## **What is Service Mesh and Where Did it Come From?**
Over the past few months, you may have noticed the explosion of industry chatter and articles surrounding service mesh and the future of software architecture. These discussions have been highly polarizing, with tribes forming around specific vendors. While this partisan trend is to be expected, the common thread among these discussions is the **rapid transformation of how APIs are used in the enterprise**, and what this means for the topology of our traffic.
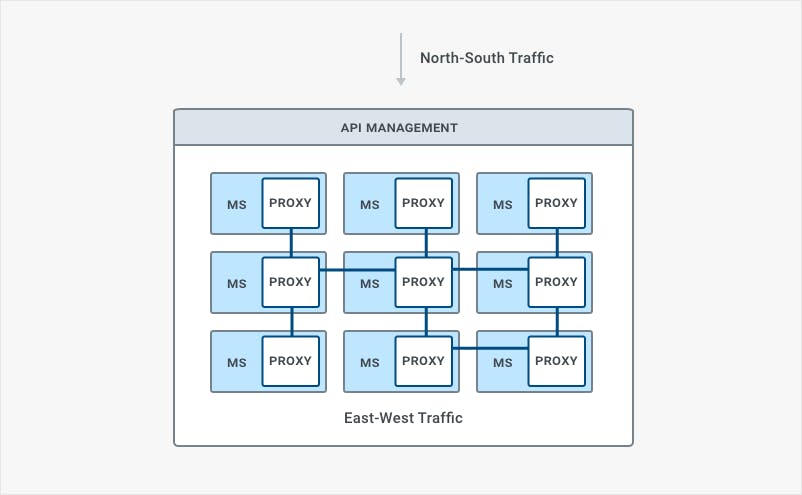
In a short period of time, service APIs went from being primarily an edge interface connecting developers outside of the organization with internal systems to the **glue that binds those internal systems (microservices) into a functioning whole**. Consequently, one of the unavoidable results of microservice-oriented architectures is that internal** communication within the data center****will increase**. Service mesh arose as a potential solution to the **challenges that arise from increased East-West traffic** by providing a different framework for deploying existing technology.
As CTO of Kong, and an active participant in these conversations, I have noticed a common misconception about what service mesh is. In the hope of dispelling confusion and advancing discussions, I want to unequivocally state the following: **service mesh is a pattern, not a technology**.
## **Service Mesh is a Pattern, Not a Technology**
In the same way that microservices are a pattern and not a specific technology, so too is service mesh. Distinguishing between the two sounds more complex than it is in reality. If we think about this through the lens of Object Oriented Programming (OOP), a pattern describes the interface – not the implementation.
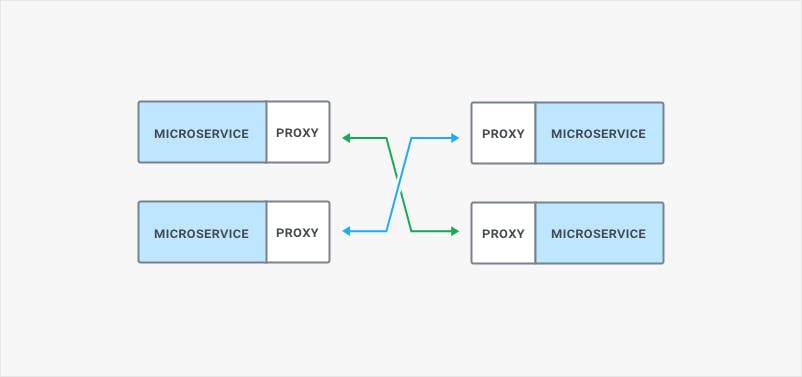
In the context of microservices, the service mesh deployment pattern becomes advantageous due to its ability to better manage East-West traffic via sidecar proxies. As we are decoupling our monoliths and building new products with microservices, the topology of our traffic is also changing from primarily external to increasingly internal. East-West traffic within our datacenter is growing because we are replacing function calls in the monolith with network calls, meaning our microservices must go on the network to consume each other. And the network – as we all know – is unreliable.
What service mesh seeks to address through use of a different deployment pattern are the challenges associated with increased East-West traffic. While with traditional N-S traffic 100ms of middleware processing latency was not ideal but may have been acceptable, in a microservice architecture with E-W traffic it can no longer be tolerated. The reason for this is that the increased east-west traffic between services will compound that latency, resulting in perhaps 700ms of latency by the time the chain of API requests across different services has been executed and returned.
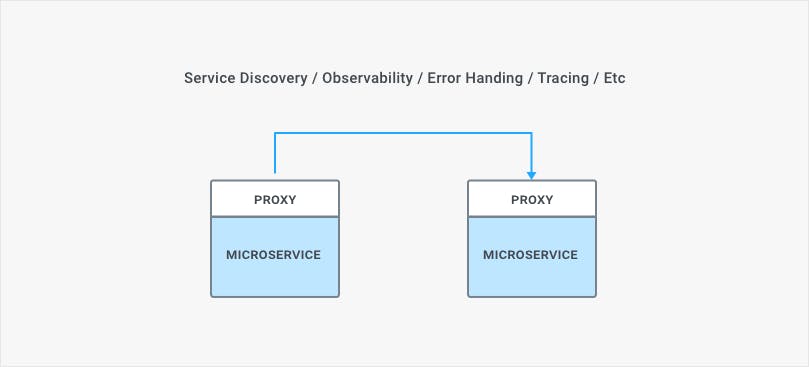
In an effort to reduce this latency, sidecar proxies running alongside a microservice process are being introduced to remove an extra hop in the network. Sidecar proxies, which correspond to data planes on the execution path of our requests, also provide better resiliency since we don't have a single point of failure anymore. However, sidecar proxies bear the cost of having an instance of our proxy for every instance of our microservices, which necessitates a small footprint in order to minimize resource depletion.
From a feature perspective, however, most of what service mesh introduces has been provided for many years by API Management products. Features such as observability, network error handling, health-checks, etc. are hallmarks of API management. These features don't constitute anything novel in themselves, but as a pattern, service mesh introduces a new way of deploying those features within our architecture.
## **Traditional API Management Solutions Can't Keep Up**
Microservices and containers force you to look at systems by prioritizing more lightweight processes, and service mesh as a pattern fills this need by providing a lightweight process that can act as both proxy and reverse proxy to run alongside the main microservice. Why won’t most traditional API Management solutions allow this new deployment option? Because they were born in a monolithic world. As it turns out, API Management solutions built before the advent of Docker and Kubernetes were monoliths themselves and were not designed to work effectively within the emerging container ecosystem. The heavyweight runtimes and slower performance offered by traditional API management solutions were acceptable in the traditional API-at-the-edge use case, but are not in a microservices architecture where latency compounds over time via increased east-west traffic activity. In essence, traditional API management solutions are ultimately too heavyweight, too hard to automate, and too slow to effectively broker the increased communication inherent with microservices.

Since developers understand this, legacy API Management solutions born before the advent of containers have introduced what they call "microgateways" to deal with E-W traffic and avoid rewriting their existing, bloated, monolith gateway solutions. The problem is, these microgateways – while being more lightweight – still require the legacy solution to run alongside them in order to execute policy enforcement. This doesn't just mean keeping the same old heavy dependency in the stack, it also means increased latency between every request. It’s understandable then why service mesh feels like a whole new category. It’s not because it’s new, but rather because the API Management solutions of yesterday are incapable of supporting it.
## **Conclusion**
When you look at service mesh in the context of its feature-set, it becomes clear that it's not very different from what traditional API Management solutions have been doing for years for N-S traffic. Most of the networking and observability capabilities are useful in both N-S and E-W traffic use-case has changed is the deployment pattern, which enables us to run the gateway/proxy as a lightweight, fast sidecar container, but not the underlying feature-set.
The feature-set that a service mesh provides is a subset of the feature-set that API Management solutions have been offering for many years, in particular when it comes to making the network reliable, service discovery and observability. The innovation of service mesh is its deployment pattern, which enables to run that same feature-set as a lightweight sidecar process/container. Too often our industry confuses – and sometimes pushes – the idea that a specific pattern equals the underlying technology, as in the case of many conversations around service mesh.








