In this blog post series, we have discussed how Kubernetes enhances a container-based microservices architecture. We examine the rise of containers and Kubernetes to understand the organizational and technical advantages of each, including a deep dive into the ways Kubernetes can improve processes for deploying, scaling and managing containerized applications.
The first in the series covered [Next-Generation Application Development](https://konghq.com/blog/kubernetes-modernizing-microservices-architecture)Next-Generation Application Development.
The second covered the [Next Frontier: Container Orchestration.](https://konghq.com/blog/container-orchestration)Next Frontier: Container Orchestration.
In this post, we focus on how Kubernetes gets work done.
## What Is Kubernetes?
The name stems from an ancient Greek word for "pilot" or "helmsman of a ship." In keeping with the maritime theme of Docker containers, Kubernetes is the pilot of a container ship.
Originally, Kubernetes started as an internal project at Google named [*Borg*](https://kubernetes.io/blog/2015/04/borg-predecessor-to-kubernetes)*Borg*. Google has been running containerized workloads in production for over 15 years and through their experiences managing containers at scale, Borg was born.
In 2015, the technology of Borg was open sourced and donated to the Cloud Native Computing Foundation (CNCF) as Kubernetes. Since then, Kubernetes has become widely adopted as the de facto standard for managing containers at scale.
## What Challenges Does Kubernetes Solve?
Before we dive into the challenges Kubernetes solves, let's briefly recap some topics covered in the previous two blog posts.
Moving application workloads to containers from virtual machines frees developers from having to worry about whether their code and dependencies run correctly in production environments.
The rise of container adoption also means that applications can be isolated from other applications. If a container goes down, it won't affect other containers or the host. Containerization also reduces the size of the application footprint, making them easier to manage and allowing more containers to run on the same physical server, maximizing infrastructure.
Containers facilitate a more efficient DevOps process, freeing developers from having to depend on DevOps to provision hardware or VMs to support their applications.
With the industry embracing containerization, the need for the next innovation arose, which was container orchestration. Enter Kubernetes, which attempts to solve the following challenges:
- - Large scale, complex applications needing to be highly available
- - Resiliency to large workload fluctuations (horizontal scaling)
- - Optimization of cloud resources to minimize costs
- - Reliable deployments
- - Service discovery and load balancing
- - Storage orchestration
## Breaking Down Kubernetes
Let's first start with the high-level architecture diagram, depicting the system components (see Figure 1). In the simplest form, Kubernetes is made up of a centralized manager (master node), along with some worker nodes.
The manager runs an API server, scheduler, a controller and a key-value store (etcd) to keep the state of the cluster. Kubernetes exposes an API via the API server so that you can communicate with the API using a local client called kubectl. The scheduler sees the requests for running containers coming from the API and finds a suitable node to run that container in.
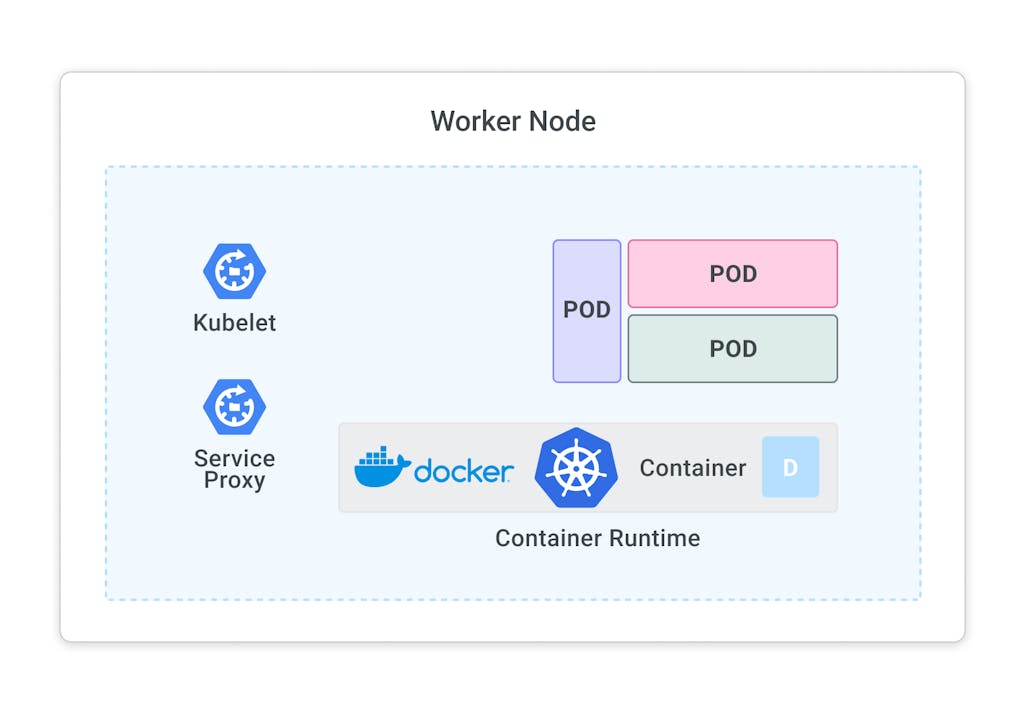
Each node in the cluster runs two processes: a kubelet and a service proxy. The kubelet receives requests to run the containers and watches over them on the local node. The proxy creates and manages networking rules to expose the container to the network.
Kubectl is a CLI tool commonly used to interact with the Kubernetes API.
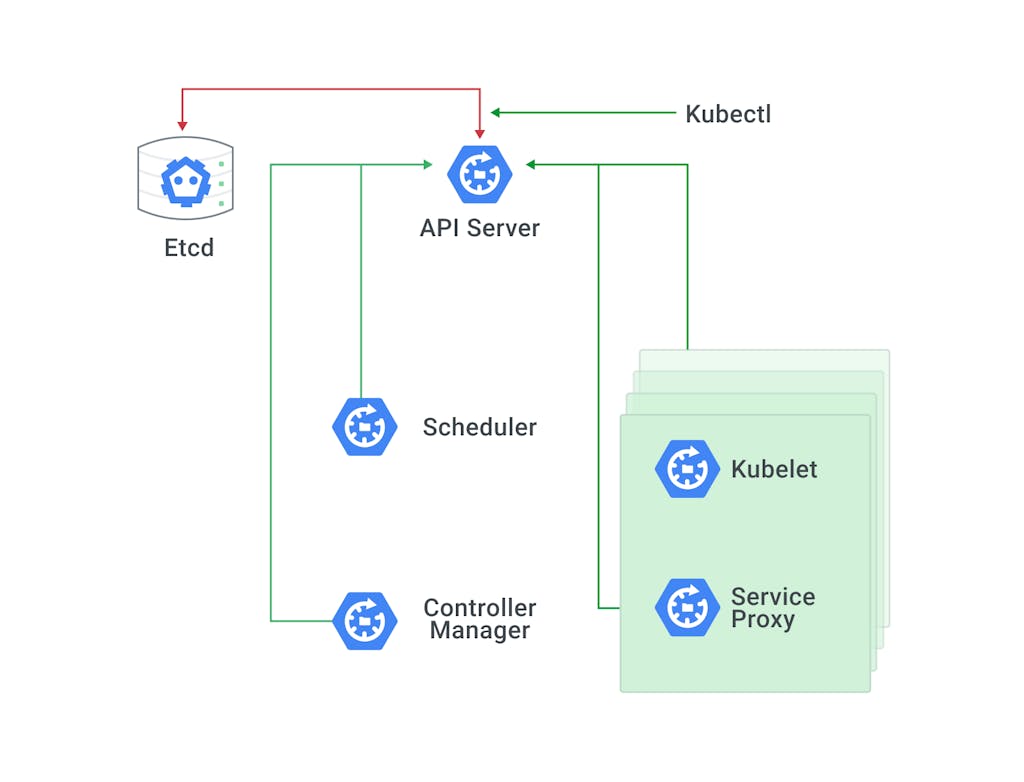
Figure 1: Kubernetes system components
So, in a nutshell, Kubernetes has the following characteristics:
- - Made up of a manager and a set of worker nodes
- - It has a scheduler to place containers in a cluster
- - It has an API server and a persistence layer with etc.
- - It has a controller to reconcile states
- - It can be deployed on VMs or bare-metal machines, in public clouds or on-premise
### What is a Pod?
A pod is the smallest element of scheduling in Kubernetes. Without it, a container cannot be part of a cluster. If you need to scale your app, you can only do so by adding or removing pods. The pod serves as a ‘wrapper' for a single container with the application code. Based on the availability of resources, the Master schedules the pod on a specific node and coordinates with the container runtime to launch the container.
### What is a Service?
Pods aren't constant and so one of Kubernetes best features is that non-functioning pods get replaced by new ones automatically. However, these new pods have a different set of IPs which can lead to processing issues as IPs no longer match.
Services are introduced to provide reliable networking by bringing stable IP addresses and DNS names to an unstable pod environment.
A Kubernetes service can control traffic coming and going to a pod by providing a stable endpoint (fixed IP, DNS and port).
Pods are associated with services through key-value pairs called labels and selectors. So, a service can automatically discover a new pod with labels that match the selector
### What is a Label?
A Label is a metadata tag that makes Kubernetes resources easily searchable for developers. Since many Kubernetes functionalities rely on querying the clusters for certain resources, the ability to label resources is critical to ensure developer efficiency. Labels are fundamental to how both Services and Replication Controllers function.
### What is a Volume?
A Kubernetes Volume is a directory that contains data accessible to containers in a given Pod. Volumes provide a plug-in mechanism to connect ephemeral containers with persistent data stores elsewhere.
### What is a Namespace?
A Namespace is a grouping mechanism inside of Kubernetes. Services, Pods, Replication Controllers and Volumes can easily cooperate within a Namespace, but the Namespace provides a degree of isolation from the other parts of the cluster.
### What is a Replication Controller?
A Replication Controller is designed to maintain as many pods that have been requested by a user—allowing for easy scaling. If a container goes down, the Replication Controller will start up another container, ensuring that there is always a correct number of replica pods available.
## The Container Orchestration Landscape
There are several tools that also provide container orchestration capabilities. The biggest players are Kubernetes, Docker Swarm, Rancher, and Mesosphere DC/OS. Docker Swarm is an easier-to-use option in contrast to Kubernetes, which can be complex to deploy and manage.
Mesosphere DC/OS is a platform designed to orchestrate data workloads and containers that is based on [Apache Mesos](https://mesos.apache.org)Apache Mesos. It offers a choice of two container orchestrators: Kubernetes and Marathon. It is designed to run containers alongside other workloads, such as machine learning and big data, and offers automated management of data frameworks ([Apache Kafka](https://kafka.apache.org)Apache Kafka, [TensorFlow](https://www.tensorflow.org)TensorFlow and many others) in addition to containers.
Overall, Kubernetes is currently the most popular out of the three by the number of community contributors and enterprise adoption. It is supported and contributed to by the most diverse set of individual and industry players. The key to Kubernetes' success has been its contributor-first approach to open source software, which has garnered a huge support base and very fast velocity for developing new features.
Kubernetes provides the building blocks for launching and monitoring containers and is now focused on creating different sets of container use cases on top of its platform to address different types of advanced workloads.
## How Kubernetes Is Changing Microservices Architectures
Microservices have accelerated software development in all sectors of the IT industry. They allow for applications to be engineered as small, independent services so that engineering organizations can develop their applications as independent components, which combined offer the full breadth of functionality of a monolithic application.
These components communicate with each other via application programming interfaces (APIs) and can, therefore, be written in different programming languages, released on different cadences and worked on by different independent teams without compatibility issues. For example, one team can write a containerized microservice in Ruby that will run on Kubernetes and communicate seamlessly with a containerized microservice built in Python running in the same Kubernetes cluster and built by a separate team.
As we adopt microservices architectures, monitoring across the different services becomes more important and more complex. Kubernetes has done a great job promoting and supporting an ecosystem of compatible, composable tooling for monitoring, logging, tracing, continuous integration and deployment (CI/CD), and other tasks that become necessary with a microservice deployment.
The decision to use Kubernetes should not be solely based on which container orchestration tool to use to further an organization's microservices strategy. Organizations must also consider what complementary ecosystem tools they need. The Kubernetes ecosystem offers many of the building blocks needed to succeed with a microservices architecture. Kubernetes adoption requires cultural changes/shifts within an organization, including how software is built, tested and delivered (DevOps).
## Kong And Kubernetes: The Future Is Bright
Containers have accelerated software development, and the momentum behind Kubernetes is not slowing down any time soon. It has become the go-to container orchestrator because of its broad contributor base, high velocity, robust ecosystem and high enterprise adoption. With a growing number of contributors and IT service providers backing the orchestrator, Kubernetes will continue to make contributions to make running Machine Learning workflows on Kubernetes clusters simpler ([Kubeflow](https://www.kubeflow.org)Kubeflow), as well as improve developments to manage the applications and workloads at the edge.
API Gateways are crucial components of a microservice architecture. The API gateway acts as a single entry point into a distributed system, providing a unified interface.
As a native Kubernetes application, Kong Gateway can be installed and managed precisely as any other Kubernetes resource. Through the use of Custom Resource Definitions (CRD), you can implement security and identity policies to ensure consistency across Kubernetes workloads. It integrates well with other CNCF projects and automatically updates itself with zero downtime in response to cluster events like pod deployments.








