The inner workings of an API gateway request can be difficult to understand because of its scale. To provide some orientation, we will use the real world as a reference, from planet-spanning infrastructure to a person eating a chocolate bar (processing a server response in a plugin).
This series will divide the abstraction space of how Kong Gateway processes requests into four different layers:
- - Infrastructure
- - Nodes
- - Phases
- - Plugins
##
## **1. Infrastructure**
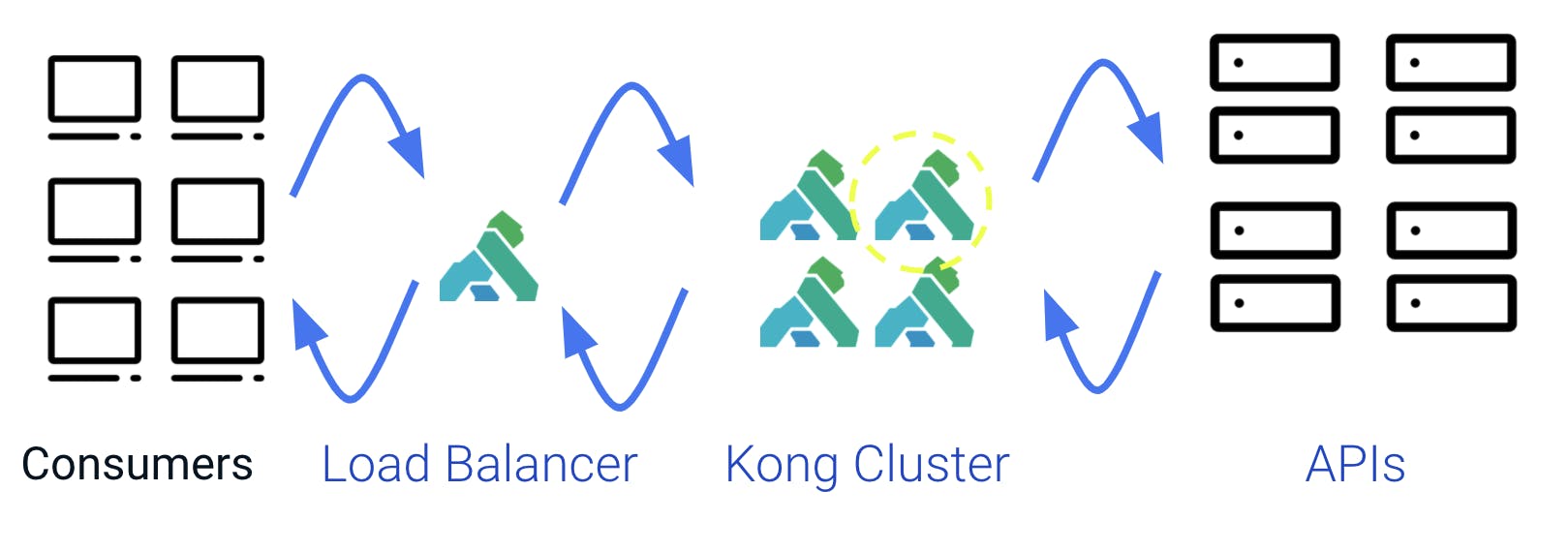
The following diagram shows a typical client-server setup in which the server is an API. In Kong, we call the client *consumer* and the server, a *service* or *upstream server*.
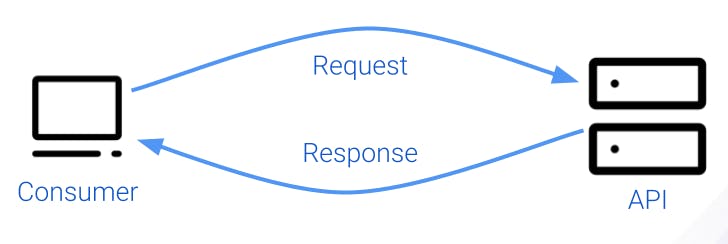
A connection such as this can literally span the whole world. Requests and responses routinely go over the Atlantic Ocean or all around the world every day.
### ***Reverse Proxy***
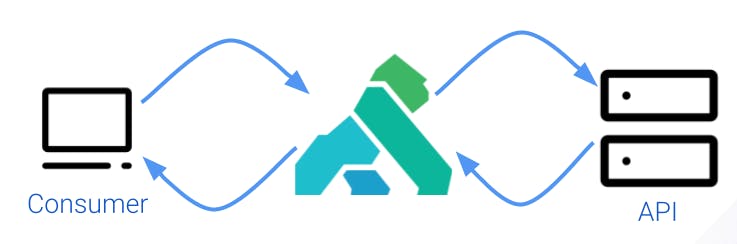
When Kong gets inserted between an API and a consumer, it acts as a reverse proxy. By default, Kong is transparent—it transmits requests and responses back and forth without modifying them. This figure explains how things work, but it’s far from complete.
### ***Multiple Consumers***
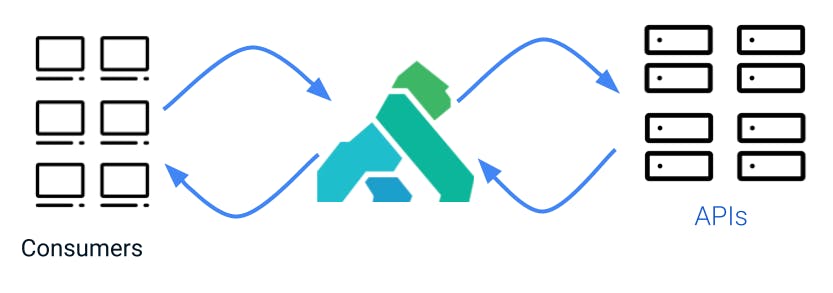
Usually, we have more than a single consumer using an API, and that's why we have a consumer entity in Kong.

### ***Multiple APIs***
Something similar happens on the right side—it’s common that Kong is used to manage more than a single API. The service entity in Kong differentiates between them.
### ***Multiple Nodes***
Even in the middle, that is not as simple on a real production system. It is not unusual to have multiple common nodes working together in a cluster. Before them, there is a load balancer, which is sometimes also a Kong node.
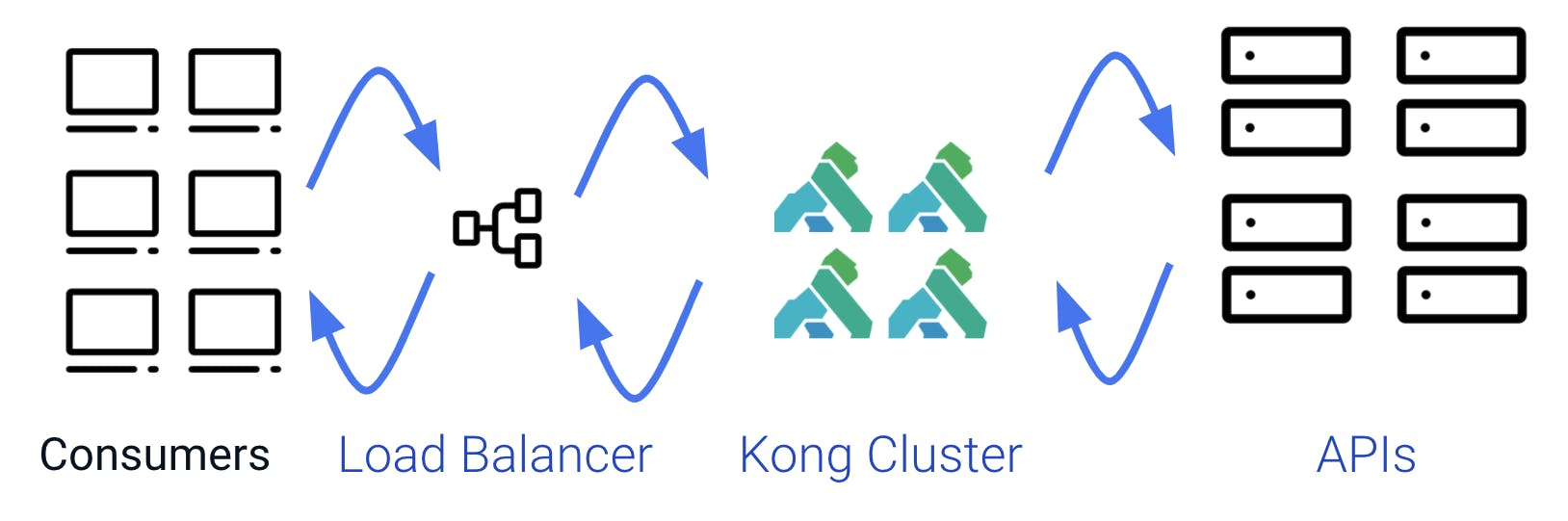
For the rest of this post, we will focus on a single Kong node in a cluster.
## **2. Node**
When we move down to the Kong node level, we are no longer on the planetary scale. A Kong node is like a country, and this country, in particular, is very concerned about efficiency, doing things as fast as possible with the least resources possible. So the way things got started was by looking at what was available, which was the operating system.
In a modern operating system, the largest unit of execution is called a process, which:
- - Is expensive to make
- - Is expensive to switch
- - Cannot share memory
Processes can, however, have child processes. A special instruction in the OS called fork ( ) makes a copy of the process and the memory.
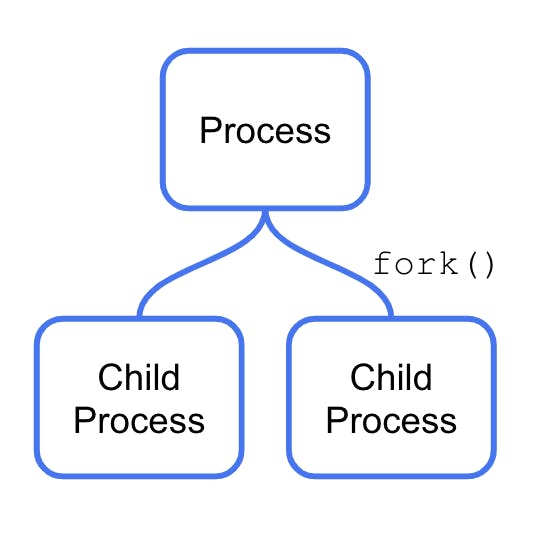
This is a way of sharing memory, but it’s unidirectional: The children cannot copy any of their memory “back” to their parents after being spawned. Forking is an expensive operation.
The next tool that the operative system gives us is threads. Threads are cheaper to create and switch over to than processes, but they’re still not free. One process can have many of them, and they can share memory. Still, they can also get blocked for various reasons: It can simply be waiting on an operation that takes time (like reading a file from the disk) or waiting for other threads to finish using a shared resource.
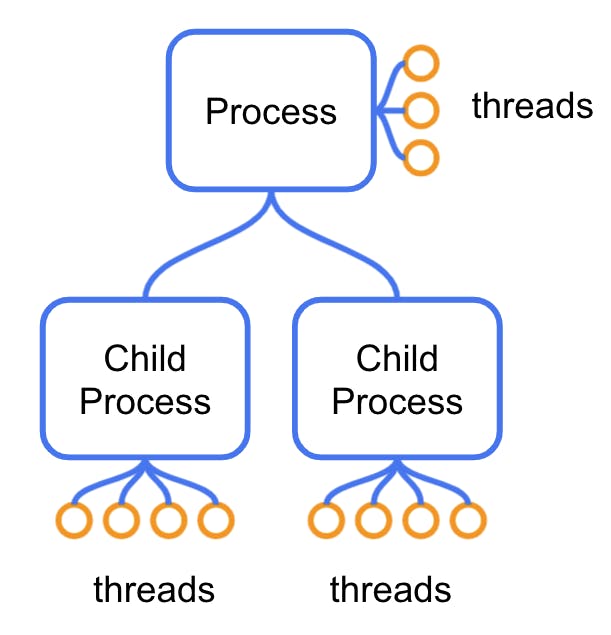
When a thread gets blocked, performance is lost. A single blocked thread is usually not a huge loss. When a lot of them get blocked, however, performance gets severely impacted. The extreme case occurs when the operative system decides to switch to a different process altogether.
How can we avoid both of them? Let's dive into that now.
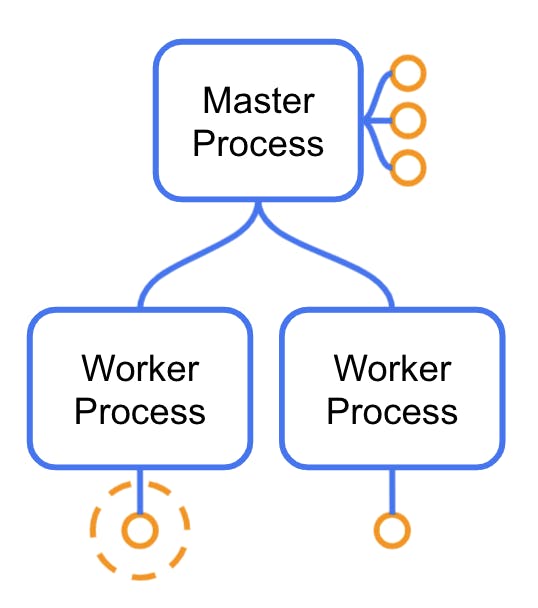
### ***In Kong: Master Process***
The initial (or “master”) process would be its capital city in the Kong Node country. Think Paris or London. The master process performs several critical tasks like loading the initial configuration and setting that initial memory layout that will then get copied to its workers (more on that in a second). That memory includes a Lua virtual machine.
But the master process’ most important job is to create and manage its child processes. These child processes are called workers. If one of them dies, the master process will “resurrect” it. Let's learn more about workers.
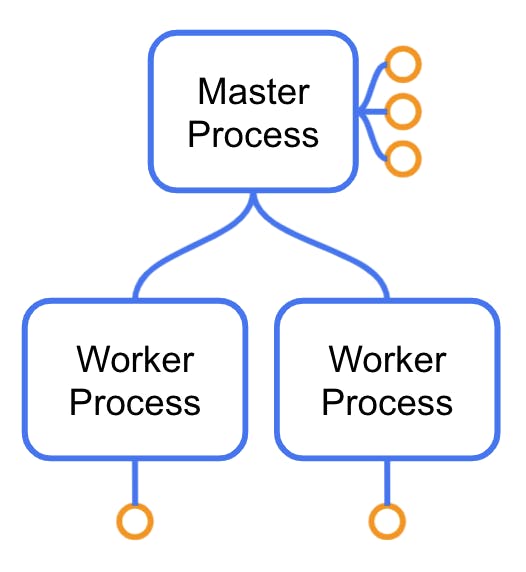
### ***In Kong: Worker Processes***
Since workers are child processes of the master process, they get a copy of its memory, including an already initialized Lua Virtual machine.
The worker's main purpose is transmitting and working with requests as efficiently as possible. To do this as efficiently as possible, they are *single-threaded*, but their thread never gets blocked. Here’s how that works: First, each worker manages several requests simultaneously, not just one. The places where a typical OS process usually blocks have been replaced by others that return immediately instead of blocking. For example, instead of using the OS-provided IO features, they use a *non-blocking IO *module. When processing a request requires reading a file, the read operation requests the file to the OS *and immediately returns the control to the worker thread.* The retrieval operation will take some time, and while it happens, the worker will deal with other requests on its internal list.
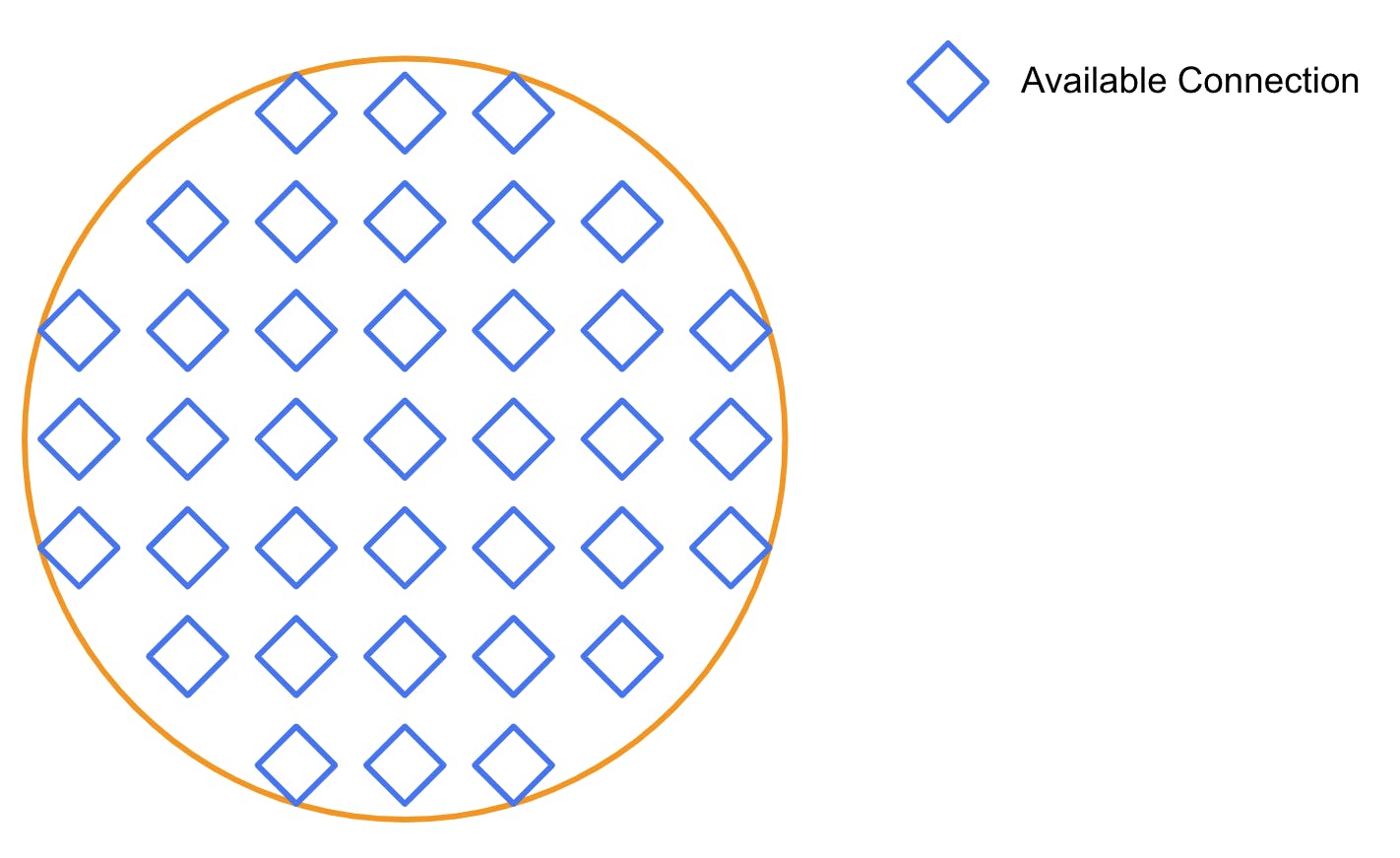
#### **Worker Threads**
If the Kong processes are similar to cities, a worker thread is similar to a city district or office building.
The diagram below represents a worker thread right after being created. By default, it’s “empty." As it works with requests, it will fill up with “connections." Each connection represents a request being treated by the worker.
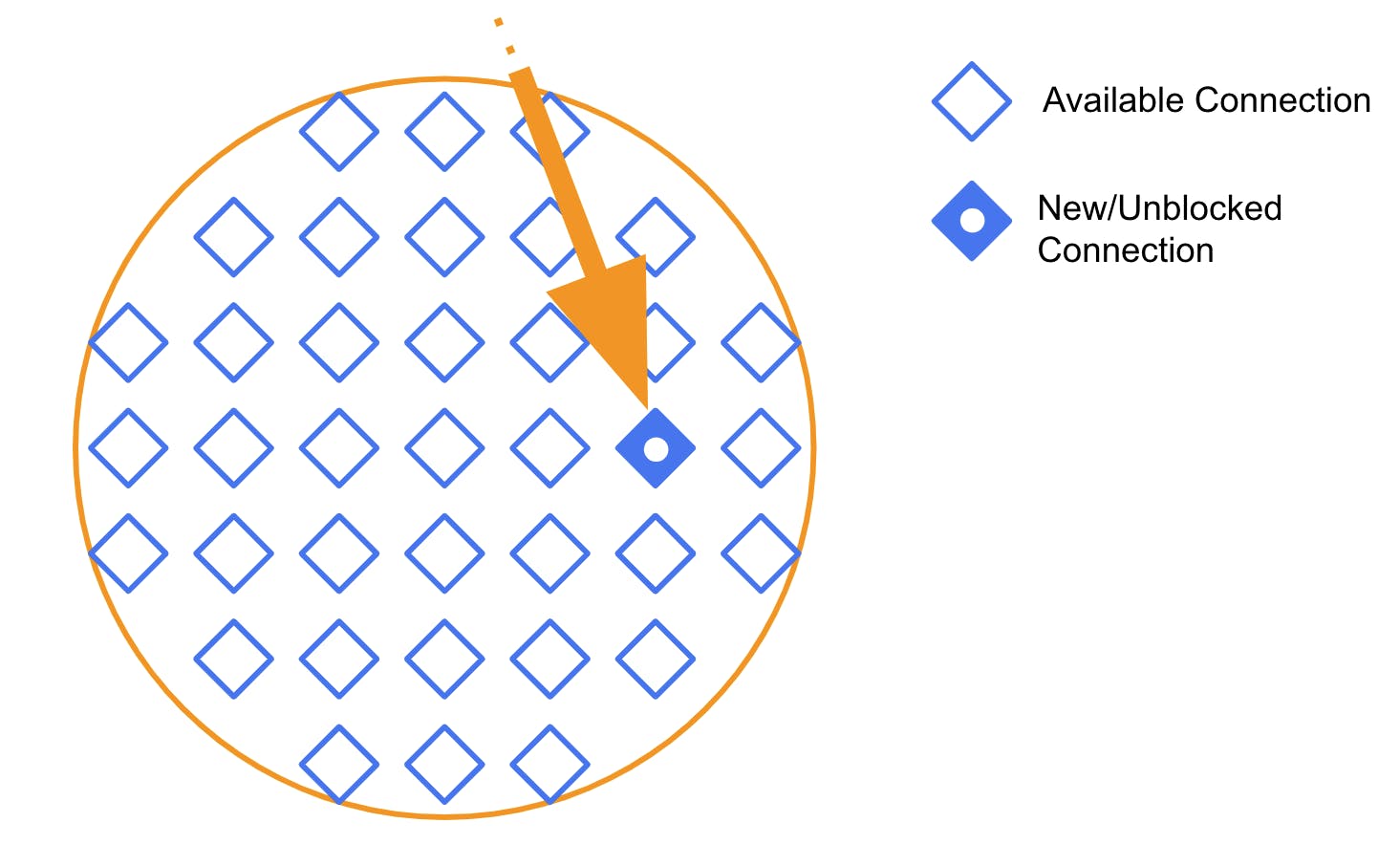
When a request arrives at Kong and gets directed to this thread, it gets assigned one of those available connections.
Then the worker starts processing the connection. That might involve any number of things - reading files, parsing headers, etc. We will represent the connection that the thread is actively working on in yellow.
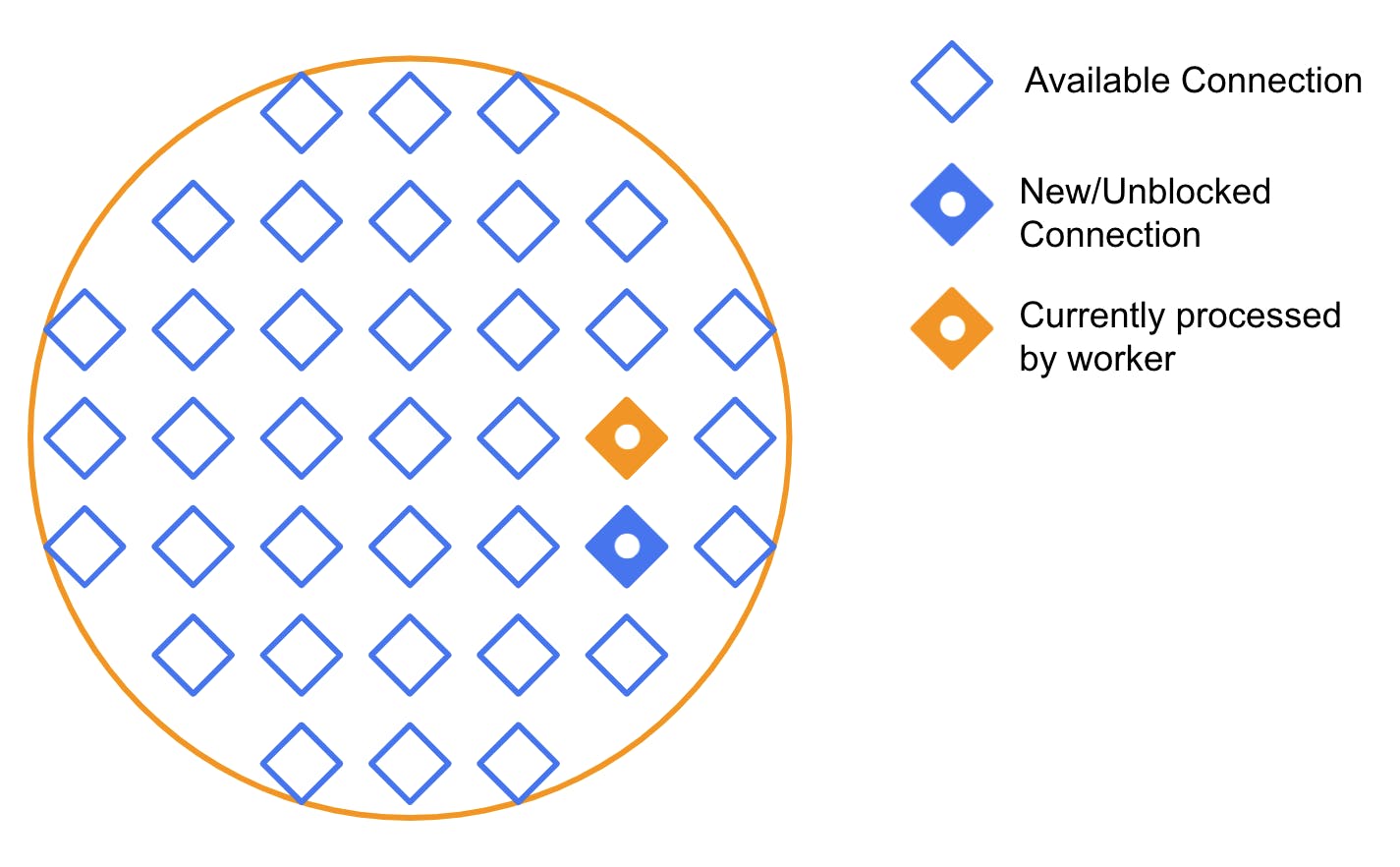
While processing, new requests come in and get put into a queue. The individual connections can get blocked, but the thread itself can continue processing other available connections. In the diagram below, the connection that the worker was processing eventually got blocked. But a new connection arrived, so the thread started processing it.
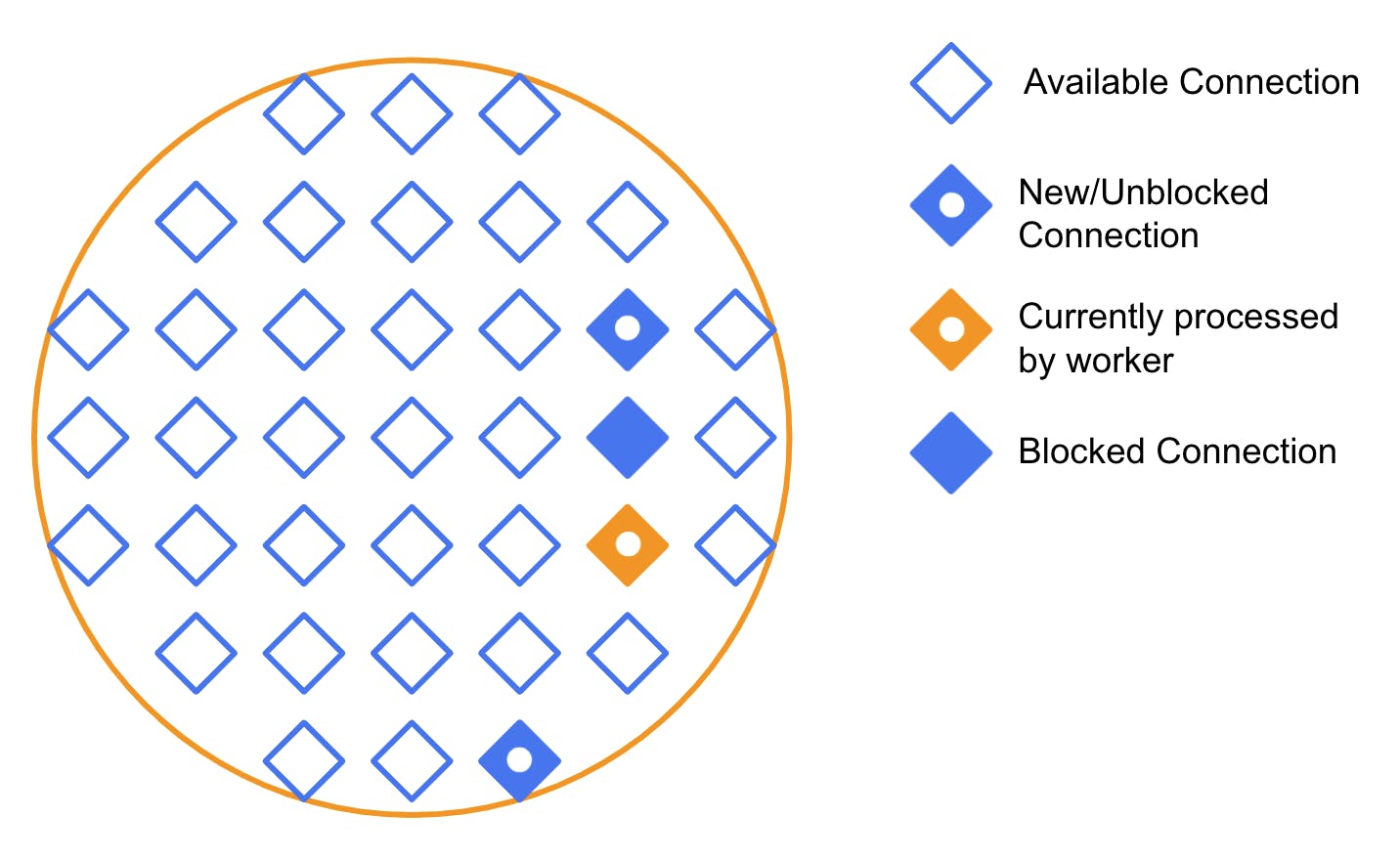
This process continues repeatedly. Eventually, we get into a situation where some connections are blocked and others are unblocked and pending treatment. Like this:
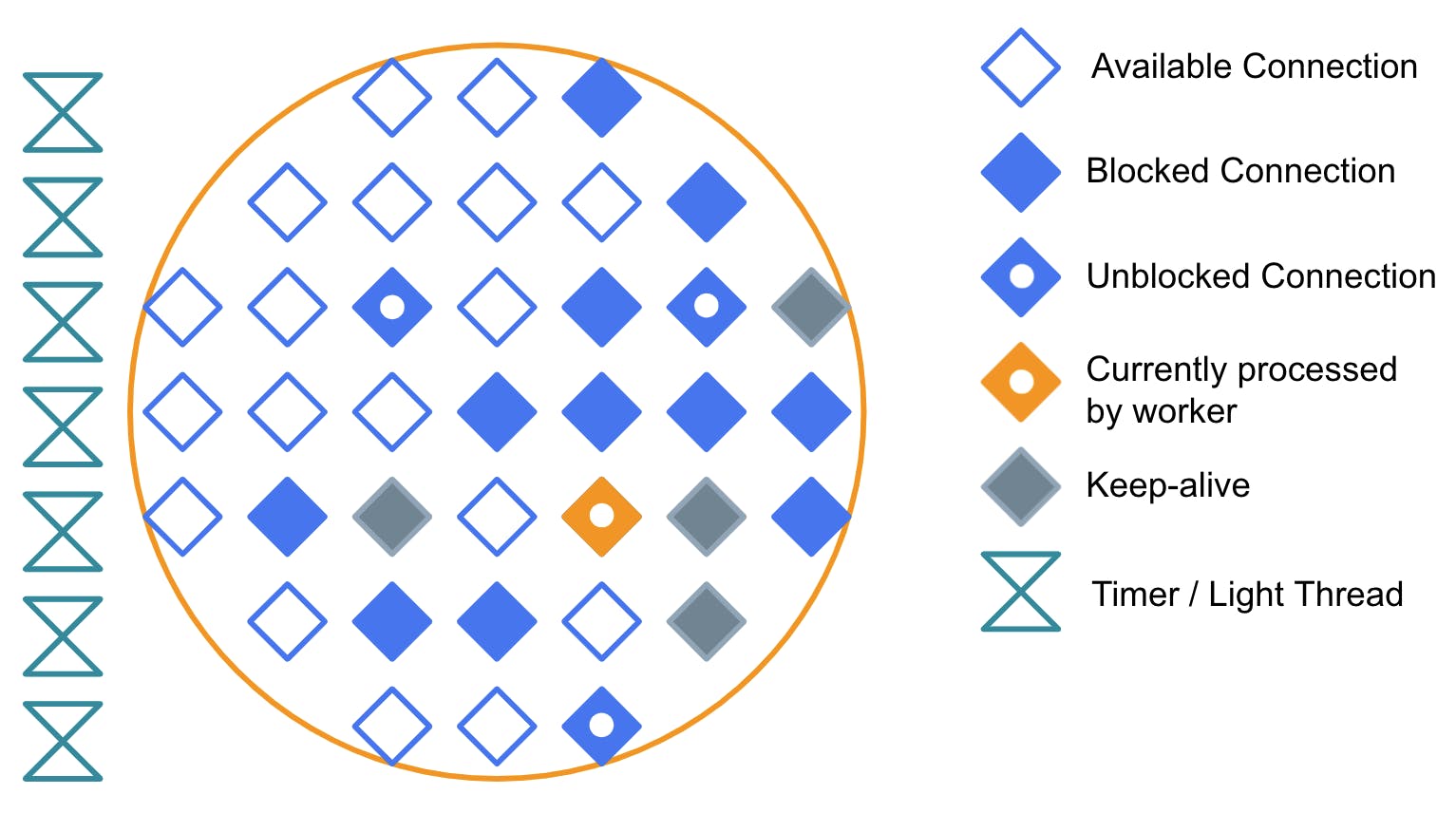
 **Keep-Alive**
**Keep-Alive**
One more wrinkle in this setup is Keep-Alive connections. TLS-protected connections require performing an “SSL handshake” between the upstream server and the consumer when they are first established. If the consumer wishes to avoid redoing the handshake every time it needs to talk with the upstream server, it can request a Keep-Alive connection. This means that the server “remembers” the handshake for a while, so it can be skipped while the server and the consumer exchange requests.
Since Kong acts as an intermediary between them, it also needs to keep track of these arrangements. It does so by “reserving” connections initiated with a Keep-Alive. If new requests arrive from the same consumer, that specific connection will answer. Otherwise, the connection remains unusable for the rest until it times out and gets liberated.
#### 
#### **Timer**
And there is yet another wrinkle on this setup, which is timers. Every worker has a list of timers, which are pieces of code that need to be executed on a schedule. Some of them are scheduled only one time in the future, and others are recurring, for example, every 10 seconds. The single worker thread must process them as soon as possible while it also continues processing requests.
#### **Timer Being Processed by the Worker**
So this is how it looks when the thread is executing one of those timers. Notice that when a timer is being executed, no connection is being processed. An excessive number of timers can impact the efficiency of a worker.
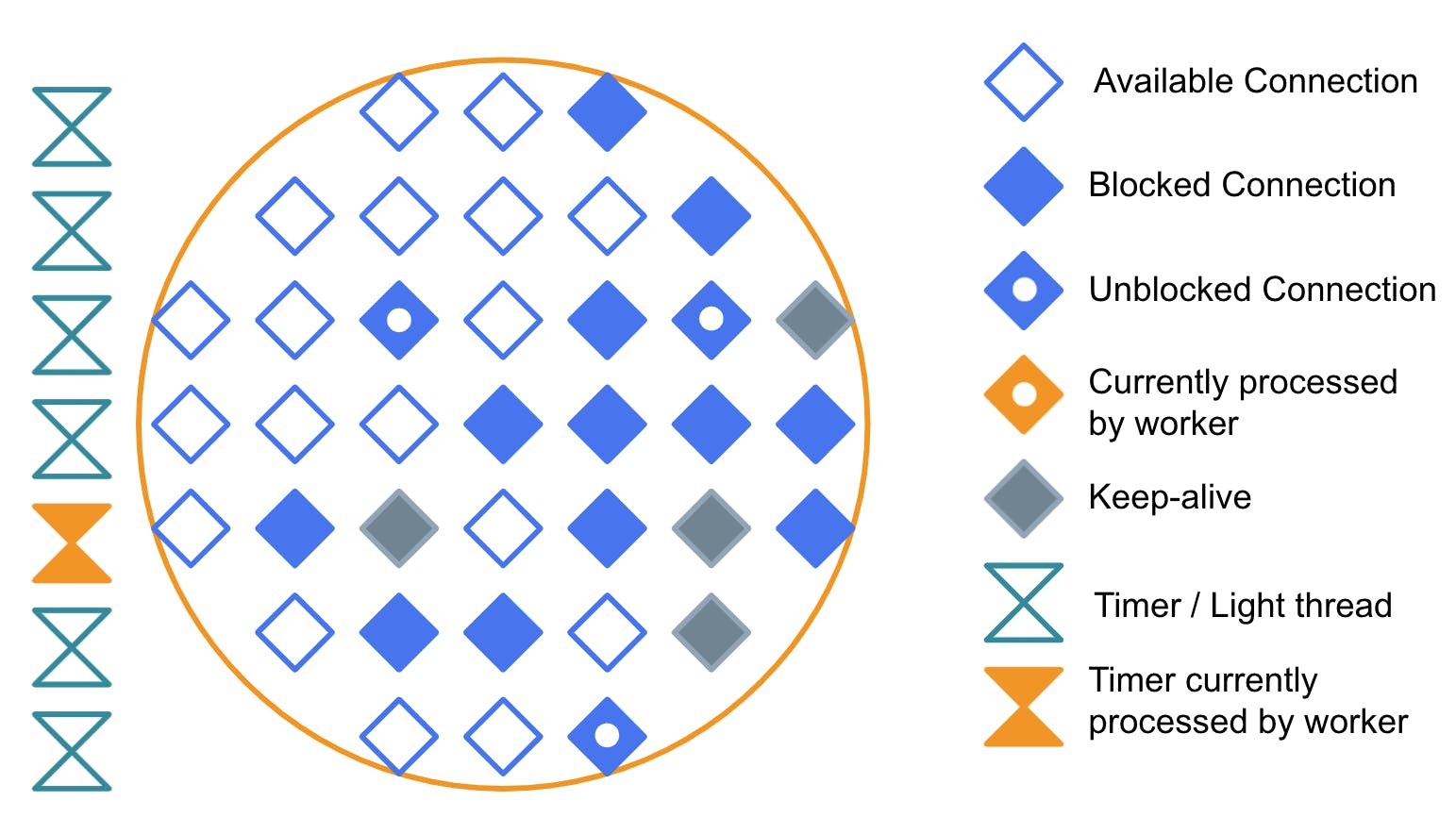
We used to have exactly this problem in a previous version of Kong. In some cases, we would create one timer per request when dealing with health checks. This increased the memory and CPU usage and reduced efficiency for some users.
## **Until Next Time…**
And that does it for that level. In the next post, we will talk about time, and then we’ll keep digging downwards in the abstraction layer.
**Have questions or want to stay in touch with the Kong community? Join us wherever you hang out:**
⭐ [Star us on GitHub](https://github.com/Kong/kong)Star us on GitHub
🐦 [Follow us on Twitter](https://twitter.com/thekonginc)Follow us on Twitter
🌎 [Join the Kong Community](https://konghq.com/community?utm_source=newsletter&utm_medium=email&utm_campaign=community)Join the Kong Community
🍻 [Join our Meetups](https://www.meetup.com/pro/kong)Join our Meetups
❓ ️[Ask and answer questions on Kong Nation](https://discuss.konghq.com)Ask and answer questions on Kong Nation
💯 [Apply to become a Kong Champion](https://konghq.com/kong-champions?utm_source=newsletter&utm_medium=email&utm_campaign=community)Apply to become a Kong Champion








