Many of Kong’s features rely on timers, such as caching, DNS, and health checks. Kong also runs some async tasks using the timer, such as the rate-limiting plugin, which connects to the database using the timer to make the request finish quickly.
As Kong’s user population grows, so does the complexity of the environment Kong faces. We’ve received some feedback from our customers about problems caused by too many pending/running timers. Even if we adjust the [lua_max_pending_timers](https://github.com/openresty/lua-nginx-module#lua_max_running_timers)lua_max_pending_timers and [lua_max_running_timers](https://github.com/openresty/lua-nginx-module#lua_max_pending_timers)lua_max_running_timers, it won’t fundamentally solve these issues.
The root of these issues is that Kong makes heavy use of timers, but OpenResty’s timers are not suitable for heavy use. So we’ve designed a scalable timer library to address these issues completely: lua-resty-timer-ng.
In this blog post, we’ll talk about why we have to design a scalable timer library and how this library works.
### Why design a scalable timer library?
First up, why do we have to design a scalable timer library?
In short, Kong makes heavy use of timers for some features. But as the customer’s environment gets more complex and configurable, OpenResty’s timer becomes one of the bottlenecks that consumes a lot of CPU and memory, and we have to solve this problem.
### How does OpenResty's timer work?
OpenResty’s timer uses Nginx’s timer to implement the timing functionality and a coroutine to execute the callback functions.
Nginx uses a red-black tree to manage all timers; finding and inserting a timer both cost O(logN) time. At the end of each event-loop of Nginx, Nginx looks for the minimum node from the red-black tree, checks to see if the corresponding timer has expired, and executes it if it has. It’s very efficient and doesn’t become a performance bottleneck with heavy use.
To execute the callback function, OpenResty creates a fake request and a coroutine.
Each fake request takes up a certain amount of memory and occupies a connection, just like a normal request.
OpenResty uses a linked list to manage all coroutines. With the number of coroutines increasing, it becomes more expensive to read/write the linked table.
### Where does OpenResty's timer falls short?
If we use OpenResty’s timer extensively, some issues are particularly prominent.
- - From the Nginx perspective, each timer is a request, because OpenResty creates a fake request for each timer. The more timers, the more requests, the more performance degrade.
- - There are many APIs that need to read/write this linked list of coroutines, it will take too much time if this list is too long.
- - There are very few statistics provided by OpenResty's timer, which is not conducive to failure analysis.
### How to make timer more scalable?
A direct thought would be to reduce the number of fake requests and coroutines used. It’s possible because it isn’t necessary to have a fake request for every timer. The execution contexts are independent of the execution environment. Also, coroutines can be reused if we carefully handle yielding.
To simplify the solution, we could reuse one single vanilla timer as a unit. Let’s call it a worker of our new timer. When a timer exits, the worker can then be used for the next to execute timer.
To deal with yielded timers, we yield from that worker and switch to another worker to run the next timer.
Instead of creating new workers every time we yield, we could allocate workers from a pool.
Taking the [http-log plugin](https://docs.konghq.com/hub/kong-inc/http-log/)http-log plugin as an example, at the end of each request, this plugin will start a timer to send the log to the log server.
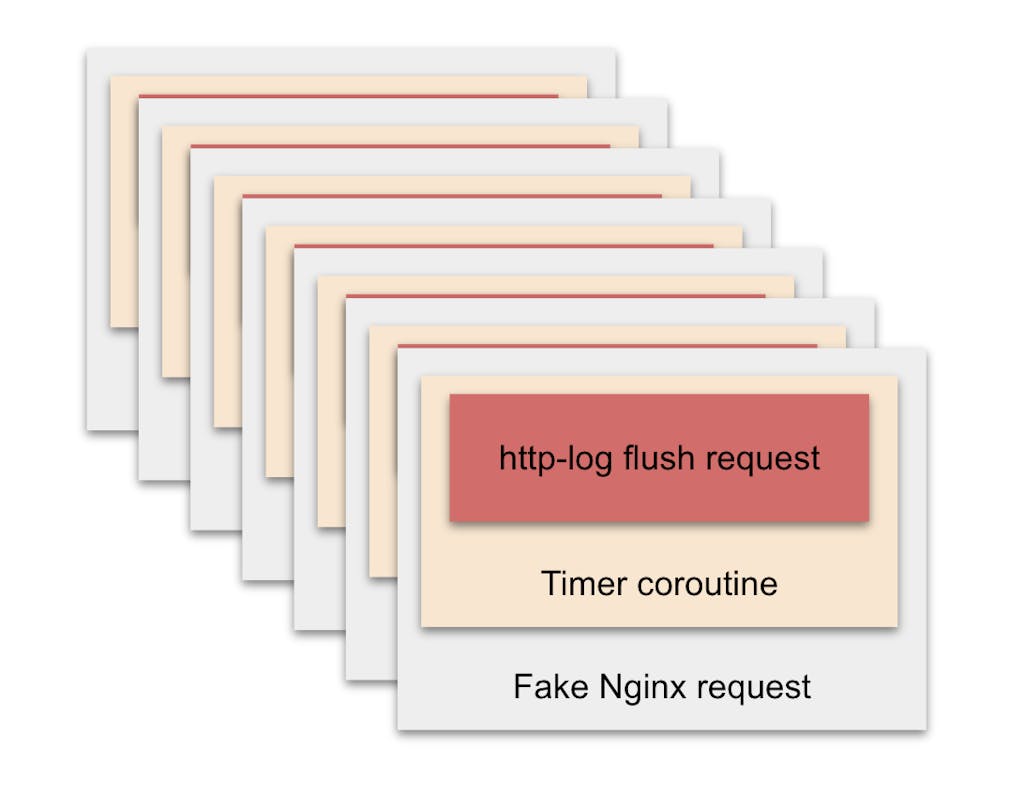
We create some timers early and store them in a pool, which is the timer pool. Once the timed task expires, we pick a timer from this timer pool to run the task. When the timer pool is empty, then we let the expired timer tasks queue. Essentially, a timer pool is a coroutine pool — the only difference being that the context of the coroutine in the timer pool is `ngx.timer`.
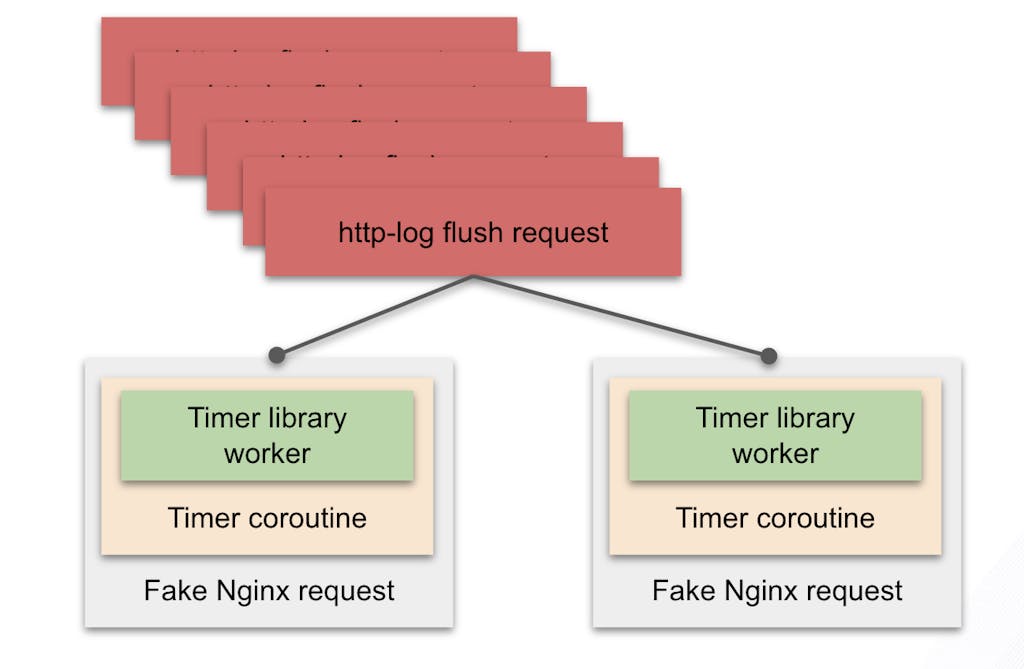
In this way, we reuse the fake request and coroutine.
As a result, even if we keep starting the timer, the number of fake requests and coroutines in the system will be relatively stable, which ensures that we don’t receive a big performance impact.
### lua-resty-timer-ng
lua-resty-timer-ng is the next generation of lua-resty-timer/OpenResty's timer. It’s a Lua library that builds a scalable timer system using the timer wheel algorithm and a timer pool. It can efficiently schedule 100,000 or more timers and consume less memory.
Let me explain how it reaches these goals.
### The timer wheel algorithm
First, we introduce what is the time wheel algorithm.
In brief, the algorithm uses an array to simulate a clock and an index to simulate the pointer of the clock.
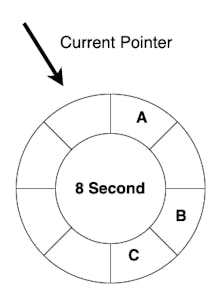
Take the above picture as an example.
At this point, there are three timed tasks on the wheel, A, B, and C. These three tasks are distributed in three slots.
We turn the pointer clockwise. At this point, there’s a timed task in the pointed slot (i.e., task A). We remove it from the slot and execute it. Similarly, when the pointed slot contains B, we should also remove it from the slot and execute it.
We can schedule all the timed tasks as long as we turn the pointer periodically.
### Reuse fake requests and coroutines
Then, we’ll see how to reuse fake requests and coroutines.
We start a number of OpenResty's timers in advance and put them into the pool. Then we start the scheduling loop, which continuously takes expired tasks from the queue and executes them.
This way, we create fake requests and coroutines less often and thus reduce CPU and memory usage.
### More statistics
Analyzing issues caused by timers is very difficult because OpenResty has few ways to help analyze such issues. Whenever we find related issues, it takes a lot of time to locate and analyze them.
[lua-resty-timer-ng](https://github.com/Kong/lua-resty-timer-ng)lua-resty-timer-ng also serves as a performance analytic tool. It collects statistics such as elapsed times, creating locations, etc. (Please see [Admin API – v3.0.x | Kong Docs](https://docs.konghq.com/gateway/latest/admin-api/#retrieve-runtime-debugging-info-of-kongs-timers)Admin API – v3.0.x | Kong Docs for more information.)
It even generates flame graphs with timer metrics. Check [this example](https://github.com/Kong/lua-resty-timer-ng#stats)this example. Based on the information provided, developers can more efficiently analyze the impact that timers have on the system.
We created several recurrent timers (interval is 0.1s) in the init_worker phase to test the performance of the new timer library on OpenResty.
For this benchmark, we set up two [c3.medium.x86](https://metal.equinix.com/product/servers/c3-medium/)c3.medium.x86 physical servers on Equinix Metal. These servers both have 1 x AMD EPYC 7402P 24-Core Processor with 48 threads.
For the load generation, we used the `wrk` benchmarking tool to access the path `/`, which is the default HTML for OpenResty.
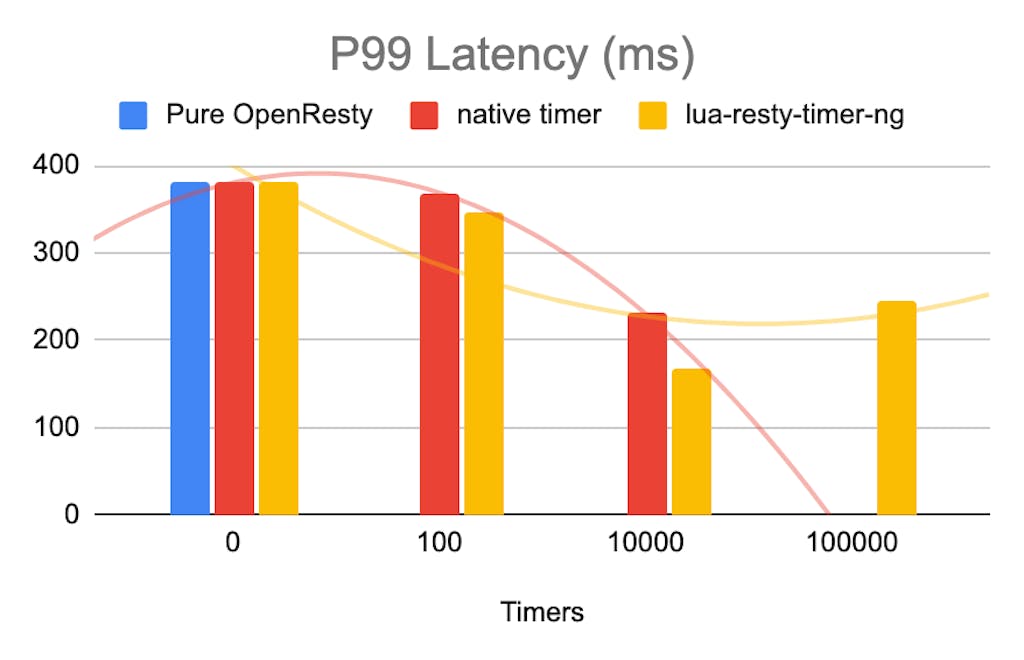
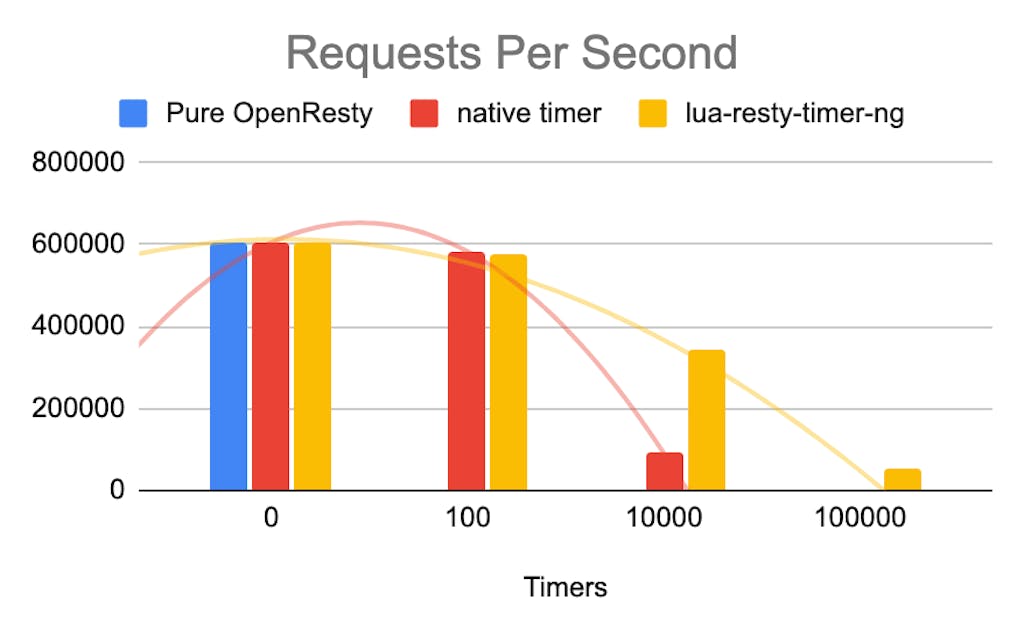
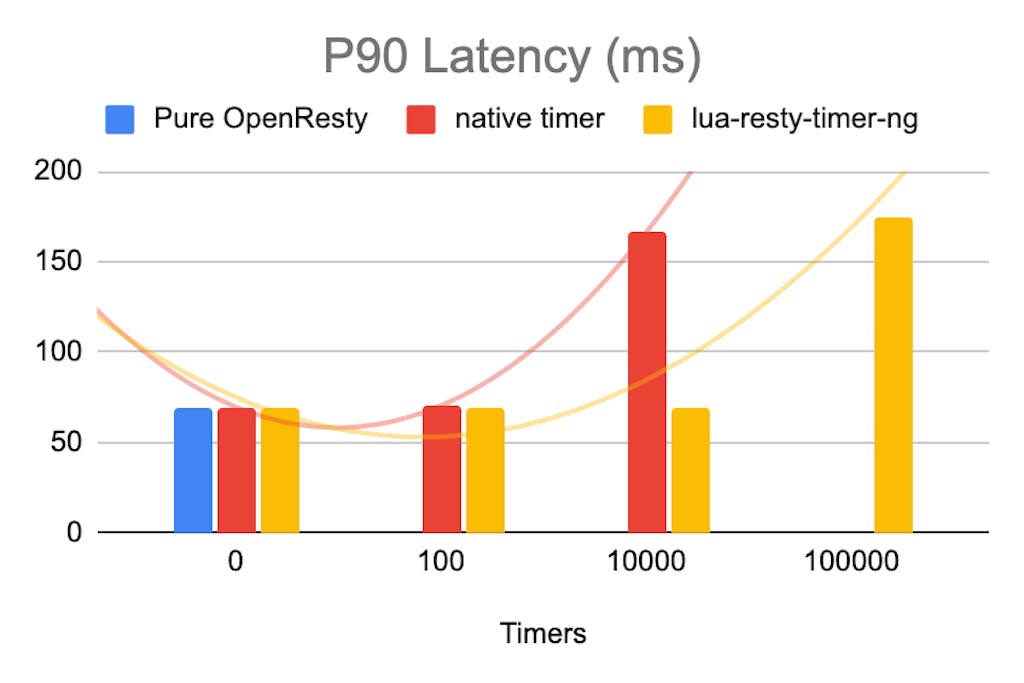
As you can see, when there are fewer timers, these two libraries are almost the same. As the timer increases, lua-resty-timer-ng suffers significantly less performance impact. lua-resty-timer-ng performs better in both RPS and latency.
## What's next?
Now, lua-resty-timer-ng has been integrated into [Kong Gateway 3.0](https://konghq.com/blog/kong-gateway-3-0)Kong Gateway 3.0, which will make Kong even more efficient.
With the statistics from [lua-resty-timer-ng](https://github.com/Kong/lua-resty-timer-ng)lua-resty-timer-ng, we can analyze the various issues caused by the timer more efficiently and make Kong more powerful. In the meantime, we’ll continue to improve lua-resty-timer-ng to make it better.
We welcome suggestions and code contributions for [lua-resty-timer-ng](https://github.com/Kong/lua-resty-timer-ng)lua-resty-timer-ng.








