*Want to learn more about moving past the AI experimentation phase and into production-ready AI systems? Check out the upcoming webinar on how to *[*drive real AI value with state-of-the-art AI infrastructure*](https://konghq.com/events/webinars/state-of-the-art-ai-infrastructure)*drive real AI value with state-of-the-art AI infrastructure**.*
## RAG use cases across industries
According to the [2025 MIT Technology Review Insights Report](https://info.microsoft.com/ww-landing-customizing-generative-ai-top-techniques-for-unique-value.html)2025 MIT Technology Review Insights Report, two out of every three organizations surveyed are already using or exploring Retrieval-Augmented Generation (RAG) to enhance their AI systems. This approach is becoming mission-critical across industries where accurate information is non-negotiable.
In healthcare, RAG can help LLMs surface up-to-date clinical guidelines or patient records in a timely manner, which is critical when treatment decisions depend on the most current patient information. In the legal field, RAG can help lawyers instantly surface case law or compliance documents for their clients mid-consultation. And finally, in finance, where the markets are shifting by the minute, RAG can equip models to deliver better financial insights based on up-to-date data, and not obsolete snapshots.
In each of these cases, the ability to ground LLMs in real-world, domain-specific context is what turns LLMs into something truly useful and reliable.
Now that we understand the general value of RAG, let’s go a layer deeper and take a look at how it all works under the hood.
## How RAG works: Data preparation
RAG essentially comprises two main phases: 1) data preparation and 2) retrieval and generation.
The data preparation phase lays the foundation for RAG. It involves loading and processing unstructured data — like PDFs, websites, emails, or internal documentation — so that it can be efficiently retrieved later. This process begins with a document loader, which ingests content from various sources. Since unstructured data doesn’t follow a predefined format, it must first be broken down through a process called chunking, which splits documents into smaller, manageable pieces to make them easier to search and pass to the model.
Next, each chunk is converted into a vector embedding, which is a numerical representation of its semantic meaning. These embeddings allow the system to perform semantic search, which means it can find content based on the underlying intent and meaning, and not just keywords. The embeddings are then stored in a vector database for fast, similarity-based lookups, helping the system quickly find pieces of information that are most similar in meaning to the user’s question.
To visualize this process, imagine you’re building a vast library for the first time. You can’t just throw all the books on a shelf and call it a day. You need to organize them. First, you need to sort the books by their chapters and sections; that’s what we refer to as chunking. Then you can use embeddings to label each section with a detailed summary. Finally, you can log all of these summaries with a searchable catalog, which is the Vector DB.
## How RAG works: Retrieval and generation
Once the data is prepared and indexed, RAG enters its second phase: retrieval and generation (querying the data in real time). When a user submits a query, the system converts that query into an embedding using the same model that was used during the data preparation phase. It then performs a semantic similarity search against the vector database to find the most relevant content chunks that match the query.
Once the relevant chunks are retrieved, they're assembled into a custom prompt, which includes both the user’s question and the contextual information from the vector DB. This prompt is then passed to the LLM, which uses both the retrieved knowledge and its pre-trained capabilities to generate a final, contextually accurate response.
This phase is where the open-book exam analogy that we discussed earlier comes into play — rather than guessing from memory, the LLM paired with the RAG pipeline now has the ability to look up the information it needs in real time, which will dramatically reduce hallucinations and increase the accuracy of the AI output.
This diagram outlines the two phases of RAG clearly:

*The two main phases of RAG.*
## The challenges with RAG implementation today
Whether you’re using traditional RAG, agentic RAG, or another variation, implementing RAG comes with a common set of challenges. As we’ve discussed, the RAG process has two core phases: data preparation — ingesting and embedding unstructured data — and then querying the vector database to retrieve and associate relevant data with the prompt. It’s this second step (retrieving and appending context at query time) that often creates friction for teams.
Developers typically have to manually build logic to query the vector DB, fetch relevant data, and pass it to the LLM, an effort that’s time-consuming, error-prone, and difficult to standardize. This is a manual process that the Kong AI Gateway is now able to automate.
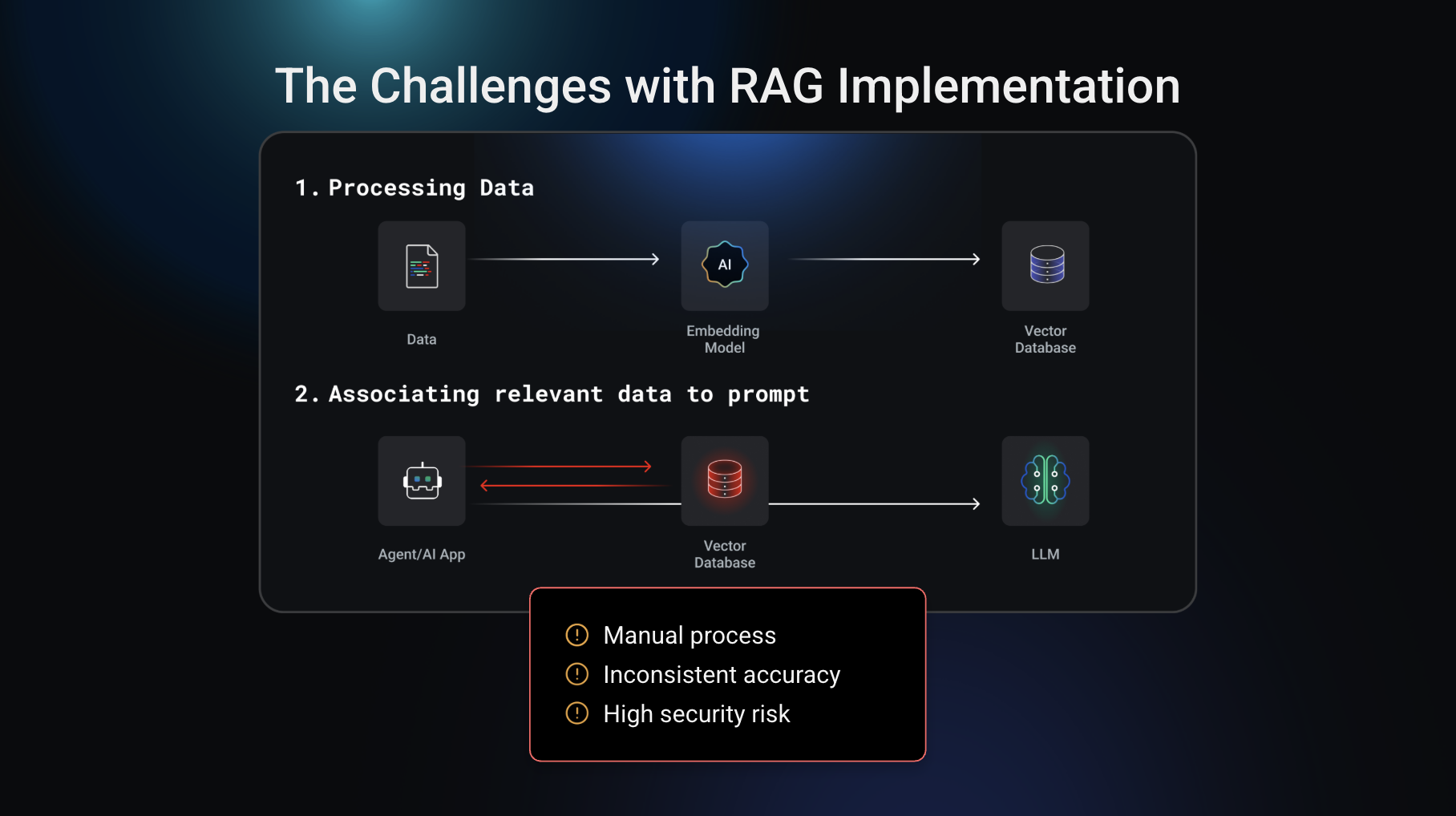
*The challenges associated with the second phase of RAG. *
## Streamline RAG implementation with the Kong AI Gateway
Kong AI Gateway takes the heavy lifting out of the RAG implementation process. By automatically generating embeddings for an incoming prompt, fetching all relevant data, and appending it to the request, Kong removes the need for developers to build this association themselves for each implementation of RAG.
Additionally, Kong makes it possible to operationalize RAG as a platform capability — shifting more of the RAG implementation responsibility away from the individual developers and enabling the platform owners to enforce global guardrails for RAG. This not only saves time and reduces the risk of errors, but also makes it much easier to roll out consistent changes and updates over time. From a governance perspective, it gives platform owners full control over how data is retrieved and used — ensuring better oversight and standardization.
Finally, as it relates to security, Kong AI Gateway will lock down access to your vector database, and remove the need to expose it to developer teams or AI agents. This provides a safer, simpler, and more scalable way to bring high-quality RAG into your organization.

*Implement automated RAG to reduce LLM hallucinations and ensure higher-quality responses.*
At the end of the day, automated RAG in the Kong AI Gateway will provide organizations with the ability to more effectively reduce LLM hallucinations and deliver higher-quality AI responses for the end-user.
Learn more about the Kong AI RAG Injector [here](https://docs.konghq.com/hub/kong-inc/ai-rag-injector/)here.
## Get started with Kong AI Gateway today
Winning with AI comes down to alignment, not just speed. [Reach out to our team](https://konghq.com/contact-sales)Reach out to our team to learn how we can help operationalize your AI strategy today.










