simplification: Offload orchestration to the gateway
- - Caching & Optimization: Reduce token usage and latency
- - Observability & Analytics: Monitor usage, latency, and cost
- - Rate Limiting & Quotas: Control overuse and manage budgets
- - Future-Ready: Support for multi-agent protocols like MCP and A2A
These features allowed me to shift complexity away from the backend and focus on GenAI logic.
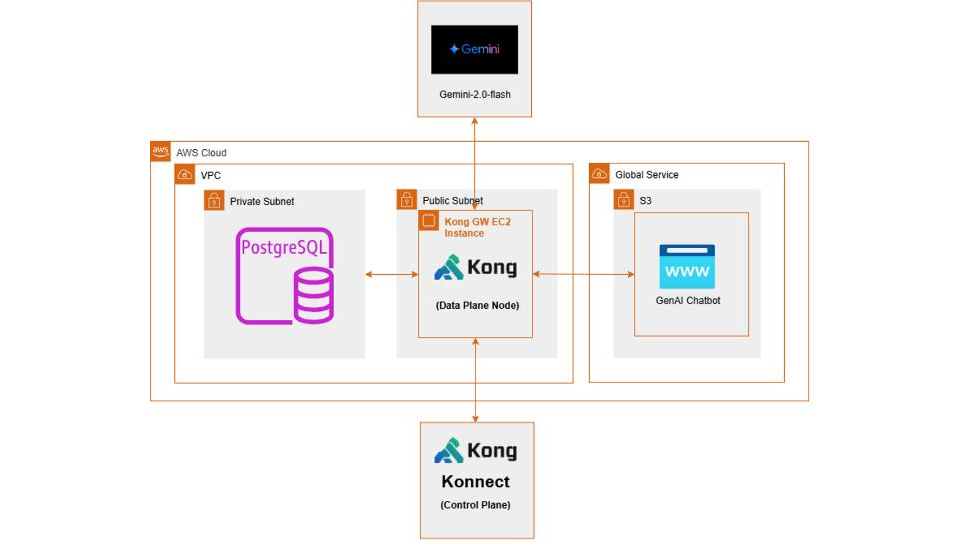
## 🧱 Architecture overview
This architecture, built on AWS, leverages [Kong Gateway](https://konghq.com/products/kong-gateway)Kong Gateway to securely manage interactions between internal services and external LLM providers. The environment described reflects my development setup, including AWS services and supporting technologies.
For production deployments, I recommend evaluating and adopting a more robust technology stack and configuration to ensure enhanced security, compliance, scalability, and high availability.
## 🔄 Challenge vs. solution matrix