## It started out with a kiss
Since the early ’90s, computer users and businesses have used Adobe's venerable PDF format as the de facto choice for digital documents where portability and advanced features such as form-filling, digital signatures, and accurate rendering is important.
First announced on January 1993 in San Jose, California, during the Windows and OS/2 Conference, PDF's original killer feature was its ability to accurately represent graphical documents at a fraction of the size of the native file formats of contemporary desktop publishing software like QuarkXPress (though it would still take some time to send over your 9600-baud modem).
Originally a proprietary format, PDF was standardized as ISO 32000 in 2008, and since then, an abundance of software that reads and writes PDF documents almost as well as Adobe's own have come to market.
Fast-forwarding to the summer of 2017, back when Electron was still version 1 (today we're on v19), a [feature request](https://github.com/Kong/insomnia/issues/323)feature request was filed to add the ability for Insomnia to view a PDF file directly in the preview.
Before this change, if you made a request in Insomnia that responded with an [application/pdf Content-Type](https://datatracker.ietf.org/doc/html/rfc3778)application/pdf Content-Type, you'd get nonsense:

*PDF raw data displayed in Insomnia similar to before the change was merged in 2017.*
To test this, I set up a mock request in mockbin with a [research whitepaper](https://isotropic.org/papers/chicken.pdf)research whitepaper I had laying around:
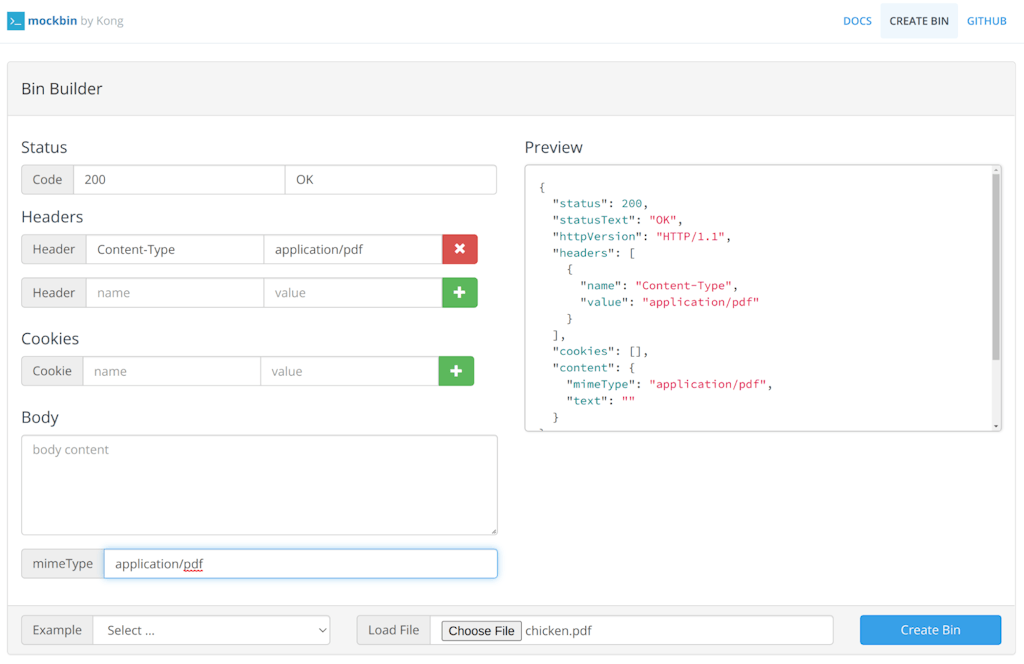
*By the way, if you haven't checked out mockbin: you're missing out! http://mockbin.org*
We aim to make Insomnia as simple and intuitive to use as possible. We want to add context that's useful for users. I hope you’ll agree that the raw PDF output is not very useful, to say the least.
At that point, if you wanted to render a PDF document inside of an Electron app, you didn't have much of an option. You had to embed a third-party PDF renderer. To that end, people created projects like [electron-pdf-window](https://github.com/gerhardberger/electron-pdf-window)electron-pdf-window to try to work around this limitation.
In Electron you can accomplish PDF rendering a couple of different ways:
- - You can use a [Node Native Extension](https://medium.com/the-node-js-collection/native-extensions-for-node-js-767e221b3d26)Node Native Extension. You might know this as [Node C++ extensions](https://nodejs.org/api/addons.html)Node C++ extensions but it's more than C++. This option can work quite well, but it complicates the build process, adds a large maintenance burden, and is overall pretty heavy-handed. There's a funny little thing that happens with Electron where because the binary interface is a little different than vanilla NodeJS, you have to [compile the module for Electron](https://www.electronjs.org/docs/latest/tutorial/using-native-node-modules)compile the module for Electron separately. We know the pains of this all too well because this is what we have to do for [Node-LibCurl](https://github.com/JCMais/node-libcurl#electron--nwjs)Node-LibCurl (C++), which powers the networking stack of Insomnia.
- - Or, you could parse and render a PDF using JavaScript. Although it probably won't ever achieve the same performance and robustness as a native PDF viewer, it is a compelling option from many other standpoints.
### Enter: PDF.js
If you spend any time at all looking for pure-JavaScript implementations for PDF viewers, you'll quickly find out about Mozilla's PDF reader, [PDF.js](https://mozilla.github.io/pdf.js/)PDF.js.

*Mozilla's fantastic open-source offerings save the day again!*
PDF.js has been the native PDF rendering engine in Firefox since Firefox 19 in 2013, and has steadily improved over the years in its ability to render PDFs accurately. It reads and parses a PDF document using ordinary web technology and uses HTML5 canvas to display it on screen.
Since the `pdfjs` NPM was already taken and this was before the days of npm package namespace prefixing (e.g. [@kong/changelog-generator](https://www.npmjs.com/package/@kong/changelog-generator)@kong/changelog-generator) they distribute this project under the npm [`pdfjs-dist`](https://www.npmjs.com/package/pdfjs-dist)`pdfjs-dist`. Originally, we consumed this via a package that added some nice babel transforms and React bindings, [`simple-react-pdf`](https://www.npmjs.com/package/simple-react-pdf)`simple-react-pdf`.
Here's how it looked with PDF.js in late June 2017 when the [first PR](https://github.com/Kong/insomnia/pull/325)first PR merged. It's much better than nothing, but it's *pretty *close to nothing. The PDF renders, but there's nothing else. No way to download, print, zoom, scroll by page, fit to window… nothing to help the user out aside from the bare minimum.
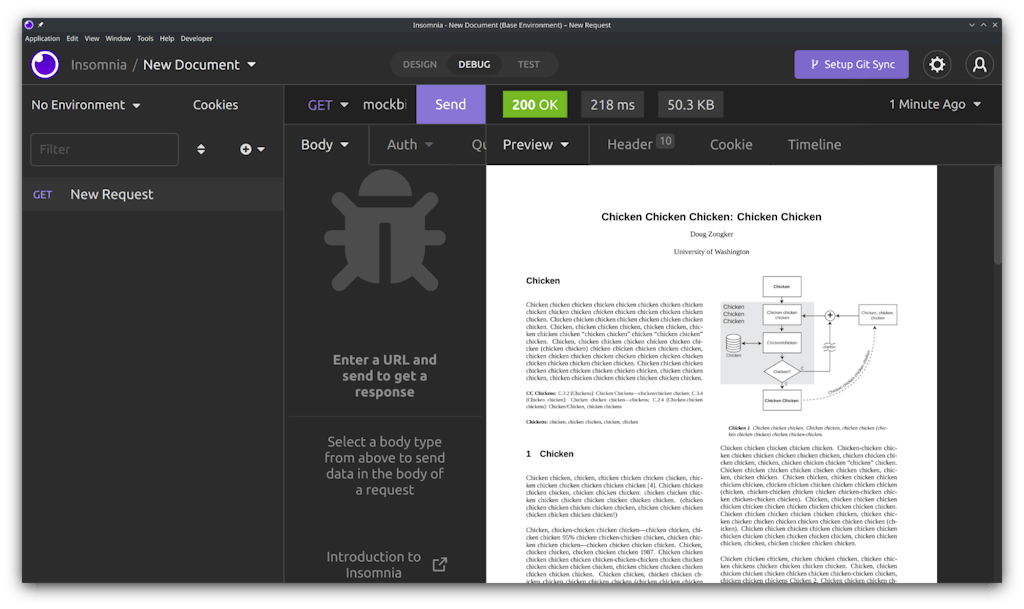
## How did it end up like this?
Sadly, it was only two short months before the initial implementation broke completely and we had to remove simple-react-pdf and do a [total rewrite](https://github.com/Kong/insomnia/pull/518)total rewrite using PDF.js directly. The initial wrapper didn't support things like Apple retina rendering, web workers, re-rendering on window resize, and more.
At the time it looked like the trouble might be over, but in the end for better or for worse, PDF.js was always a problem for the Insomnia app (even after we brought it in as a direct dependency). We definitely had [bugs](https://github.com/Kong/insomnia/issues/1533)bugs related to it that affected users. But the worst part was probably the difficulty it posed to day-to-day development.
### Development woes
We move fast on Insomnia. We kept it up-to-date [pretty well](https://github.com/Kong/insomnia/pull/2645/files#diff-78bdea1fe88ccd0f1c64376bd44085d8a13d4dcaf2b85cc2429ffacce63fd6a8)pretty well, but we kept hitting problems with the way the package is built that were hard to work around. Due to the problems we had experienced we [added smoke tests](https://github.com/Kong/insomnia/pull/2645/files#diff-f98ce99d7999cc287d8d027274ea42a28d73493d4d4f5bb86968139dccbb51dd)added smoke tests for PDF.js so we could at least be more proactive in fixing it when it breaks unexpectedly.
Recently, we completely removed webpack from all packages in our app and switched to [esbuild](https://esbuild.github.io/)esbuild and [vite](https://vitejs.dev/)vite. As we did this, it was extremely common that we saw errors related to PDF.js and the way the code is built. There's a [custom code-path for webpack](https://github.com/mozilla/pdf.js/tree/master/examples/webpack)custom code-path for webpack use-cases which requires [`worker-loader`](https://v4.webpack.js.org/loaders/worker-loader/)`worker-loader` which was deprecated in webpack v5. That means that even if we had stayed with webpack we were going to hit a stopping point with PDF.js one way or the other.
In the last few years as [ES Modules](https://hacks.mozilla.org/2018/03/es-modules-a-cartoon-deep-dive/)ES Modules have become more and more common, next-generation bundlers like vite don't support [CommonJS](https://en.wikipedia.org/wiki/CommonJS)CommonJS. Sadly, the PDF.js team [has said](https://github.com/mozilla/pdf.js/issues/10317#issuecomment-1112675400)has said they are not going to support this:
We don’t want to add even more builds and we also want to support both browsers and Node.js environments with the same builds.
On the TypeScript side, the types were always missing:

There are workarounds for this (e.g. module augmentation with manual mock implementations), but all of these roads end with us maintaining the types ourselves in our own project, which is pretty unfortunate.
Then comes the added bundle size.
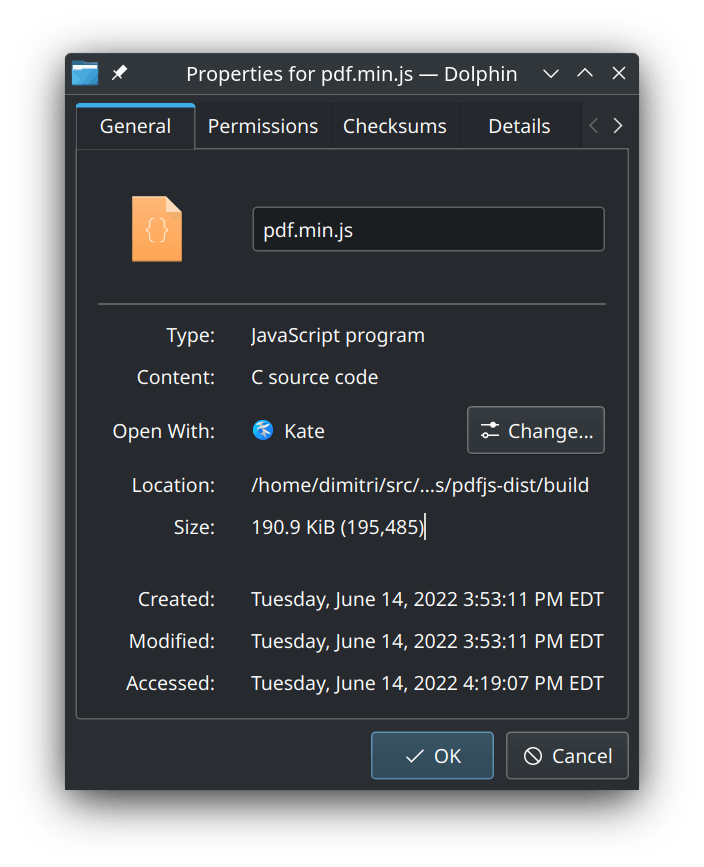
The PDF.js frontend itself is pretty huge by modern standards at 190 KiB (!?!) and 13,489 lines of code (when unminified).
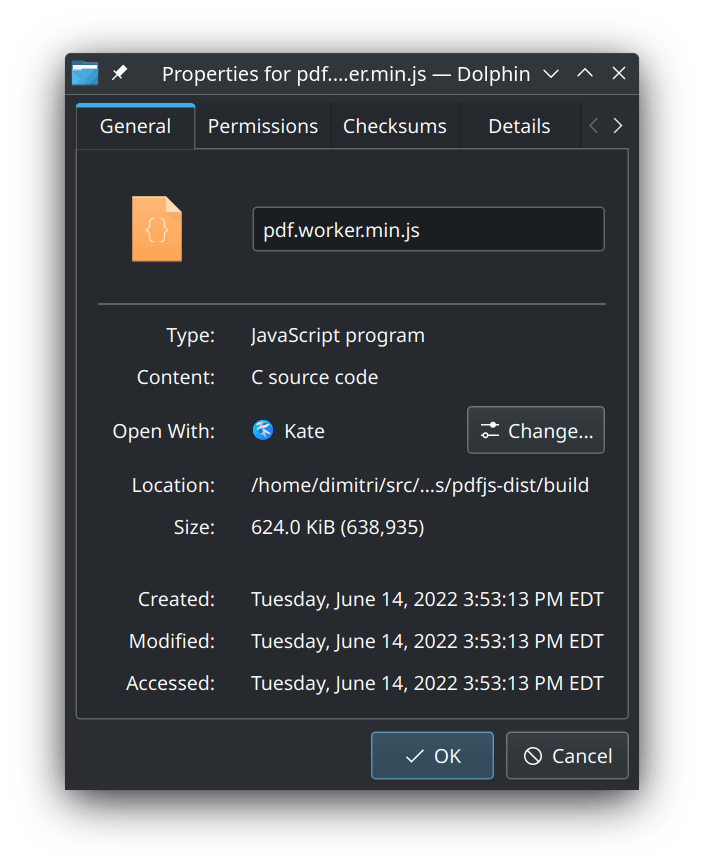
But the real heavy-hitter is the web-worker, weighing in at a massive 624 KiB (45,971 lines of code, unminified).
Together that rings up to be a whopping 815 KiB. Now… the thing is… yes, it's true that we're shipping a precompiled Electron app that's already pretty big. However, it is worth noting that, even disk and bandwidth usage aside, this much JavaScript code takes a lot of time to parse, compile and execute.
In addition to that, despite our best efforts, we continued to have [bugs](https://github.com/Kong/insomnia/pull/4723/files)bugs. We struggled to get it to even compile properly into our newer toolchain.
## It was only a kiss, it was only a kiss: The backstory
For context, perhaps it’s worth discussing the history of PDFs in the web browser.
Before modern browser extensions existed, the main way that third-party code ran in web browsers was via two competing technologies: Microsoft's ActiveX, supported by Internet Explorer, and Netscape's NPAPI, the de facto standard plugin API for other browsers.
These plugin APIs primarily allowed developers to expose additional functionality to web pages and display rich content like Flash games, QuickTime videos, VRML worlds, and indeed, PDF documents. At this point, if you wanted to be able to view PDF documents in the browser, you needed Adobe's PDF viewer plugin to be installed, or an alternative, such as Foxit Reader.
Of course, there were some problems with this.
The biggest and most egregious issue was security. These third-party add-ons were written in memory-unsafe languages, and typically ran with relatively little sandboxing and high privileges on the local machine. Given the complexity of the PDF format, this was not good news.
Around 2014, at long last, Google announced that it was deprecating NPAPI support in its browsers. Once a cornerstone of the Internet multimedia experience, the writing was finally on the wall for the traditional browser plugin. Their importance had already waned with the meteoric rise of the smartphone, for better or worse. While it was sad to say goodbye to these old friends, for many, it didn't come as a huge surprise.
Still, simply eliminating the functionality that NPAPI brought to the web platform was hard to stomach, so Google implemented new technologies: Native Client, and an NPAPI alternative called Pepper or PPAPI.
These alternatives retained some of the power of NPAPI, but with a much greater emphasis on security. However, lacking a proper specification outside of the Chrome implementation of it, among other objections, Mozilla ultimately chose to not support this new API, and it was relegated to the shadows.
Despite this, you can still view PDFs in Chromium today thanks to [a joint venture between Foxit and Google](https://www.foxit.com/blog//foxit-pdf-technology-chosen-for-google-open-source/)a joint venture between Foxit and Google all the way back in 2014. This new PDF code — dubbed PDFium — was open source and included in the Chromium codebase, meaning that for the first time Chromium itself had a PDF viewer; it no longer needed to ship a third-party Adobe plugin.
For technical reasons, PDFium was not available in Electron [until Electron 9.0.0](https://www.electronjs.org/blog/electron-9-0)until Electron 9.0.0 in May 2020, when refactors and improvements in both Chromium and Electron had made it possible to simply enable the PDFium plugin as-is. Surprisingly, this feature made it in with relatively little fanfare. Throughout the Electron 9.x release, continued bug fixes and stability improvements made it one of the most robust options for displaying a PDF in an Electron application.
## Mr. Brightside: The elegant solution
In what might be the best example of "smarter not harder" in the last calendar year for the Insomnia codebase, [James Gatz](https://github.com/gatzjames)James Gatz (a core engineer on the Insomnia team) came up with an elegant solution. His brilliant insight was to drop our usage of PDF.js altogether and use PDFium directly. In the years since Electron 1.x when the decision to use PDF.js was made, the goalposts had moved, but we didn't realize it.
His insight is a perfect example of why it can be so much more fun to work on a team.
Sure, it may be possible to make more money as a software engineer working freelance, but those wonderful "ah ha!" moments like this happen **so much more often** when you can get someone with a fresh perspective to look at a problem. While the rest of the team had been all spending weeks or months dealing with problems with PDF.js and trying to fix them, James saw through the problem and was able to come up with a creative solution.
This solution was not only simpler but *also *added functionality to the app!
Here's a short tour of all the things using Chromium's PDF rendering (PDFium) got us "for free™":
*PDF rendered in Insomnia*

*You can now print PDFs straight from Insomnia. It really works!*
*There's a one-click download button where you can easily download the PDF.*
*The "Document properties" view shows more technical details of the PDF.*
*You can see multiple pages of the PDF side-by-side.*
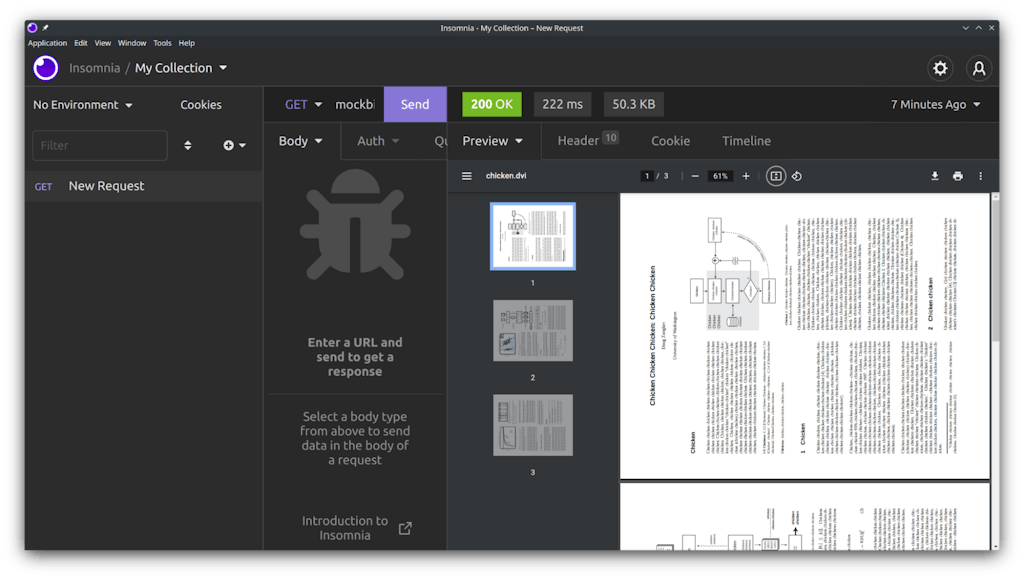
*There are many zooming and positioning features. You can rotate and zoom and fit the pages to the screen.*
And perhaps my favorite feature of all: we removed code from the app.
We didn't replace it with something else, either. [We just removed it](https://github.com/Kong/insomnia/pull/4720/files)We just removed it.
In doing so, we also added many more features for PDF handling in the app.
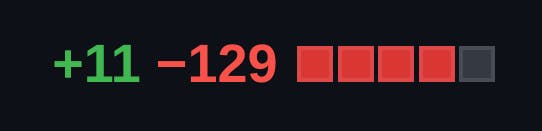
*11 lines of code added, 129 lines removed.*
And that's not to mention the 815 KiB reduction in our app size. This is a real success story if there ever was one.
## Destiny is calling me: Lessons learned
PDF.js is a fantastic project. It tackles a deceptively difficult problem, PDF parsing and rendering. But with a big problem, comes a big solution (35.6 MB on NPM, unpacked).
To me, this story is as much about the value of working on a team with super-talented teammates as it is about anything else.
We were working harder, not smarter, and didn't take a step back to reassess the situation. Once one person took that step… we were all instantly free from the issues that had been plaguing us. Free to move on to more important things, like building the simplest and easiest-to-use REST, gRPC, and GraphQL client on the planet.







