Deploying AI in Regulated Sectors: A 3-Layer Plan

How can AI be safely deployed in regulated industries?
With AI adoption, both startups and big enterprises have been streamlining their operations, and accelerating innovation securely. But for highly regulated spaces (like pharmaceuticals, financial services, and insurance) rolling out prod-ready AI is more complex and expensive.
However, AI holds just as much promise in these regulated sectors. Consider the benefits of accelerating drug discovery, enhancing fraud detection, improving risk modeling, and delivering more personalized services. But adoption remains surprisingly low, thanks to hurdles like strict compliance frameworks and the need to protect sensitive data and maintain operational integrity.
In this post, we'll outline a three-layer strategy designed specifically for regulated environments. You’ll learn how to:
- Identify high-value AI use cases
- Work within complex regulatory and compliance requirements
- Apply AI and LLM (large language model) governance to mitigate risk
- Scale responsibly while maintaining trust
Why is the pharmaceutical industry a prime candidate for AI disruption?
Pharmaceuticals may be the most poised for AI-driven transformation. AI promises to streamline Research and Development (R&D), accelerate clinical trials, and ship new drugs to market faster.
Companies like GSK are already leading the charge. By investing in AI and machine learning, GSK improved success rates in areas like personalized medicine.
For example, in the 2024 Medscape article AI’s Drug Revolution, Part 1, GSK was highlighted for their pioneering use of digital biological twins — AI-powered models that simulate how individual patients might respond to therapies.
“GSK and researchers at King’s College London have been using digital biological twins and AI to home in on personalized cancer treatments. If all goes well, their work could help improve the dismal 20% response rate to immunotherapy treatments...”
Beyond matching patients to therapies, GSK also envisions automating entire aspects of clinical trial design — such as participant recruitment and risk detection — as LLMs mature.
The pharmaceutical space is filled with similar opportunities for AI to cut costs, shorten development cycles, and ultimately improve patient outcomes. But the barriers to deploying and scaling AI are significant and often tied to regulatory compliance.
How can AI help reduce the cost and complexity of regulatory submissions?
According to PhRMA, developing and bringing a single drug to market takes an average of 10–15 years and $2.6 billion. Much of this cost stems from the documentation, compliance, and reporting demands of regulatory bodies.
The European Pharmaceutical Review reported in Cutting the Financial and Time Costs of Regulatory Affairs with Automation that major pharmaceutical firms may employ over 2,000 professionals to keep documentation up to date. And most of these systems are still manual, prone to human error, and inherently inefficient.
How can AI deliver immediate value?
- Error reduction: AI-in-the-loop checking helps detect inconsistencies and potential submission errors before they stall the approval process.
- Integrated data systems: AI can help unify data across siloed platforms, allowing for faster, more secure exchange of regulatory information.
- Automated safety scanning: AI and natural language processing (NLP) tools can monitor social media and public forums to surface emerging safety concerns early in the product lifecycle.
But perhaps the most impactful application of AI is in closing the “translational gap,” the discrepancy between how drugs perform in lab models versus human clinical trials.
“A lot can go wrong during clinical trials… it’s a crucial and costly problem known as the translational gap.” – Medscape
As GSK’s Kim Branson puts it: “When you test the animal model, it’s a coin flip to whether it works in humans.”
AI can help reduce that risk. Platforms like VeriSIM’s BIOiSIM simulate biological interactions at scale, evaluating efficacy and toxicity using vast data lakes of compound behavior, biological markers, and historical trial outcomes. What used to take months of wet-lab research can now be modeled in hours.
What data privacy challenges must be solved before AI can scale in regulated industries?
Data privacy is one of the biggest roadblocks to AI adoption. Highly sensitive information, such as protected health information (PHI) or personally identifiable information (PII), is governed by frameworks like the Health Insurance Portability and Accountability Act (HIPAA) and California Consumer Privacy Act (CCPA). Mishandling this data can lead to fines, breaches, or damaged brand reputation.
Here’s the paradox: AI needs data to be effective, but data in regulated industries must be tightly controlled.
This is where APIs come in. APIs act as the connective layer between data systems, AI models, and external applications. More importantly, they’re programmable interfaces — meaning you can build rules directly into how data moves.
For example, APIs can:
- Enforce access controls and data sanitization
- Obfuscate or redact sensitive values (like PHI or PII)
- Log every interaction for auditability
In essence, in regulated environments, having a well-designed API strategy is what separates scalable AI initiatives from failed experiments.
What does a prod-ready API strategy for AI look like?
As more organizations move beyond the “kicking the tires” phase of AI, a few critical questions emerge:
- How do we keep AI projects secure and compliant?
- How do we ensure resilience and availability without limiting access?
- What does production-ready AI actually look like?
These questions matter to everyone, but they're especially urgent in regulated environments.
The answer? It starts with your API strategy.
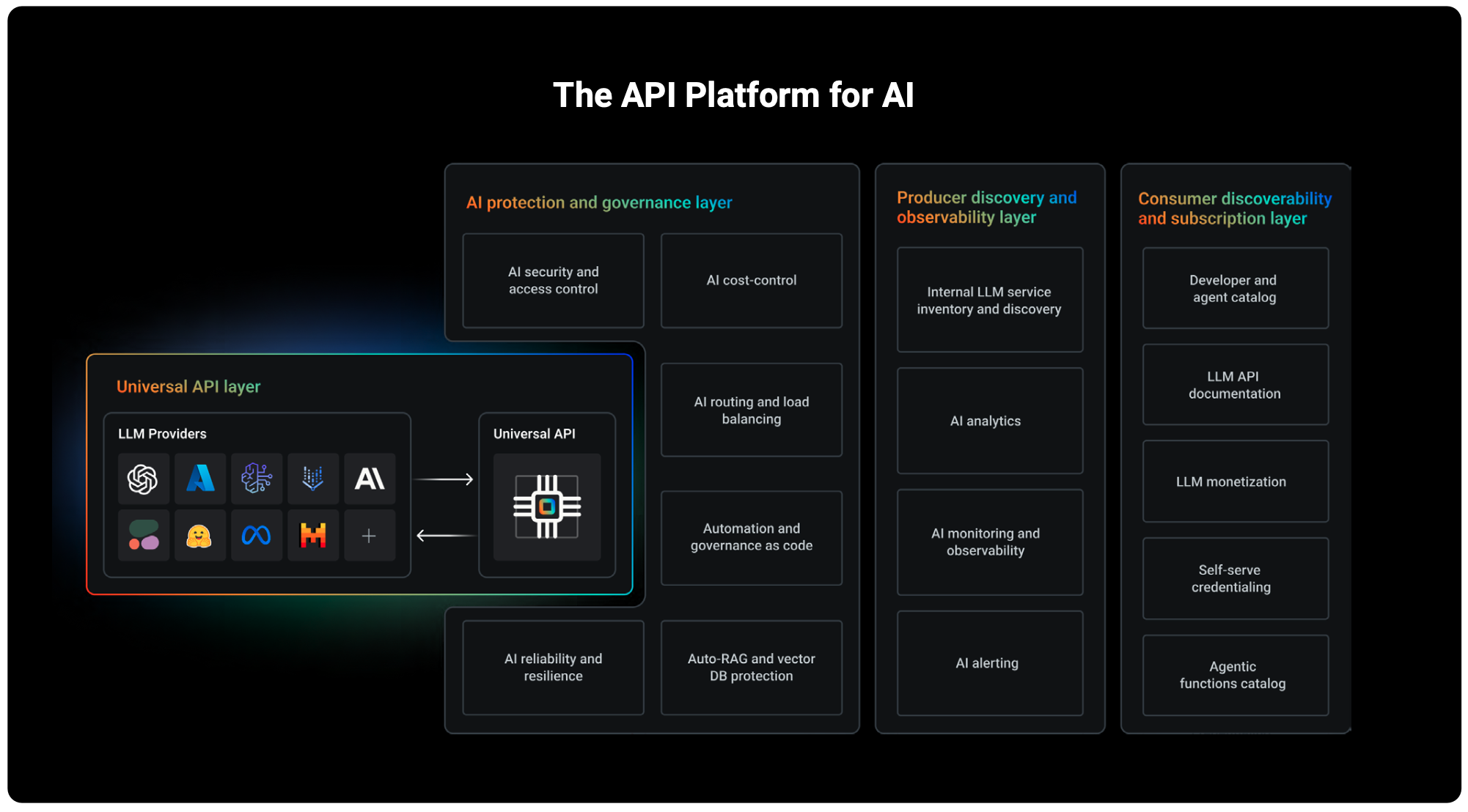
To build AI-native systems that are prod-ready, your API infrastructure needs to address three key areas:
- Universal access: Enabling multi-model access for developers, apps, and AI agents
- LLM and AI protection: Securing and scaling LLM access through APIs
- Discovery and consumption: Making LLM services easy to discover, use, and govern—self-serve and monetizable.
Let’s break each of these down next.
Layer 1: The universal API as the universal LLM access mechanism
LLMs and AI services aren’t valuable just because they exist. To drive real impact, especially in regulated industries, they must be easily accessible, ideally via self-serve. That includes not just humans, but also agents and automated workflows.
APIs are the ideal mechanism. They’re already the standard way to expose data, services, and functionality, so it’s no surprise most LLMs are offered via API.
But exposing models individually through separate APIs doesn’t scale. Why? Because modern AI strategies are multi-model. Leading orgs use many specialized models, each optimized for a specific task, like hiring domain experts for different roles.
Smaller, task-specific models can be up to 10x cheaper than general-purpose LLMs. But it creates a new challenge: developers now need to work with many APIs, each with different interfaces.
A universal API can solve this.
What is a universal API?
It’s a single abstraction layer across all your LLMs. Instead of integrating with each model individually, developers use one consistent interface. The platform handles model selection, routing, and orchestration behind the scenes. This minimizes integration complexity and makes it easier to build multi-model apps.
But what about risk and compliance?
Risk and compliance are key concerns — especially in regulated spaces. What if some models process sensitive data like PHI or financial transactions? If developers only see one unified interface, how can they know which models are safe? How does the organization ensure compliance?
That’s why a universal API alone isn’t enough.
It must be part of a broader platform that includes:
- Fine-grained auth and access control
- Policy enforcement at the model level
- Audit logging for full traceability
- Smart routing based on compliance rules
The universal API is just the first layer. It simplifies access, but it must be backed by governance and control to ensure secure, responsible AI adoption in regulated environments.
Layer 2: AI and LLM protection
When regulated industries expose a universal API to access LLMs, whether internally or externally, they need security, reliability, cost control, and governance baked into the architecture from the start.
Below are Kong’s recommended best practices across the four key protection categories.
1. Ensure secure access to LLMs in a regulated environment
Security is paramount when you’re working with LLMs, especially if there’s sensitive data, like PII, involved. Here's how to lock down your universal LLM API:
- AI gateway: Expose your universal LLM API through an AI-aware gateway. It should be preconfigured with built-in AI-specific security logic and policies.
- Authorization policies: Control access using OAuth, API keys, or enterprise authentication methods tailored to your environment. Only the right users and agents should be able to interact with specific models.
- Prompt guardrails: Add hard-coded restrictions to block unsafe or non-compliant prompts. Use semantic guardrails — rules that interpret natural language to catch edge cases and policy violations.
- Prompt decoration: Ensure outgoing prompts are rewritten or enriched to meet business rules, regardless of what the original request contained.
- PII sanitization: Automatically scrub sensitive information from prompts and responses before they reach the LLM or return to users. This helps prevent PII from ever being exposed, especially in cloud environments.
- Request and response transformation: Insert intermediate logic or models that adapt inputs and outputs to meet security, compliance, or formatting requirements specific to your organization.
2. Ensure reliable LLM performance at scale
With universal access comes high traffic, especially when AI agents and applications are making requests in real time. Here's how to keep things fast, available, and stable:
- Rate limiting & quotas: Protect backend systems and manage fairness by enforcing usage limits per user, app, team, or use case.
- Dynamic load balancing: Distribute incoming traffic across multiple LLMs or servers to avoid overloads, minimize downtime, and keep things running smoothly.
- Specific and semantic prompt guards: Guardrails improve security and prevent malformed or overly complex prompts from degrading performance or crashing a model.
- Dynamic & semantic routing: Don’t send every request to the same model. Use context-aware routing to direct each prompt to the most appropriate model — reducing unnecessary load and boosting performance.
- Semantic caching: Cache responses to repeated or similar prompts using semantic matching. This reduces redundant token usage and lowers response times for common requests.
3. Keep LLM costs under control as usage grows
LLM costs scale with usage, especially token-heavy models used in research, summarization, or multi-turn conversations. Without guardrails, spend can spiral. Here’s how to control costs:
- Use rate limits and quotas strategically: The same tools that help with reliability can also cap unnecessary or unauthorized usage.
- Route to cost-efficient models: Send simpler tasks to smaller, cheaper models instead of using your most powerful (and expensive) LLM for everything.
- Apply semantic caching aggressively: Avoid repeat token costs by caching and reusing previous responses wherever possible.
- Transform prompts for efficiency: Use prompt optimizers or intermediary services to shorten, simplify, or rephrase prompts — reducing token consumption while preserving intent.
Layer 3: Discovery and consumption
The discovery and consumption layer is split into two parts:
- Producer discovery & governance: How can teams responsible for AI services keep track of everything — from discovery and inventory to performance and usage—across the full LLM lifecycle?
- Consumer discovery & access: How do developers, AI agents, and customers discover and use those services safely and efficiently?
In regulated industries, get the producer side right before opening up consumption. You need visibility and control over what’s being built, especially if those services process sensitive data.
1. How can you help platform teams discover, govern, and manage LLM APIs?
Start by putting the right processes, visibility, and automation in place for the teams building or managing LLM services.
Best practices for producer-side discovery and governance:
- Lock in best practices early: Before teams start building AI features, align with org-wide standards for security, observability, access control, etc. Once things are in prod, it’s much harder to go back and retrofit governance.
- Use a single service catalog for APIs and LLMs: Developers are already familiar with API catalogs. Don’t create silos. Bring LLM APIs into the same discovery experience to simplify platform visibility and developer onboarding.
- Automate API discovery with APIOps: Use automated tooling to continuously scan for new LLM APIs under your gateway or platform. This prevents “ghost” services that run without oversight.
- Score your LLM APIs: Attach automated scorecards to each API that show how well it complies with org policies — like token limits, security posture, uptime, and more. Make those scores visible in the service catalog.
- Enable observability from day one: Before anything hits production, set up dashboards that give platform, security, and governance teams real-time visibility into usage, errors, response times, and risks.
- Establish service ownership: Every LLM service should have a clearly defined owner. When something goes wrong — whether it’s a security incident or outage — teams need to know who’s responsible.
2. How can you help developers and agents discover and consume LLM services?
Once the producer layer is in place, you can start enabling consumption—by humans, systems, and increasingly, AI agents.
Best practices for consumer-side discovery and access:
- Identify your primary users: Are your top consumers internal developers? Customers? AI agents? Tailor your catalog experience, documentation, and access flows based on those personas. Internal developers may need more detailed docs than an external partner would.
- Plan for non-human consumers: Gartner predicts that by 2028, 50% of all API calls will be made by non-human actors. Your LLM APIs should be ready to serve both developers and agents — because to agents, APIs are fuel.
- Unify your API catalog: Publish LLM APIs right alongside traditional APIs in your developer portal. Don’t create a separate portal for AI — it fragments the experience. Let consumers discover and subscribe to all APIs in one place.
- Enable self-serve access to credentials: Regulation-heavy sectors must control who can access what — but make it simple for the right users to request and receive access. Build credential workflows directly into your catalog or portal.
3. How can you optimize LLM discovery and usage to cut costs?
Beyond discoverability, your platform should help manage LLM consumption efficiently, especially since token usage directly translates to cost.
Proven techniques to reduce token usage:
- Token-based rate limiting: Don’t just limit by request volume, limit by token consumption. This is especially useful for high-usage models like research LLMs that burn through tokens quickly.
- Semantic routing & load balancing: Route prompts to the most cost-effective and capable model based on context. For example, route short prompts to a lightweight model and longer research prompts to a bigger one.
- Semantic caching: Cache and reuse responses for similar or repeated prompts. This not only speeds up response times but also saves on unnecessary token spend.
For regulated environments, is a unified platform better than stitching together tools?
By now, it’s clear that implementing all three layers of an enterprise-ready API strategy for AI — access, protection, and discovery — requires a range of tools and best practices. Whether you build those in-house or bring in external solutions, you’ll need infrastructure to support them.
So how should teams in regulated industries approach this?
While every organization and use case is unique, the general guidance is simple: prioritize consistency, especially in areas like security, reliability, and resilience, where mistakes can lead to serious financial penalties and damage to your brand.
Yes, it’s technically possible to achieve consistency with separate tools, but doing so comes with real challenges:
- You’ll need to build custom governance and visibility layers around each tool.
- Your CI/CD pipelines will become more complex, since they’ll need to integrate with multiple systems—often requiring different automation frameworks.
- You’ll likely face higher costs from managing multiple vendors or maintaining different in-house solutions.
If your goals include governance, cost control, and platform-wide consistency, a unified platform is the better approach.
The good news is a unified platform already exists: Kong Konnect.
Kong offers the world’s only full-lifecycle API platform designed to support AI use cases in regulated environments — bringing access, protection, and discovery together in one place.
How does Kong help deploy AI in regulated environments?
Kong Konnect is a unified full-lifecycle API solution designed for modern, AI-driven architectures. Whether you’re building for pharma, finance, or any other regulated domain, Kong Konnect helps you deploy prod-ready AI responsibly, securely and at scale.
Kong Konnect's key capabilities include:
- Universal API layer for OpenAI, Anthropic, Google, AWS Bedrock, Mistral, and more
- Producer tools for observability, service discovery, and scorecards
- Built-in security features like prompt guards, PII redaction, and vector DB protection
- Developer enablement with unified portals, self-serve workflows, and monetization options.
Whether you're exposing AI services to internal teams or external partners, Kong ensures that every touchpoint is secure, compliant, and scalable.
Download the Rolling Out AI Projects in Highly Regulated Environments eBook for a deeper dive into what it takes to successfully roll out production-ready AI projects in regulation-heavy sectors.
Unleash the power of APIs with Kong Konnect
