# Scaling Service Mesh Globally and Across Environments
Cody De Arkland
A true service mesh should focus on how to manage and orchestrate connectivity globally. Connecting a new service mesh for each use case is a much simpler problem to solve, but doing so won't help you scale. You'll just be throwing a service mesh in each cluster and calling it a day.
The more appealing solution is to stitch together environments. For example, when you have a vSphere cluster connecting two AWS resources, how do you stitch that together as a single connectivity-enabled platform?
Running globally enables:
- Self-service management of application connectivity
- Centralized policy application location
- Global "scale operations"
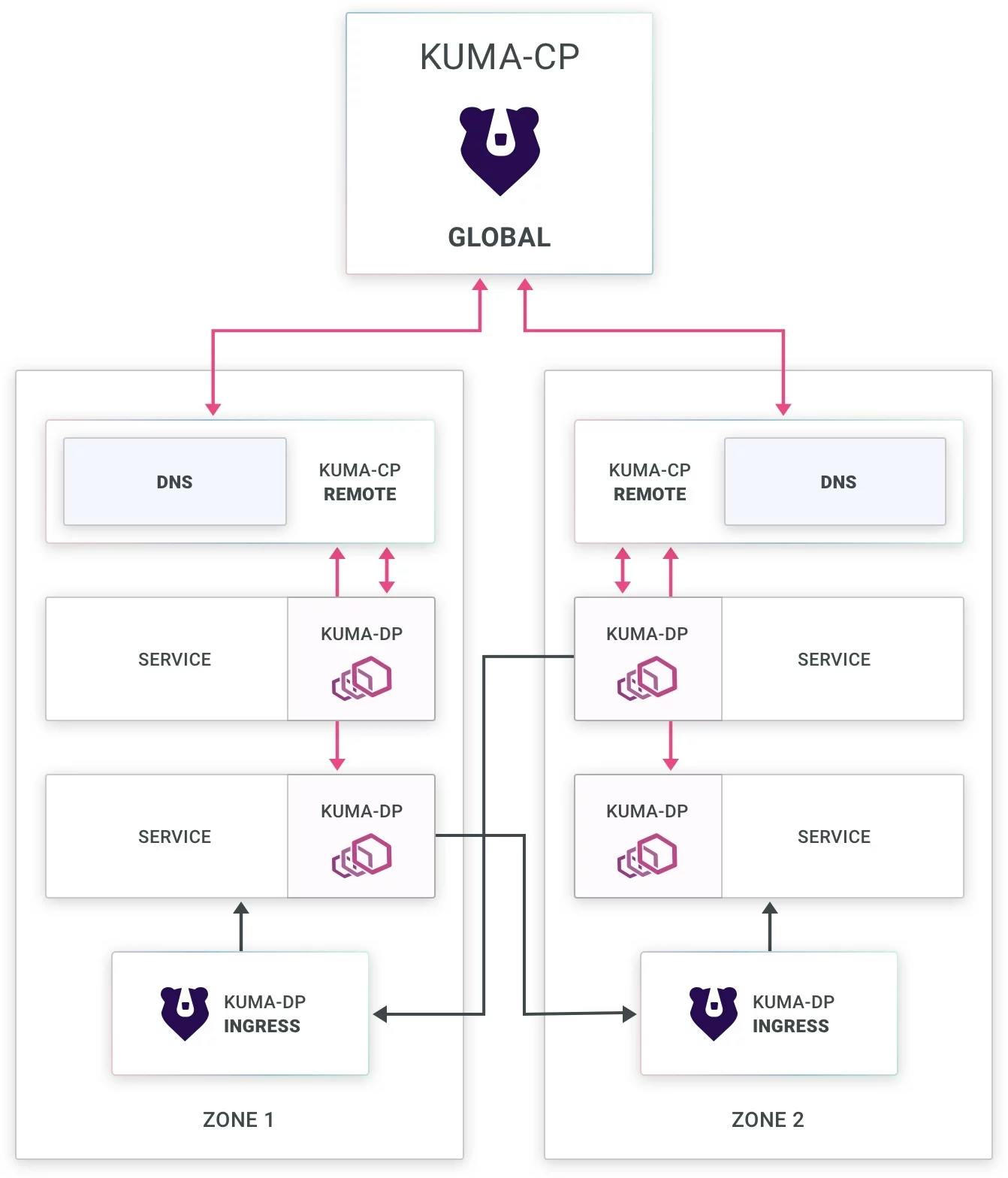
## **Kuma and Kong Mesh Global Control Plane Topology**
Within each zone, a combination of the control planes and the Envoy instances run Kuma DNS to help resolve resources in a local zone. An ingress in each zone allows traffic to come inbound (from systems outside of the zone) to the other instances. The zone ingress understands where to send the traffic, thanks to [Mutual TLS](https://kuma.io/docs/1.1.5/policies/mutual-tls)Mutual TLS (mTLS) on the cluster. mTLS adds an SNI header to the incoming traffic with the desired traffic destination.
## **Example: Scaling Service Mesh Globally and Across Environments With Kong Mesh**
To start, we'll bring up our remote control plane with sudo start kuma and enter my password.
I’ve already set up and initialized my database. As Kong Mesh comes online, I'll run tail -f /var/log/upstart/kuma.log and observe the logs to ensure nothing is going wrong.
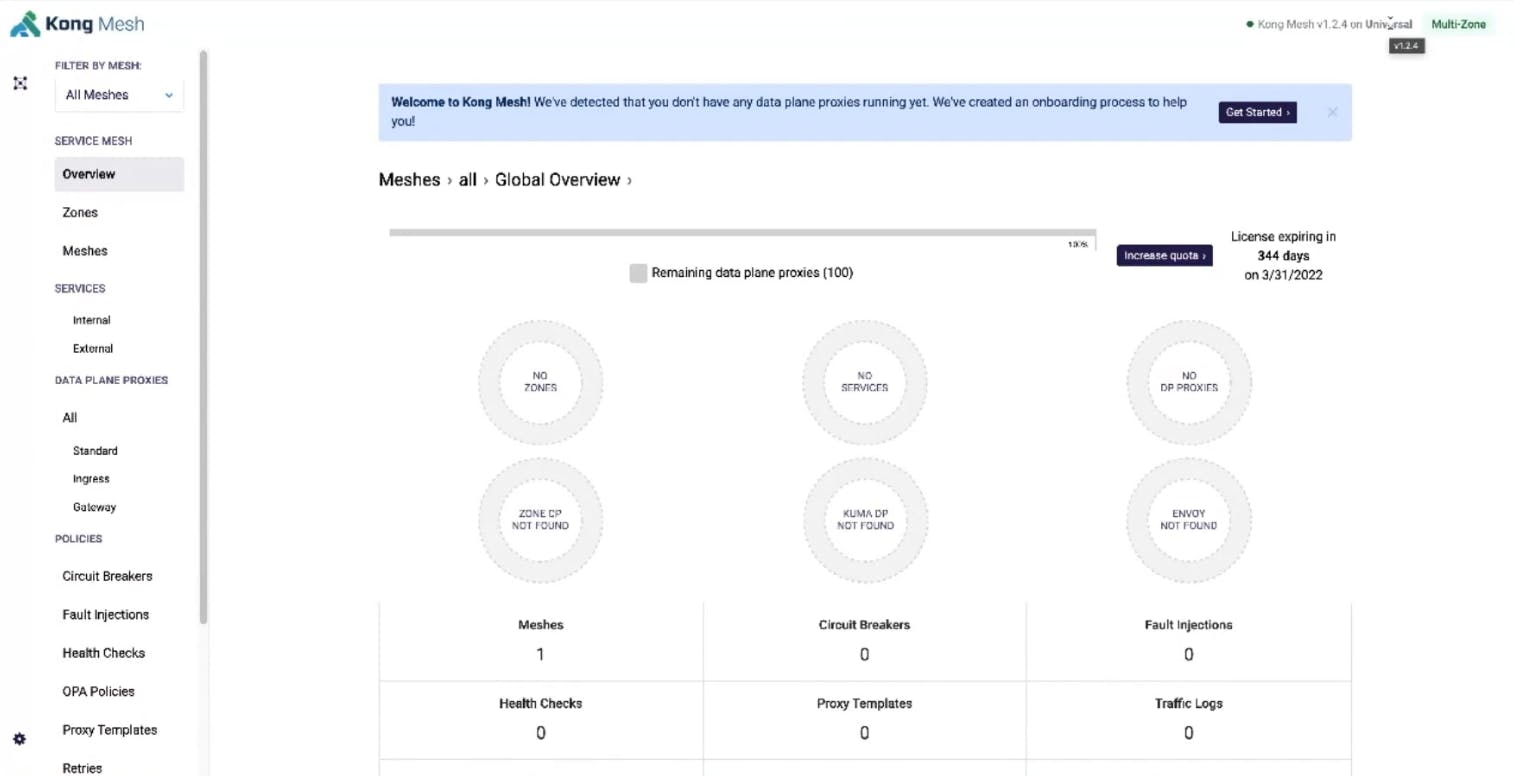
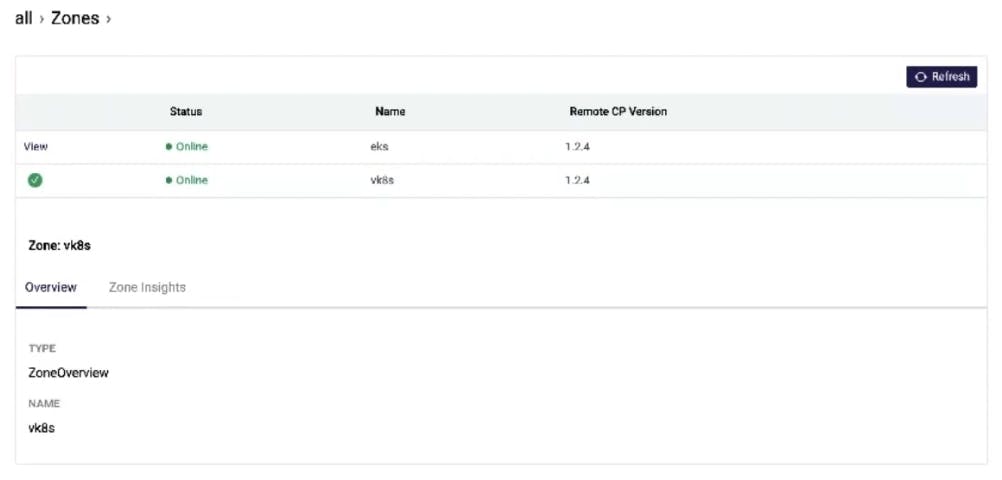
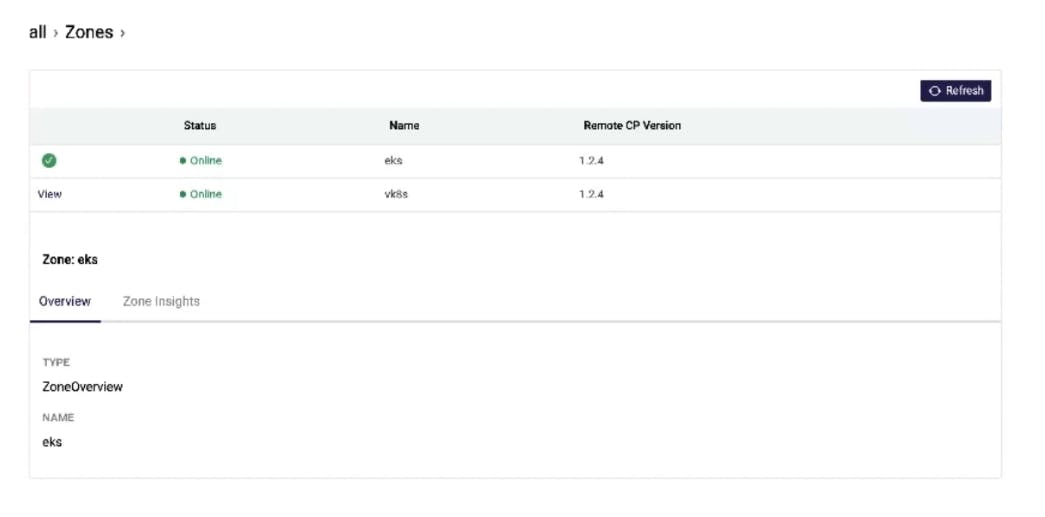
Once we refresh the UI, we'll see our Kong Mesh is online, with the license applied and running in universal mode. Universal mode means the control plane is running outside of Kubernetes. With this environment up and running, we can accept virtual machines (VMs) and Kubernetes clusters. Also, by configuring this as a multi-zone deployment, we’re able to service many zones.
Let’s start bringing some new zones into our service mesh. If we go into kubectx, we can see I’ve got my AWS EKS, vSphere and CAPV Lab cluster. kubectx is a handy tool that allows us to switch between multiple Kubernetes contexts.
In my vSphere-based Kubernetes environment, I’m running cilium as my CNI. I based the cluster on the ClusterAPI for vSphere implementation. That means I'm also getting the vSphere Container Storage Interfaces (CSI).
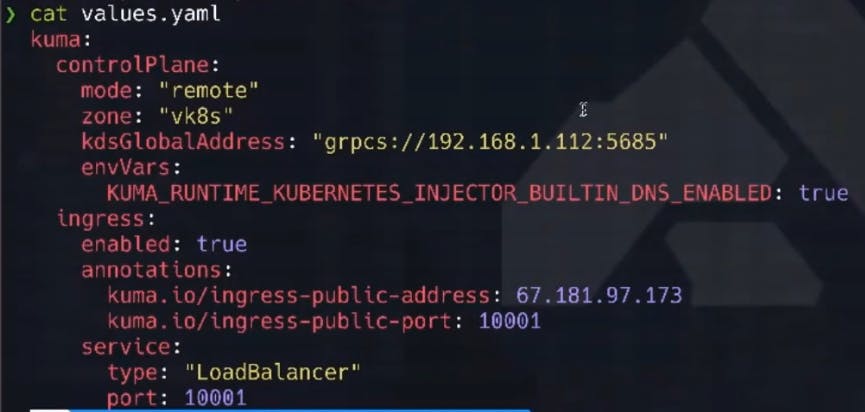
Here are my values.yaml file for the Helm install. I did a cool trick in the highlighted section below using my external IP for my lab environment. I’m also adding it inbound to the ingress created inside.
Since my lab runs in my garage, I need to tell the certificates involved what the "external" IP address is for my environment to successfully negotiate trust (the *mutual* part of mTLS).
Within this cluster, we'll create our kong-mesh namespace.
kubectl create namespace kong-mesh-system
Then, run my Helm install command to deploy Kong Mesh.
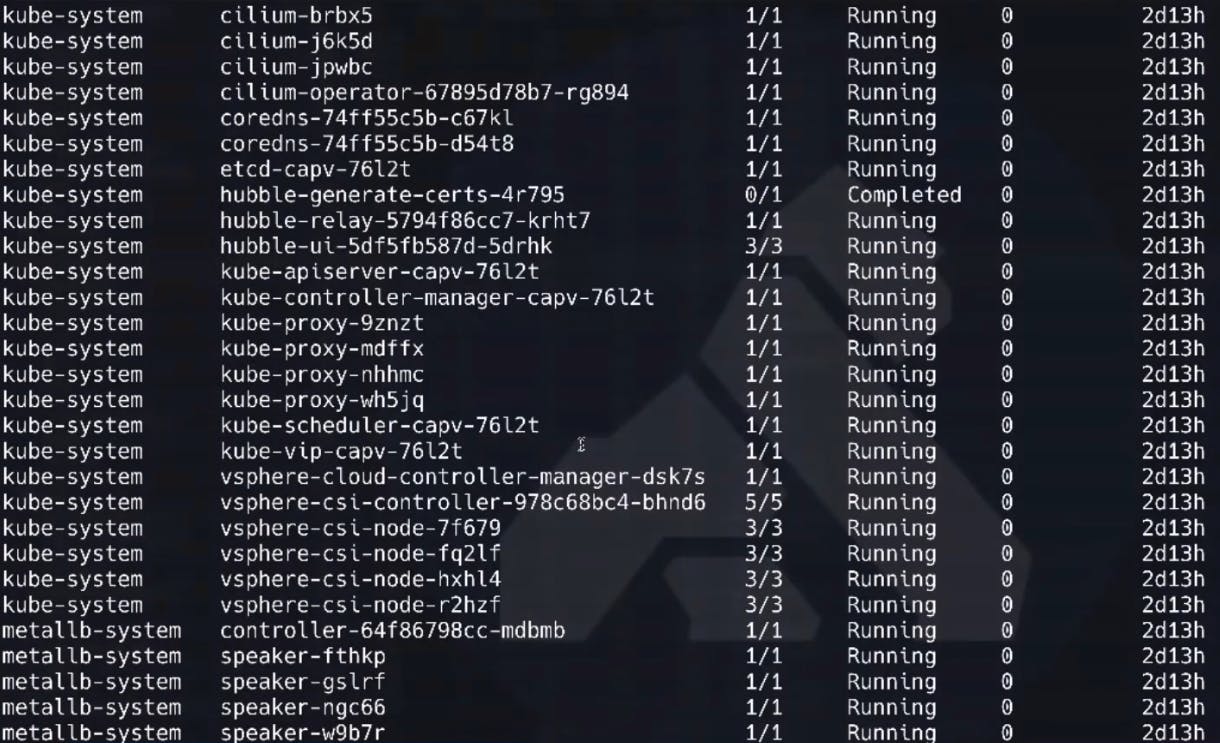
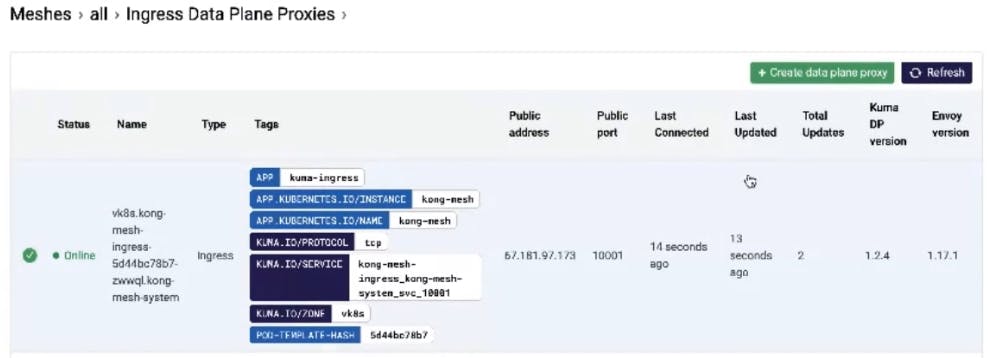
Very quickly after this command executes, our Kong Mesh services start coming online. An example is our Kong Mesh ingress and its associated data plane. The data plane receives its configuration information from the control plane.
After a few moments, we can verify that our control plane is up and running (1/1 under ready).
Let's create the namespace for our application by running k apply -f namespace.yaml. We want anything in the namespace file to get a sidecar by adding the sidecar-injection: enabled annotation.
That sidecar is the data plane object that gets registered into Kong Mesh/Kuma. All the connectivity policy traffic information gets pushed down into that sidecar. The sidecar then intercepts incoming and outgoing traffic for the service mesh.
We can finally start deploying our application. Let's apply a couple of manifests from the application directory.
Let's apply the api-local.yaml, db.yaml and redis.yaml.
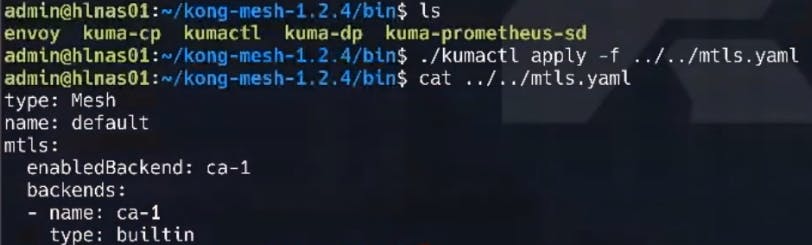
To leverage the multi-zone (global) communication, we need to enable mTLS on our cluster (mutual TLS). We need this to pass the SNI headers to tell our service mesh where traffic needs to land. We apply this configuration with the following command.
./kumactl apply -f ../../mtls.yaml
Here's what that looks like.
Next, let's install a Kong Mesh control plane on my Amazon EKS cluster in a slightly different way—using kumactl to drive the install. We will call this zone EKS, enable zone ingress, connect to my lab (leveraging the kds-address configuration flag) and turn on a DNS configuration in that environment.
k apply -f namespace.yaml here as well to give ourselves a namespace for our running workload with the necessary configurations in place.
In the Kong Mesh UI, we can see both zones have registered. The ingress is also starting to come up at this point.
Let's deploy our application by applying our react manifest. Because of the application configurations, this application will only come up if it can connect to the other tiers in our environment.
k apply -f react.yaml
To allow us to connect inbound to our application, let's also install the Kong Ingress Controller.
k apply -f kic.yaml
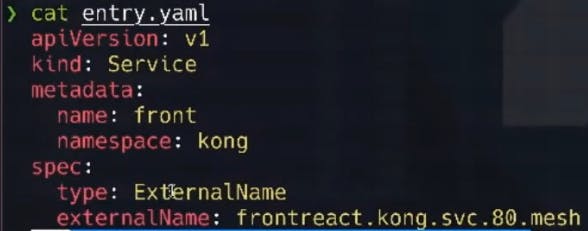
For Kong Ingress Controller to leverage the service mesh for communication, we'll want to create a Kubernetes service entry that acts as the entry point for this application. We'll apply the entry point Kubernetes manifest as follows:
k apply -f entry.yaml
For context, this manifest looks like the below:
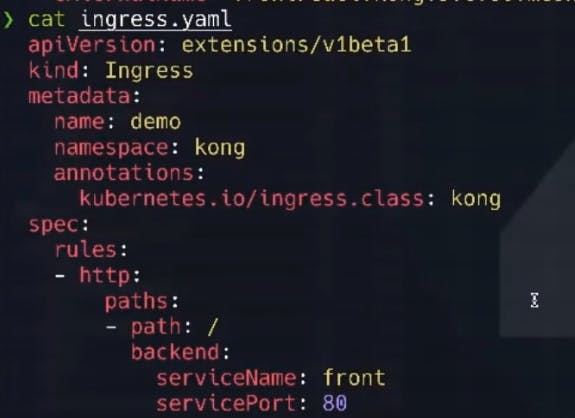
And finally, we’re going to apply the ingress configuration to allow connectivity to that entry point.
k apply -f ingress.yaml
Here's what the ingress file looks like:
As our application loads, we can see that it's successfully reaching the different tiers across the environment, across multiple zones (clouds in this case).
If we wanted to take this a step further, we could deploy another version of the API or even the frontend and start to play with traffic policies to orchestrate the traffic movement between those versions. This concept is a form of "progressive delivery," where we gradually roll out new services into an environment instead of releasing them all at once. We use these traffic policies to control traffic flow and deployment speed.
This is one of my favorite examples of cross-environment service mesh. As we start to bring in new applications and versions, we want intelligent ways to bring them online, get them connected and interact.
I hope you found this tutorial helpful. Get in touch via the [Kuma community](https://kuma.io/community)Kuma community or learn more about other ways you can leverage Kuma and Kong Mesh for your connectivity needs with these resources:
The goal of Integration Platform as a Service (iPaaS) is to simplify how companies connect their applications and data. The promise for the first wave of iPaaS platforms like Mulesoft and Boomi was straightforward: a central platform where APIs, sys
The first release of Kong Mesh for 2024 (version 2.6) brings many new features that ease day 0 for new starters of service mesh reinforcing our goal of making a simple yet powerful product! In this blog, we'll break down these new features and provi
The latest release of Kong Mesh (version 2.5) brings many new features that push the envelope and make Kong Mesh the logical choice of a service mesh to meet your objectives. In this blog, we'll break down these new features and provide tailored us
Traffic patterns shape architectural boundaries and understanding them clearly reveals why different tools are necessary. North-south traffic flows between external clients and your services, crossing the network perimeter in the process. Common e
APIs have quietly powered the global shift to an interconnected economy. They’ve served as the data exchange highways behind the seamless experiences we now take for granted — booking a ride, paying a vendor, sending a message, syncing financial rec
The Anatomy of Architectural Complexity
Modern architectures now juggle three distinct traffic patterns. Each brings unique demands. Traditional approaches treat them separately. This separation creates unnecessary complexity.
North-South API Traf
Managed Redis cache is a turnkey "Shared State" add-on for Kong Dedicated Cloud Gateways. It is designed to combine the performance of an in-memory data store with the simplicity of a SaaS product. When you spin up a Dedicated Cloud Gateway in Kong