Prometheus and Grafana APM on Kubernetes Ingress

While monitoring is an important part of any robust application deployment, it can also seem overwhelming to get a full application performance monitoring (APM) stack deployed. In this post, we'll see how operating a Kubernetes environment using the open-source Kong Ingress Controller can simplify this seemingly daunting task! You’ll learn how to use Prometheus and Grafana on Kubernetes Ingress to simplify APM setup.
The APM stack we're going to deploy will be based on Prometheus and Grafana, and it'll make use of Kong's Grafana dashboard. Together, the solution will give us access to many important system details about Kong and the services connected to it—right out of the box. We'll simulate traffic going through the deployed stack and then observe the impact of that traffic using our monitoring tools.
It's important to note that this implementation will be more of a demonstration than an instruction manual on deploying to a production environment. We're going to use kind to create our Kubernetes cluster, making it easy to follow along on your local machine. From here, you'll have a foundation that will translate easily to your production-ready business applications.
Getting Going With a Kubernetes Cluster on kind
Since we're using kind, there are only a few things we need to get started. Follow the installation instructions for your platform. We'll also use the kubectl command-line tool and Helm, so make sure you have up-to-date versions of all tools to follow along.
First, we'll create a named Kubernetes cluster:
Installing Prometheus and Grafana
Now, we're ready to get our monitoring stack deployed. It may seem a little strange to start with the monitoring rather than our Kubernetes service. Still, this way, we will know immediately if Kong is connected properly to Prometheus and Grafana. We'll start by adding repos for Prometheus and Grafana:
If you've already installed these repositories, just make sure to run helm repo update to ensure you have up-to-date Helm charts.
We'll start with Prometheus configuration. The first step is to configure the scrape interval for Prometheus. We want our system to check for metrics every 10 seconds. We can do that with the following YAML:
Put that file in your working directory, and let's get helming!
That should display a message saying, "For more information on running Prometheus, visit: https://prometheus.io/." Notice that we created a new namespace for cluster monitoring. This will allow us to keep things clean in our K8s cluster.
While our Prometheus installation is configuring, we'll set up Grafana as well. Let's start with this YAML:
A lot is going on in this configuration file, but the comments should give a sufficient explanation. Essentially, when Grafana starts up, we want the Prometheus connection and the Kong dashboard already set up, too, rather than having to go through those steps manually. This file gets us that setup.
The Helm command is very similar to the one for Prometheus:
After running this command, you'll see instructions for getting the admin password for your installation. We'll come back to that soon.
Installing and Configuring Kong Gateway
Now that our monitoring stack is getting going, we can configure Kong to do the heavy lifting in our application. First, we'll make sure to add the Kong Helm chart repo:
You'll also need to create a YAML for the annotations we want to add to our Kong pod:
With the YAML in place, let's get Kong installed via Helm:
Once you've gotten that kicked off, create the following YAML file to connect Kong and Prometheus:
Apply that configuration with kubectl:
Final Server Configuration
With our stack fully built out in our kind cluster, we need to see what would happen if we used this sort of stack in production. In particular, we need to set up access to these services from a browser. We'll do that with a few port forwarding rules. In a new terminal session, we use kubectl to look up each piece we've created so far. Then, we set up a rule to visit each service as a localhost application in our browser of choice.
Without closing the terminal session, you should now be able to access different services based on the port:
- localhost:9090 for your Prometheus installation
- localhost:3000 for your Grafana installation
- localhost:8000 for your Kong installation
One thing you'll notice is the login screen for Grafana, where you'll need a password. To obtain that password, use the following command in your original terminal session:
This should give you a 40-character alphanumeric password that you can copy and paste into your browser at http://localhost:3000/login as the password, using "admin" as the username. If things are going according to plan, you'll be able to click on the "Kong (official)" Grafana dashboard link and see the Grafana UI:
If your dashboard doesn't say "No data" all over the place, you're in good shape. Otherwise, you might want to review the above steps again to ensure that everything is configured correctly.
Let's Demo This Dashboard!
Finally, let's get our ingress point set up and expose a few sample services. If you were really trying to use this monitoring stack, this is where the deployment of your application would go. For now, we're going to make a few dummy services with the following endpoints:
- /billing
- /invoice
- /comments
We'll use httpbin, which will allow us to simulate a fully functioning service with response codes as we ask for them. We're doing this so we can quickly generate some traffic to our system. That way, things in the dashboard will look like they would if you deployed a real production system to your Kong instance.
Create the following two YAML files:
Apply these configurations with kubectl:
After a few minutes, those pods should be available, and you can start sending traffic to your services:
After letting your traffic simulation run for just a few minutes, return to your Grafana instance in your browser (http://localhost:3000) and zoom in on the last few minutes of activity. You should see lots of beautiful visualizations ready for your analysis, with just a little bit of Kubernetes know-how.
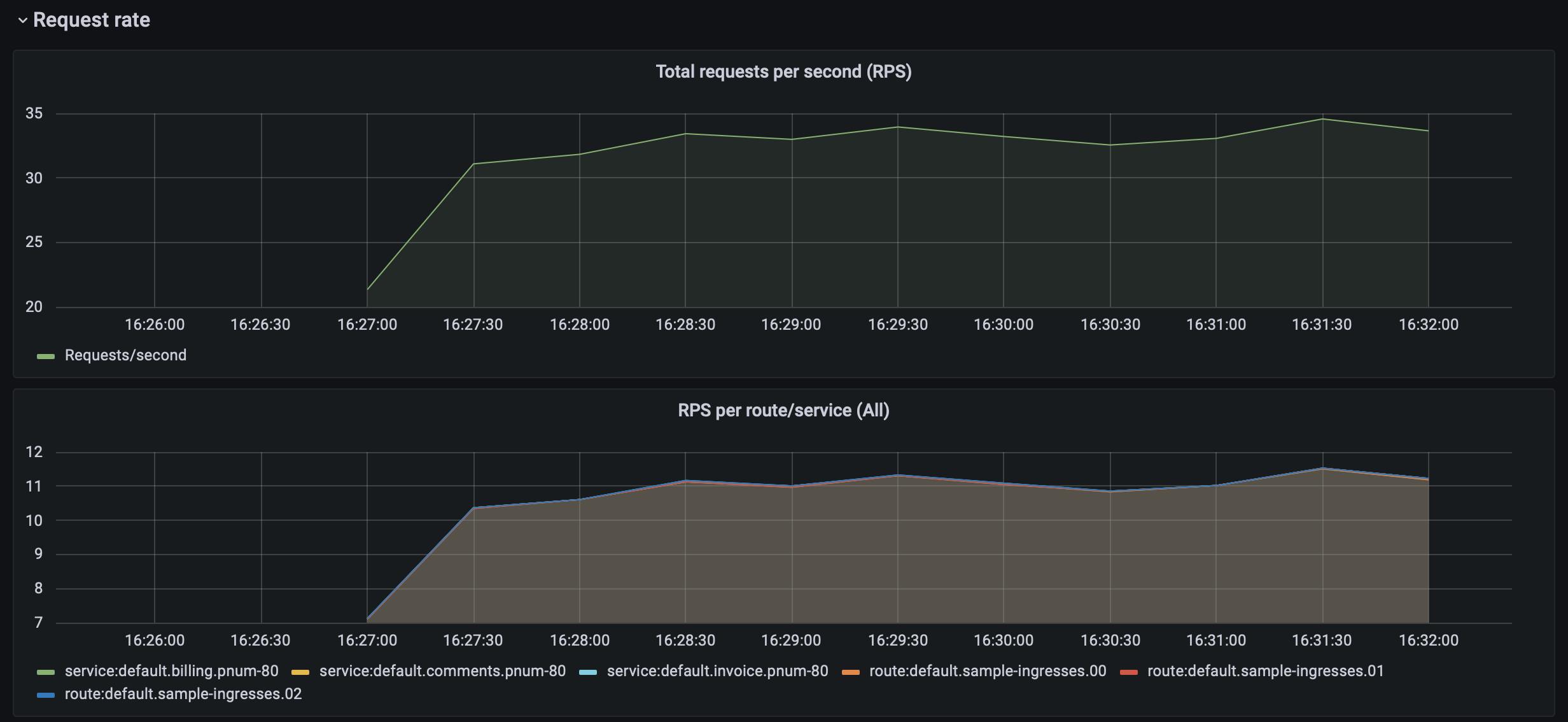
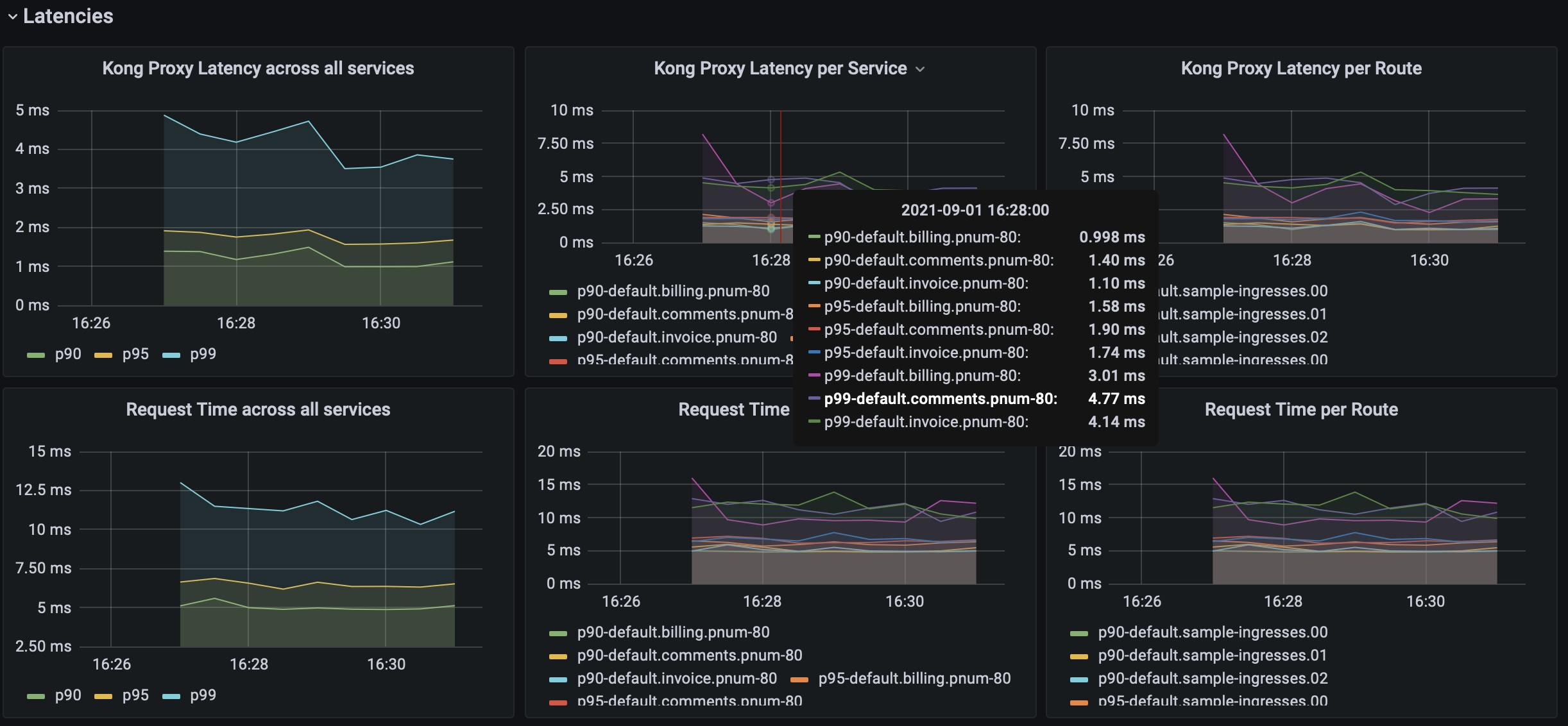
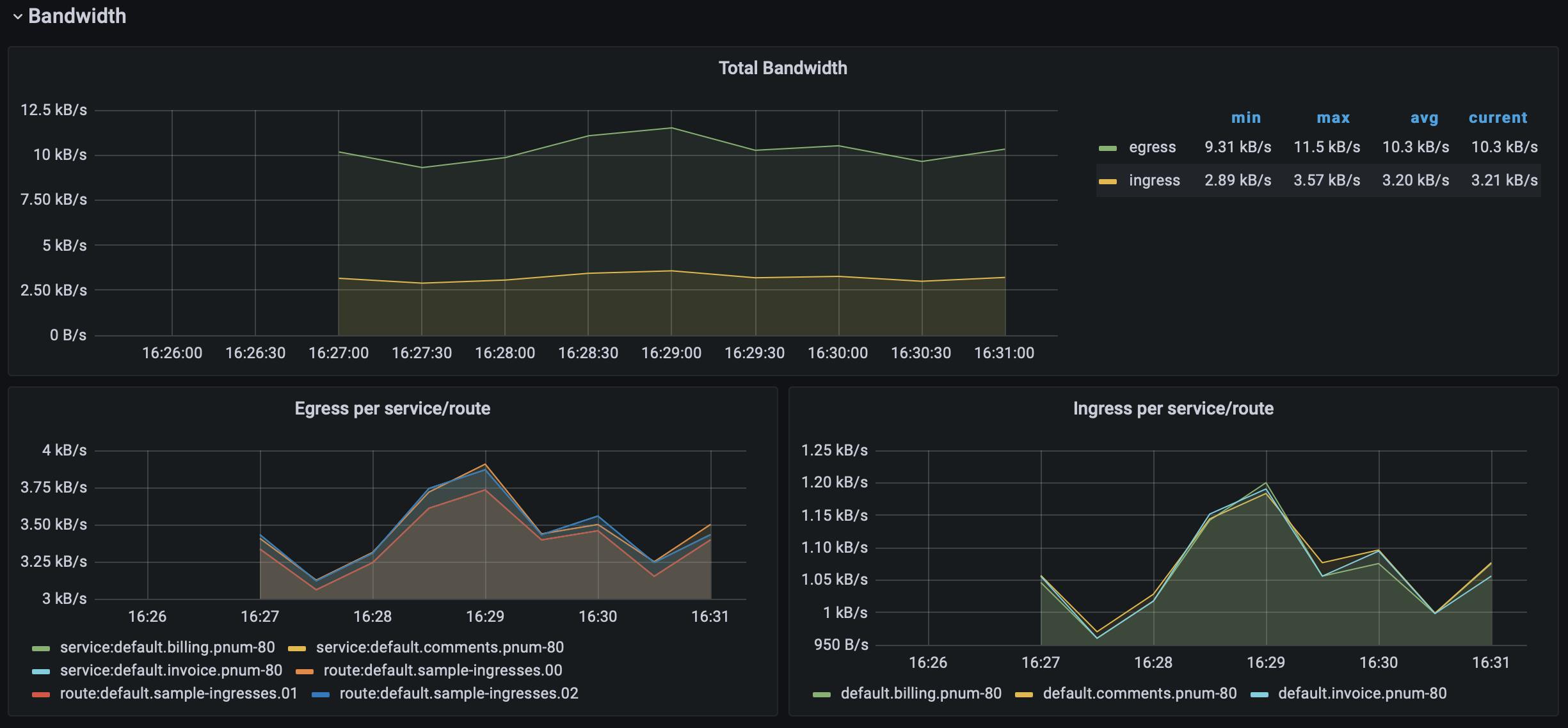
Conclusion
If you've been following along, now you're free to play around with all the out-of-the-box monitoring solutions. You can even introduce new Prometheus metrics in your instance or create Grafana dashboards of your own. Since this is a custom installation of these powerful tools, there is no limit to what you can accomplish with your new APM stack.
When you finish the experiments, cleanup is simple:
- Give your while loop a Ctrl+C to terminate it.
- Shut down your port forwarding processes.
- Run kind delete cluster –name kong to terminate your cluster.
Once you've finished this Prometheus and Grafana on Kubernetes Ingress tutorial, you may find these other Kubernetes tutorials helpful:
- Configuring a Kubernetes Application on Kong Konnect
- Kubernetes Ingress gRPC Example With a Dune Quote Service
- Managing Docker Apps With Kubernetes Ingress Controller
Have questions or want to stay in touch with the Kong community? Join us wherever you hang out:
🌎 Join the Kong Community🍻 Join our Meetups💯 Apply to become a Kong Champion📺 Subscribe on YouTube🐦 Follow us on Twitter⭐ Star us on GitHub❓ ️Ask and answer questions on Kong Nation