In the [last blog post](https://konghq.com/blog/automating-api-lifecycle-apiops)last blog post, we discussed the need for both speed and quality for your API delivery and how APIOps can help achieve both.
In this part of our blog post series, we'll walk through what the API lifecycle looks like when following APIOps. We're still following the best practice we've established in the industry over the years, but what you're going to see is that the processes we follow at each step of the API lifecycle - and between each step - have changed. We're now incorporating key parts of DevOps and [GitOps](https://www.weave.works/technologies/gitops)GitOps to bring modern automation and continuous testing to our API pipelines.
[ ](https://konghq.com/ebooks/apiops-devops-gitops-api-lifecycle)
](https://konghq.com/ebooks/apiops-devops-gitops-api-lifecycle)
## **Design**
At design time, we use a design environment like [Insomnia](https://insomnia.rest)Insomnia to easily create the API spec, which is typically a Swagger or OAS document. We also create a test suite for that spec. Here we should check for several things - do we get the responses we expect in certain conditions, does a response follow the expected format, etc.
What's critical here is that the tooling we use to create the spec and the tests gives us instant validation. That's linting of the spec against best practices, the ability to run those tests locally and validate what you're building. As the designer of the API, you need to have self-serve tooling that makes it easy to do the right thing from the beginning.
When you've created that spec and validated it locally, you then push it into Git - or whichever version control system you use - by raising a pull request for this new service.
## **Automated governance at design time**
This triggers a governance checkpoint embedded in our pipeline. Before any time is spent building the API, we need to be sure that what's going to be built follows our company standards and is aligned with everything else in the ecosystem. Using a CLI like [inso](https://github.com/Kong/insomnia/tree/develop/packages/insomnia-inso)inso, we automatically invoke the API tests built for the spec and any other governance checks we want to include at this stage of the pipeline.
This is an automated check, embedded in the pipeline and triggered by default when a spec is pushed into Git, which means there's 100% coverage of these checks for every API that's being designed, anywhere across the organization.
So we're now consistently and instantly catching any errors or deviations from our standards as close to the beginning of the pipeline as possible. This means they're much faster and cheaper to remediate, and we're reducing the number of issues that end up getting deployed into production.
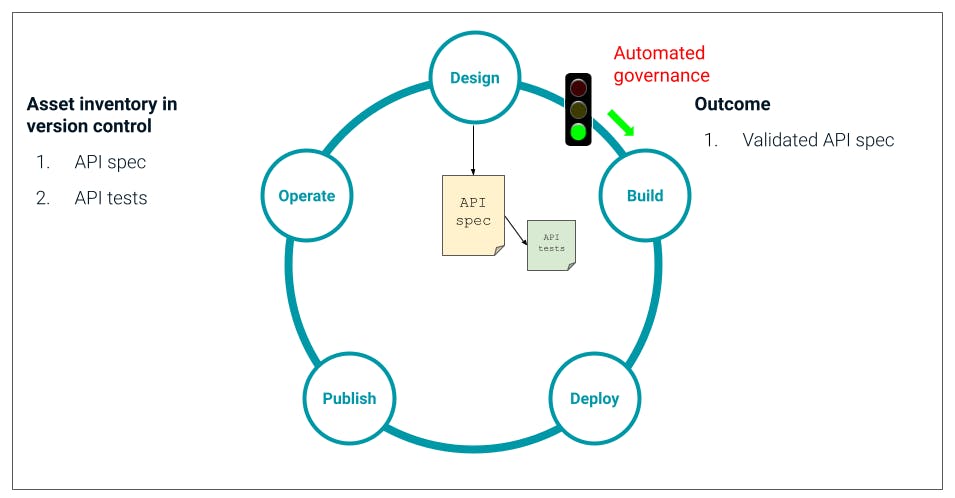
If the spec fails any of those tests, it gets automatically pushed back for more work in the design phase. If all the tests pass, then we have a validated spec and can now progress onto the build phase.
## **Build**
We build our API in the normal, best practice way: We use the spec as the contract to tell us what the API needs to do and what the interface needs to look like, and we use the tests as we go to validate that the API we're building meets the spec. Of course, you should be able to build this API in whatever tool or language is best for the use case, so long as it fulfills the spec.
### **Automated governance at build time**
As before, when the developer commits their code saying it's ready for deployment, a series of tests are triggered.
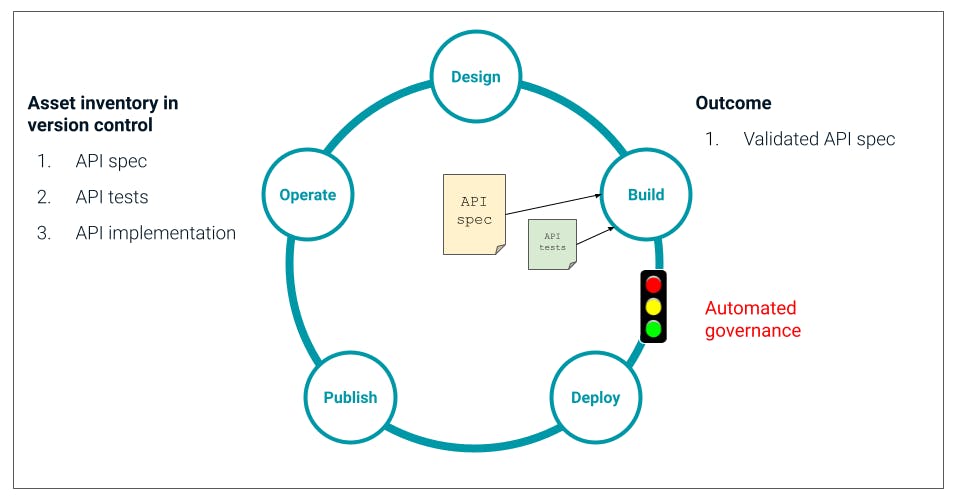
We automatically execute the API tests that we built at design time again to make sure the API still meets our best practice and that the interface that's been built is what was specified in the spec. These tests are actually our unit tests and will also make sure that the implementation of our API functions how it should. There may well be additional tests that we also want to carry out at this stage, still automatically.
If any of the tests fail, we know immediately. We do not deploy the API; we go back and make the necessary changes until our implementation is how we need it. And we can keep executing these tests for instant, continuous validation of what we're doing.
When those tests pass, we progress forward to deployment.
## **Deploy**
Now this is where we start to see more of a GitOps approach because when this round of automated tests has been passed, we then automatically generate a declarative configuration file for this API.
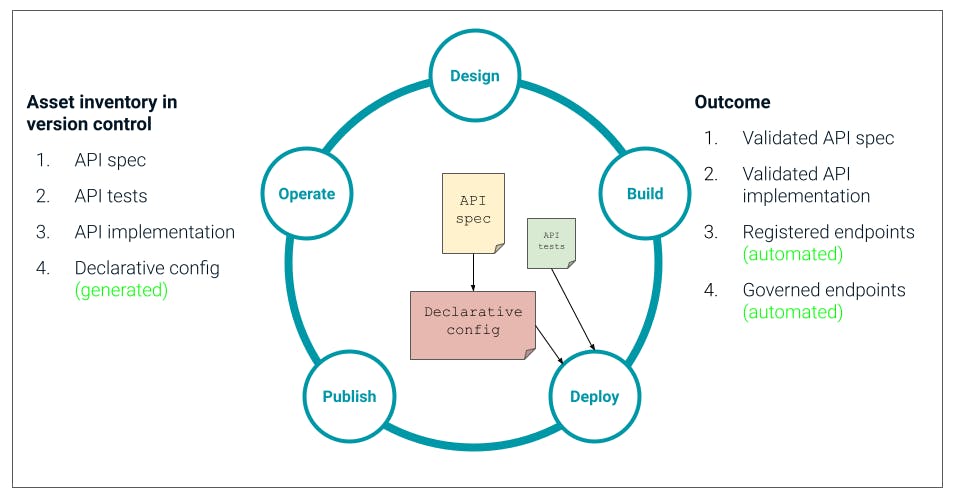
[(more…)](http://konghq-com.docksal.site/blog/enterprise/automating-api-lifecycle-apiops-part-2#more-33947)(more…)








