When a data breach occurs involving a cloud service, the impulsive reaction is to denounce using the cloud (at least for sensitive information). Since cloud security is not widely understood, it may be difficult to delineate it in the context of more general information security.
Out of the box, AWS offers multiple strategies for [account security](https://aws.amazon.com/answers/security/aws-secure-account-setup)account security, [configuration management](https://aws.amazon.com/answers/configuration-management/aws-infrastructure-configuration-management)configuration management, and [disaster recovery](https://aws.amazon.com/compliance/data-center/controls)disaster recovery. It provides top-grade [physical security](https://aws.amazon.com/compliance/data-center/controls)physical security for its data centers and [network-wide protection](https://aws.amazon.com/shield)network-wide protection from threats such as distributed denial-of-service (DDoS) attacks. Its underlying infrastructure and platforms are already PCI (Payment Card Industry) and HIPAA (Health Insurance Portability and Accountability Act) [compliant](https://aws.amazon.com/compliance/programs)compliant. For any leaders who have to solve each of those problems from scratch, attempting to meet a CSP's level of protection on their own would prove intractable.
In short, avoiding the cloud would introduce *more, *rather than* fewer, *security concerns for a company. So, what do companies need to do to ensure that they can *at least* cover their portion of [shared responsibility](https://aws.amazon.com/compliance/shared-responsibility-model)shared responsibility? We will examine how an S3 breach could happen, what can be done to mitigate it and how to ensure that occasional vulnerabilities do not result in full-on breaches.
## How could data in an S3 bucket be breached?
As with many issues in information security, the problem is often far more straightforward than the solution:
- - If an attacker has **stolen credentials** to an account that has **access** to an S3 bucket, all the lower-level network protection in the world will not stop the attacker from at least *opening* the bucket. A breach involves more than opening the bucket, though—an attacker would also need to be able to *extract* the data.
- - If an attacker can **extract** massive amounts of content without triggering **alarms** or activating automated **prevention**, the defender will not know about the breach. That is, not until the content is posted publicly or exploited in a way that harms the company (and possibly its customers). But even if the attacker can extract content, it is not useful unless the content is *understandable*.
- - If an attacker can **read** or **decrypt** the content, there is nothing to prevent it from spreading and being exploited. Although there are many other concerns to review as well, storing the material in a plain (i.e., unencrypted) format *ensures* that the confidentiality or integrity of the content can be compromised.
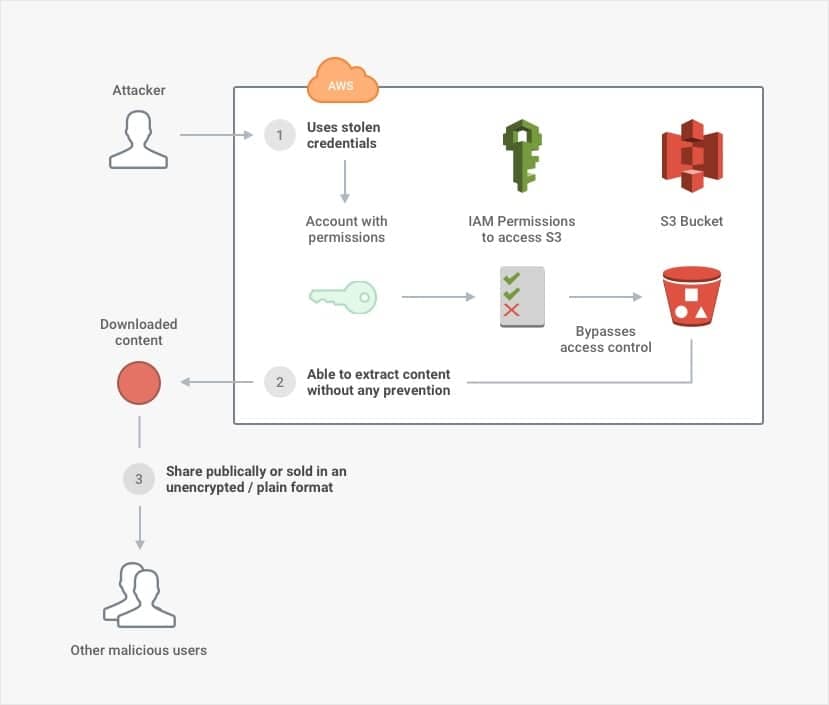
Importantly, it is worth noting that a breach involves *multiple* points of failure. In this case, it requires a *combination* of stolen credentials for access, unmonitored and unlimited extraction, and readable content to result in a bona fide breach. When the explanation for a breach is "human error" or "firewall misconfiguration," it is easy to imagine that justonething went wrong. In reality, *many* other security controls needed to be absent or ineffective for one flaw to become catastrophic.
## How can data in an S3 bucket be protected from a breach?
There are more ways an attacker can steal credentials than by reading a Post-It note. Frustrating password complexity requirements are only *more *likely to cause someone to write a password down somewhere. A password is supposed to be "something you know," but it is quickly becoming impossible to remember. As a result, we use other factors to help "remember" passwords, such as proving "something you are" when we use our fingerprints to open 1Password. A [public GitHub repository](https://www.theregister.co.uk/2015/01/06/dev_blunder_shows_github_crawling_with_keyslurping_bots)public GitHub repository or an [unsecured host](https://rift.stacktitan.com/attacking-aws-consumers)unsecured host could easily give away credentials. Often, these credentials are intended for service accounts (i.e., non-human, machine accounts) but could be used by an attacker to access the same services as well.
Static credentials, such as passwords and API keys, should not be the only criteria for obtaining access, given how easy they are to compromise. A combination of other factors, such as geolocation, hardware tokens or detection of user behavior, could be implemented to support authentication.
In [AWS Identity and Access Management (IAM)](https://aws.amazon.com/iam)AWS Identity and Access Management (IAM), there are several different ways to enable [multi-factor authentication](https://aws.amazon.com/iam/details/mfa)multi-factor authentication. A user must use a rotating token ("something you have") *in addition* to the user's password ("something you know") to gain access to the account. A company can limit access to its resources so that a user needs to provide a rotating code each time the user wants to conduct a sensitive activity. For example, with S3, there is an option to [require MFA if a user wants to delete an object](https://docs.aws.amazon.com/AmazonS3/latest/dev/UsingMFADelete.html)require MFA if a user wants to delete an object.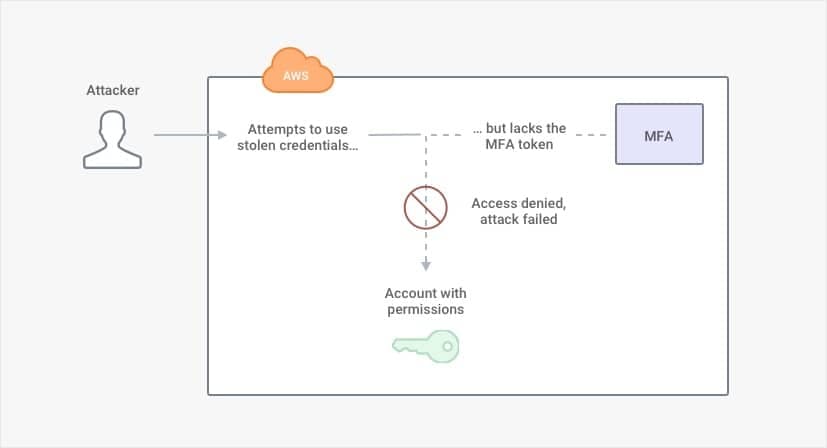
But suppose an attacker did somehow gain credentials for each factor of authentication? Perhaps the attacker is a malicious insider. Maybe the attacker stole the hardware token from an employee's desk and took a picture of the password written on a Post-It note. If the employee was too embarrassed or too preoccupied to report the missing token, the attacker could easily bypass multi-factor authentication (MFA).
In that case, the next line of defense is to limit what each account can do. This limitation includes defined permissions and automated responses if an account exhibits suspicious behavior. AWS's managed services support many of the technical controls that companies would otherwise need to buy individually or build from scratch. Consider the following solutions:
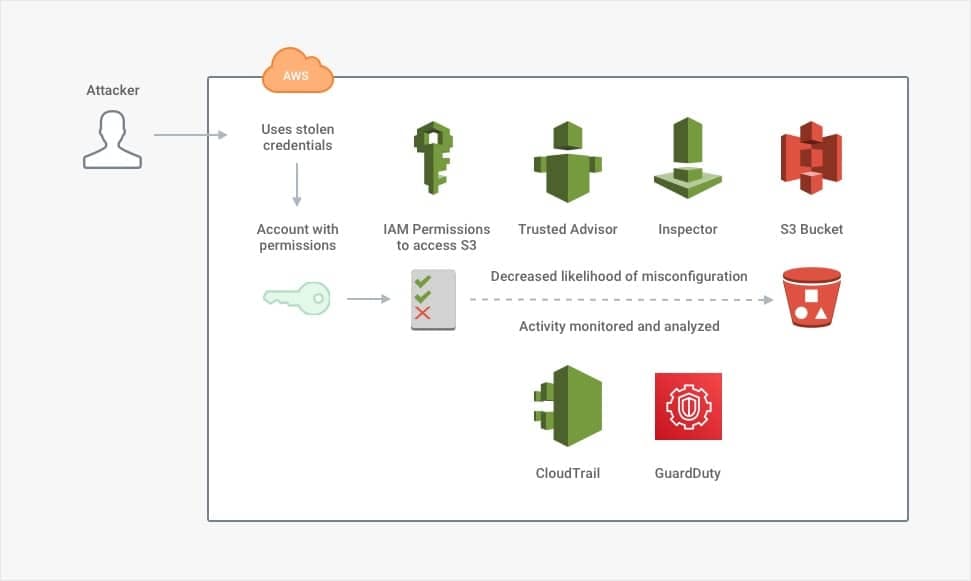
Even with this host of technical controls, the underlying assumption is that an organization has policies in place to prevent excessive or accidental use of access *even under normal circumstances. *Following the [principle of least privilege](https://docs.aws.amazon.com/IAM/latest/UserGuide/best-practices.html#grant-least-privilege)principle of least privilege makes an account compromise less *impactful. *
The absolute worst-case scenario would be that all users start with Administrator access. For AWS, all users (save for the root account) start with *no *permissions, so that every privilege a company grants them must be deliberate. From that point, security relies on how organizations decide to give access. Suppose that one account never has a reason to download or delete sensitive files. Also, suppose that the company fully trusts the *user* who owns that account. It still would not make sense to grant limitless permissions to the *account* due to the potential for accidents, let alone a malicious compromise.
S3 buckets are [_private by default—_](https://docs.aws.amazon.com/AmazonS3/latest/dev/s3-access-control.html)_private by default—_no one besides the owner may have access to the buckets until their group explicitly receives permission. Although S3 has a particular version of [_ACLs_](https://docs.aws.amazon.com/AmazonS3/latest/dev/acl-overview.html)_ACLs_, the current best practice is to set [_user policies_](https://docs.aws.amazon.com/AmazonS3/latest/dev/example-policies-s3.html)_user policies_ or [_bucket policies_](https://docs.aws.amazon.com/AmazonS3/latest/dev/example-bucket-policies.html)_bucket policies__._ The choice depends on which perspective (i.e., users or buckets) is more natural for an organization to manage access.
Besides determining who may read and write the contents of the bucket, there is a related concern about content distribution. Ideally, people outside of an organization would never access buckets directly. In case the contents are intended for broad, public access, a company can manage distribution through an intermediary service such as [CloudFront](https://aws.amazon.com/cloudfront)CloudFront rather than directly from S3.
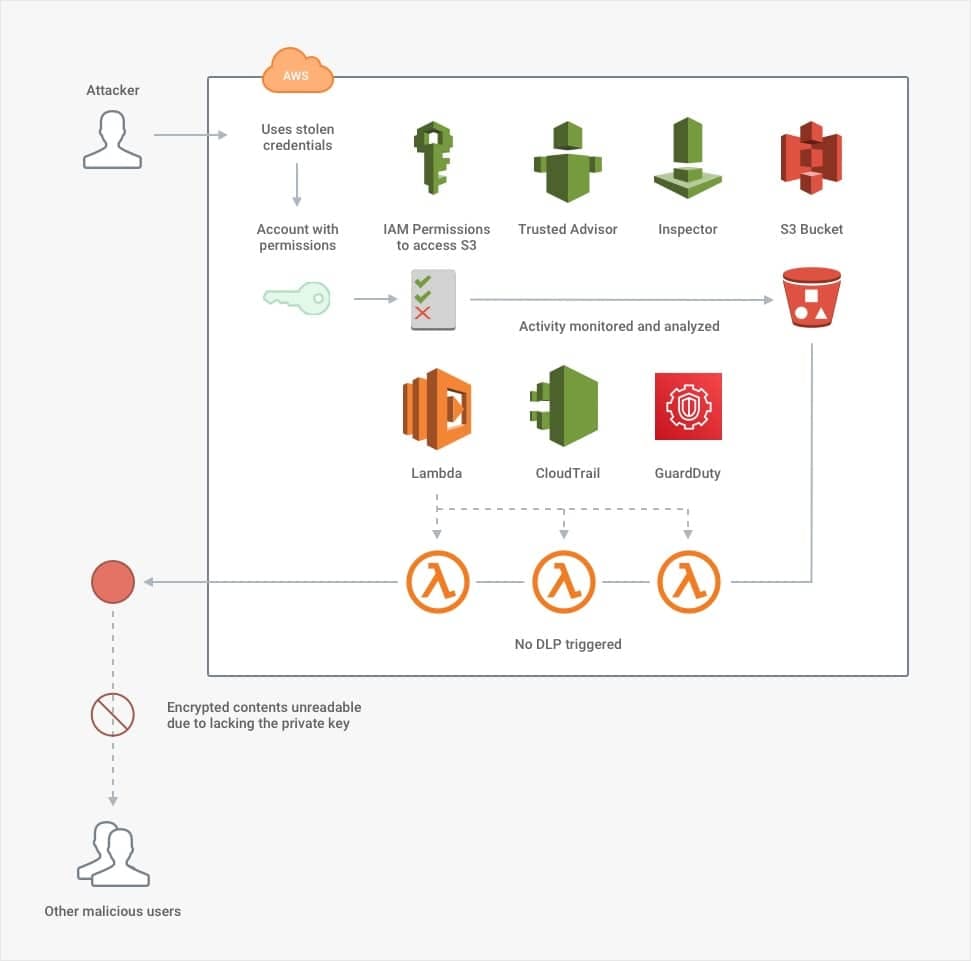
But suppose that with these controls in place, *alas*—an attacker still gets through. The attacker has stolen credentials for an Administrator account (i.e., they have the highest level of permissions). Whether by chance or by having conducted extensive reconnaissance, the attacker has not done anything suspicious that would trigger any alarms.
Even if this were the case, no one should be able to download 100,000 medical files without a company's security batting an eyelid. This situation calls for data-loss prevention (DLP) controls. AWS [Lambda](https://docs.aws.amazon.com/lambda/latest/dg/welcome.html)Lambda can be configured to trigger based on[ S3 events](https://docs.aws.amazon.com/lambda/latest/dg/with-s3.html) S3 events, [CloudTrail events](https://docs.aws.amazon.com/lambda/latest/dg/with-cloudtrail.html)CloudTrail events, [GuardDuty events](https://aws.amazon.com/blogs/security/how-to-use-amazon-guardduty-and-aws-web-application-firewall-to-automatically-block-suspicious-hosts)GuardDuty events or any other number of services. It could be set to fire off and prevent suspicious activity automatically. Many third-party services offer DLP support, following a similar pattern of constant detection and automated enforcement.
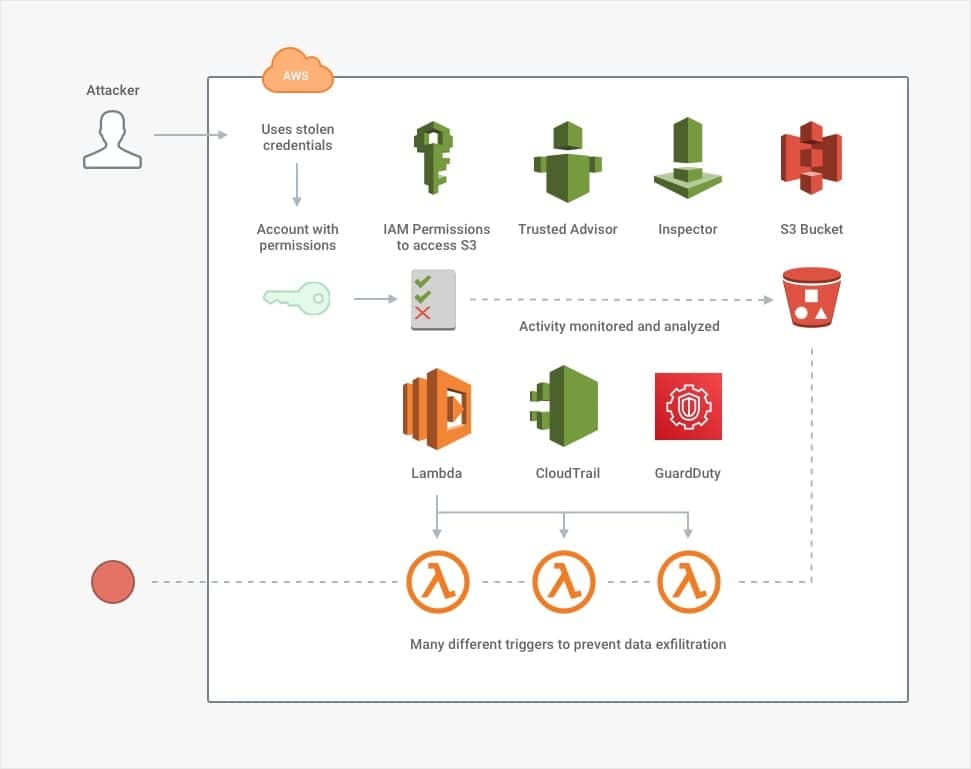
In the absolute worst-case scenario, suppose an attacker successfully downloads the contents of the S3 bucket. The attacker carefully planned to download the contents in such tiny fragments that they match the existing pattern of innocent users, so they snuck past all of the DLP controls. Now, there is only one defensive measure left: encryption.
By using client-side or customer-provided keys, a company can maintain complete ownership of *how* its data is encrypted and *what *can unlock it. That way, it can establish additional barriers that separate the key from the lock. At this point, a company can realize the main benefit of on-premise security *in support of* the cloud. Even if a company's assets are entirely cloud-based, it still might retain the unique ability to *unlock* all of them with an on-premise key. This type of client-based key management is often a requirement for compliance. In the case of the breach described above, it would render an attack harmless unless the attacker *also* had access to the key. To gain access to an on-premise key would be an entirely separate feat well outside the scope of the attack in the diagrams.
## How can companies ensure that occasional vulnerabilities cannot be exploited?
Companies are only able to do their best, and as such, they have an impossible task in covering, let alone *knowing*, all of their vulnerabilities. Still, that does not imply that (1) all vulnerabilities can or will be exploited, or (2) that it is futile to resist. Attackers are at a significant advantage in that they only need to find *one* way in and out. Companies need to defend *all *of those points. Still, before finding an opening, attackers will often encounter many failed attempts along the way. That is to say that things would be *much worse* if companies didn't try at all and that things could at least be better if they tried harder.
## The key takeaways:
- - Existing, managed services are often a much simpler and safer option than handcrafting one’s own.
- - The aspect of shared responsibility that falls on a cloud customer would *still *be the customer's responsibility if it were strictly on-premise.
- - A company’s defense needs to be an in-depth, automated, and diverse combination of:
- -
- - administrative controls that limit account privileges
- - configuration controls that detect vulnerable settings and compliance violations
- - detective and preventive controls that passively monitor and actively respond to account activity
- - other technical controls such as encryption and MFA with rotating keys that deflect the impact of compromise








