The Importance of Zero-Trust Security When Making the Microservices Move

Transitioning to microservices has many advantages for teams building large applications that must accelerate the pace of innovation, deployments and time to market. It also provides them the opportunity to secure their applications and services better than they did with monolithic codebases.
Zero-trust security provides technology teams with a scalable way to make security fool-proof while managing a growing number of microservices and greater complexity. That's right—and although it seems counterintuitive at first—with microservices, we now have the opportunity to secure our applications and all of their services better than we ever did with monolithic codebases. Failure to do so will result in non-secure, exploitable and non-compliant architectures that are only going to become more difficult to secure in the future.
In this blog, we'll first break down why we need zero-trust security, and then explore a real-world zero-trust security example by leveraging the CNCF's Kuma project, a universal service mesh built on top of the Envoy proxy.
Learn more about Zero Trust Network Access or ZTNA and it's overall role in the Zero Trust Architecture.
Before Microservices
In a monolithic application, every resource that we create can be accessed indiscriminately from every other one via function calls because they are all part of the same codebase. Typically, resources are going to be encapsulated into objects (if we use OOP) that will expose initializers and functions that we can invoke to interact with them and change their state.
For example, if we are building a marketplace application (like Amazon.com), there will be resources that identify users and the items for sale, and, once sold, we will generate invoices:

A simple marketplace monolithic application
Typically, this means we will have objects that we can use to either create, delete or update these resources via function calls that can be used from anywhere in the monolithic codebase. While there are ways to reduce access to certain objects and functions (i.e., with public/private/protected access-level modifiers and package-level visibility), usually these practices are not strictly enforced by teams, and our security should not depend on them.
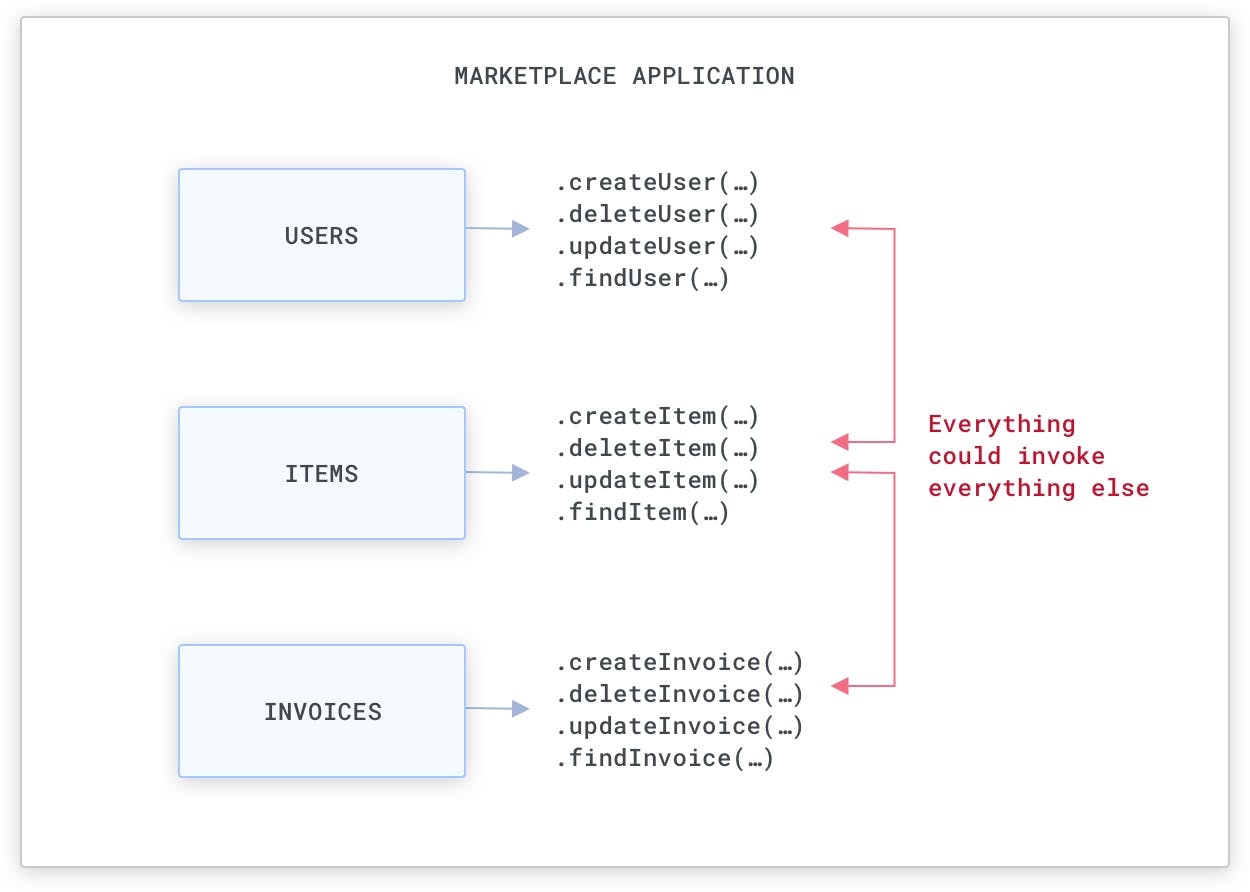
A monolithic codebase is easy to exploit, since resources can be potentially accessed by anywhere in the codebase
With Microservices
With microservices, instead of having every resource in the same codebase, we will have those resources decoupled and assigned to individual services, with each service exposing an API that can be used by another service. Instead of executing a function call to access or change the state of a resource, we can execute a network request.
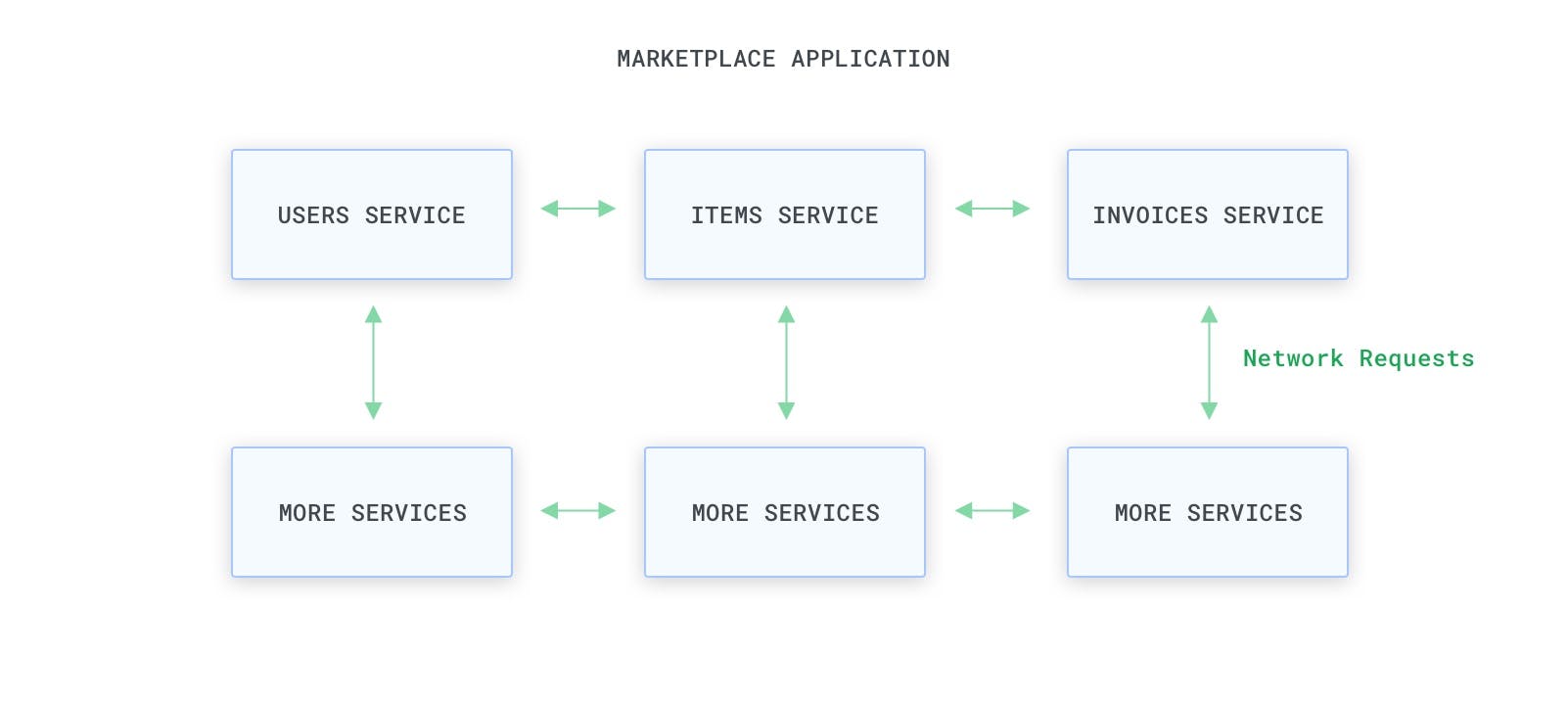
Our resources can now interact with each other via service requests over the network as opposed to function calls within the same monolithic codebase. The APIs can be RPC-based, REST or anything else really.
By default, this doesn't change our situation: without any other barrier in place, every service could theoretically consume the exposed APIs of another service to change the state of every resource. But because the communication medium has changed and it is now the network, we can use technologies and patterns that operate on the network connectivity itself to set up our barriers and determine the access levels that every service should have in the big picture.
Understanding Zero-Trust
To determine security rules over the network connectivity among services, we need to set up permissions, and then check those permissions on every incoming request.
For example, we may want to allow the "Invoices" and "Users" services to consume each other (an invoice is always associated with a user, and a user can have many invoices), and only allow the "Invoices" service to consume the "Items" service (since an invoice is always associated to an item), like in the following scenario:
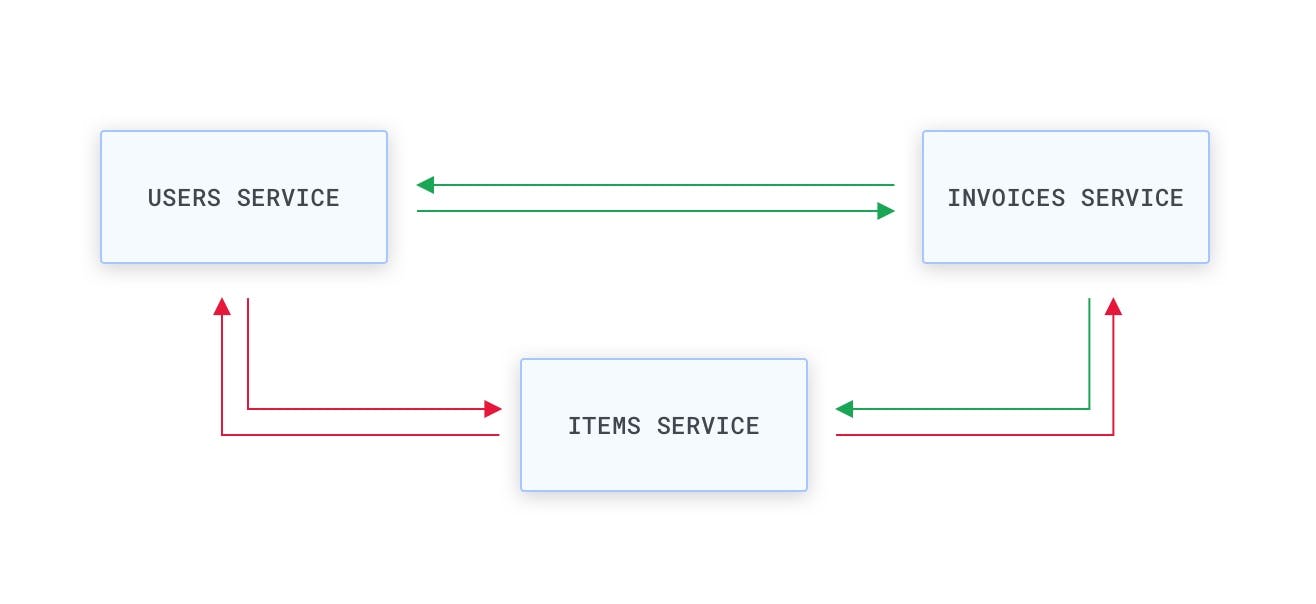
A graphical illustration of connectivity permissions between services. The arrows and their direction determine who can make requests (green) or not (red). For example, the "Items" service cannot consume any other service, but it can be consumed by the "Invoices" service.
After setting up permissions (and we will explore shortly how service mesh can be used to do this), we then need to check them. The component that will check our permissions will have to determine if the incoming requests are being sent by a service that has been allowed to consume the current service. We will implement a check somewhere along the execution path, something like this:
This check can be done by our services themselves or by anything else on the execution path of the requests, but ultimately it has to happen somewhere.
The biggest problem to solve before enforcing these permissions is having a reliable way to assign an identity to each service so that when we identify the services in our checks, they are who they claim to be.
Identity is essential. Without identity, there is no security.
Likewise, when we travel and enter a new country, we show a passport that associates our persona with the document, and by doing so, we certify our identity. Our services also must present a "virtual passport" that validates their identities.
Since the concept of trust is exploitable, we must remove all forms of trust from our systems—and hence, we must implement "zero-trust" security.

The identity of the caller is sent on every request via mTLS.
In order for zero-trust to be implemented, we must assign an identity to every service instance that will be used for every outgoing request. The identity will act as the "virtual passport" for that request, confirming that the originating service is indeed who they claim to be. mTLS (Mutual transport Layer Security) can be adopted to provide both identities and encryption on the transport layer. Since every request now provides an identity that can be verified, we can then enforce the permissions checks.
The identity of a service is typically assigned as a SAN (Subject Alternative Name) of the originating TLS certificate associated with the request, as in the case of zero-trust security enabled by a Kuma service mesh, which we will explore shortly.
SAN is an extension to X.509 (a standard that is being used to create public key certificates) that allows us to assign a custom value to a certificate. In the case of zero-trust, the service name itself will be one of those values that is passed along with the certificate itself in a SAN field. When a request is being received by a service, we can then extract the SAN from the TLS certificate—and the service name from it, which is the identity of the service—and then implement the permission checks knowing that the originating service really is who they claim to be.
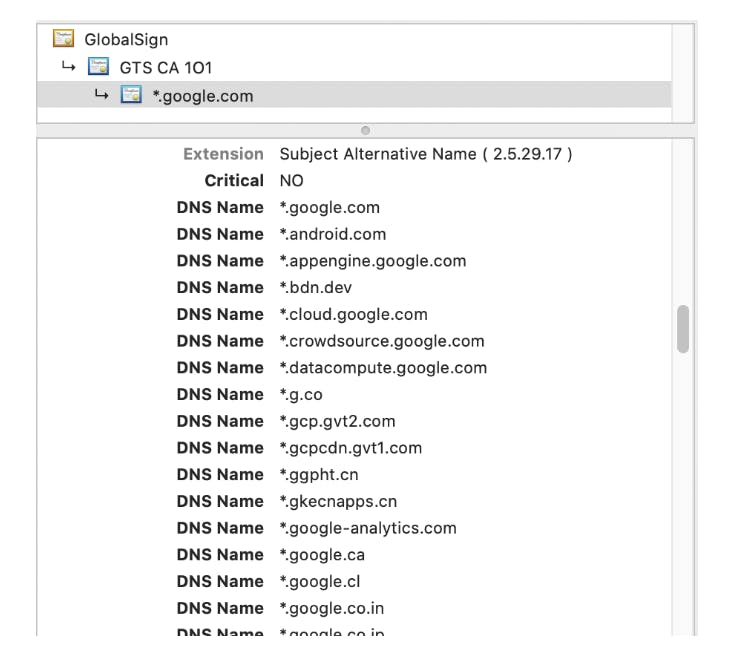
The SAN is very commonly used in TLS certificates and can also be explored by our browser. In the picture above, we can see some of the SAN values belonging to the TLS certificate for Google.com.
Now that we have explored the importance of having identities for our services and we understand how we can leverage mTLS as the "virtual passport" that is included in every request our services make, we are still left with many open topics that we need to address:
- Assigning TLS certificates and identities on every instance of every service.
- Validating the identities and checking permissions on every request.
- Rotating certificates over time to improve security and prevent impersonation.
These are very hard problems to solve because they effectively provide the backbone of our zero-trust security implementation. If not done correctly, our zero-trust security model will be flawed, and therefore insecure.
Moreover, the above tasks must be implemented for every instance of every service that our application teams are creating. In a typical organization, this includes both containerized and VM-based workloads running across one or more cloud providers, perhaps even in our physical datacenter. The biggest mistake any organization could make is asking its teams to build these features from scratch every time they create a new application. The resulting fragmentation in the security implementations will create unreliability in how the security model is implemented, making the entire system insecure.
Service Mesh to the Rescue
Service mesh is a pattern that implements modern service connectivity functionalities in such a way that does not require us to update our applications to take advantage of them. Service mesh is typically delivered by deploying data plane proxies next to every instance (or Pod) of our services and a control plane that is the source of truth for configuring those data plane proxies.
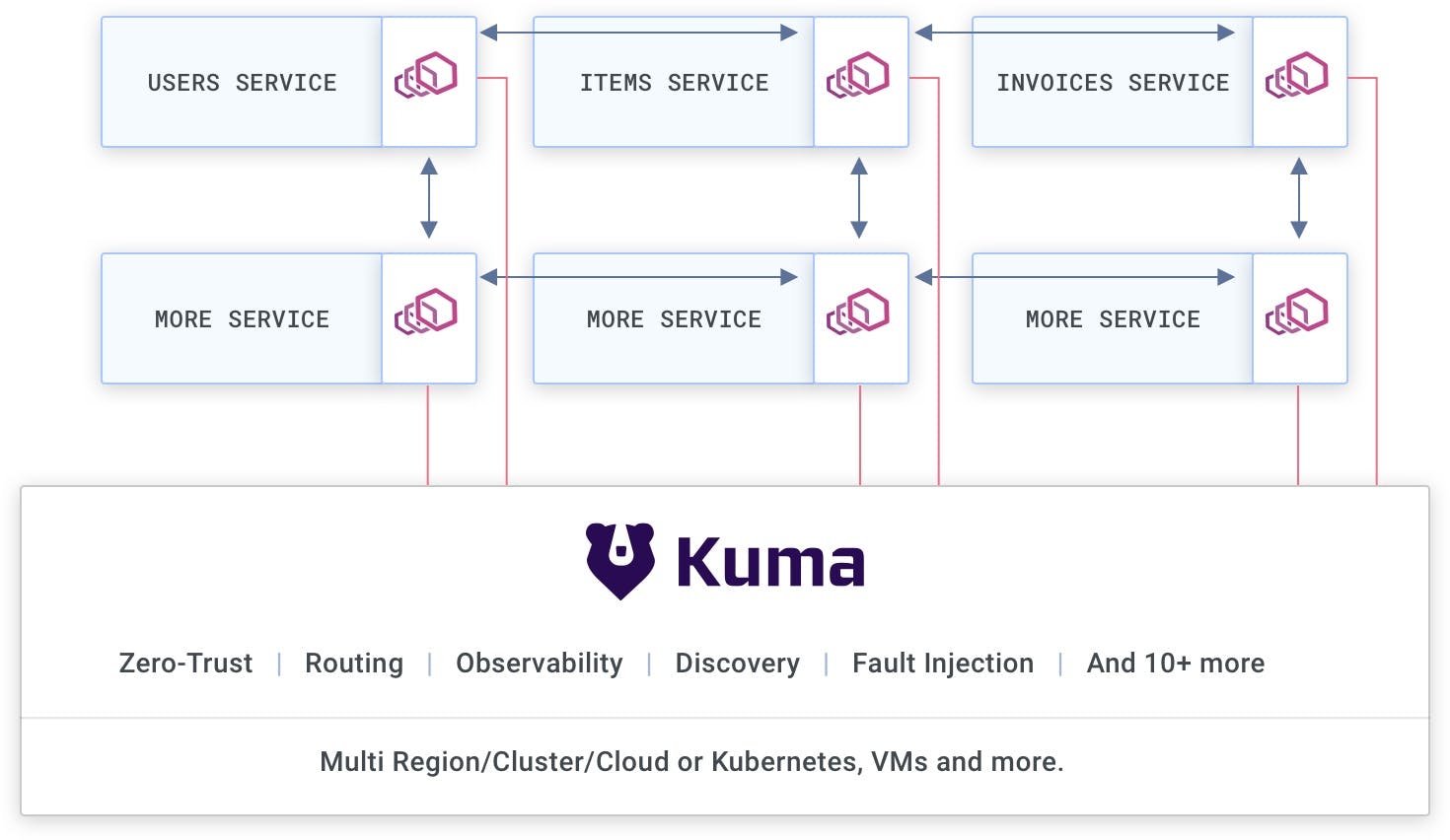
In a service mesh, all the outgoing and incoming requests are automatically intercepted by the data plane proxies (Envoy) that are deployed next to each instance of each service, while the control plane (Kuma) is in charge of propagating the policies we want to set up (like zero-trust) to the proxies. The control plane is never on the execution path of the service-to-service requests, only the data plane proxies are.
The service mesh pattern is based on the idea that our services should not be in charge of managing the inbound or outbound connectivity. Over time, services written in different technologies will inevitably end up having various implementations, and therefore, a fragmented way to manage that connectivity ultimately will result in unreliability. Also, the application teams should focus on the application itself, not on managing connectivity since that should ideally be provisioned by the underlying infrastructure. Therefore, service mesh not only gives us all sorts of service connectivity functionality out of the box, like zero-trust security, but also makes the application teams more efficient while giving the infrastructure architects complete control over the connectivity that is being generated within the organization.
Likewise, just as we didn't ask our application teams to walk into a physical data center and manually connect the networking cables to a router/switch for L1-L3 connectivity, today we don't want them to build their own network management software for L4-L7 connectivity. Instead, we want to use patterns like service mesh to provide that to them out of the box.
Zero-Trust via Kuma
Kuma is an open source service mesh (first created by Kong and then donated to the CNCF) that can run across multi-cluster, multi-region and multi-cloud deployments across both Kubernetes and virtual machines (VMs). It provides more than 10 policies that we can apply to service connectivity (like zero-trust, routing, fault injection, discovery, multi-mesh, etc.), and has been engineered to scale in large distributed enterprise deployments. Kuma natively supports the Envoy proxy as its data plane proxy technology, and ease of use has been a huge focus of the project since day one.
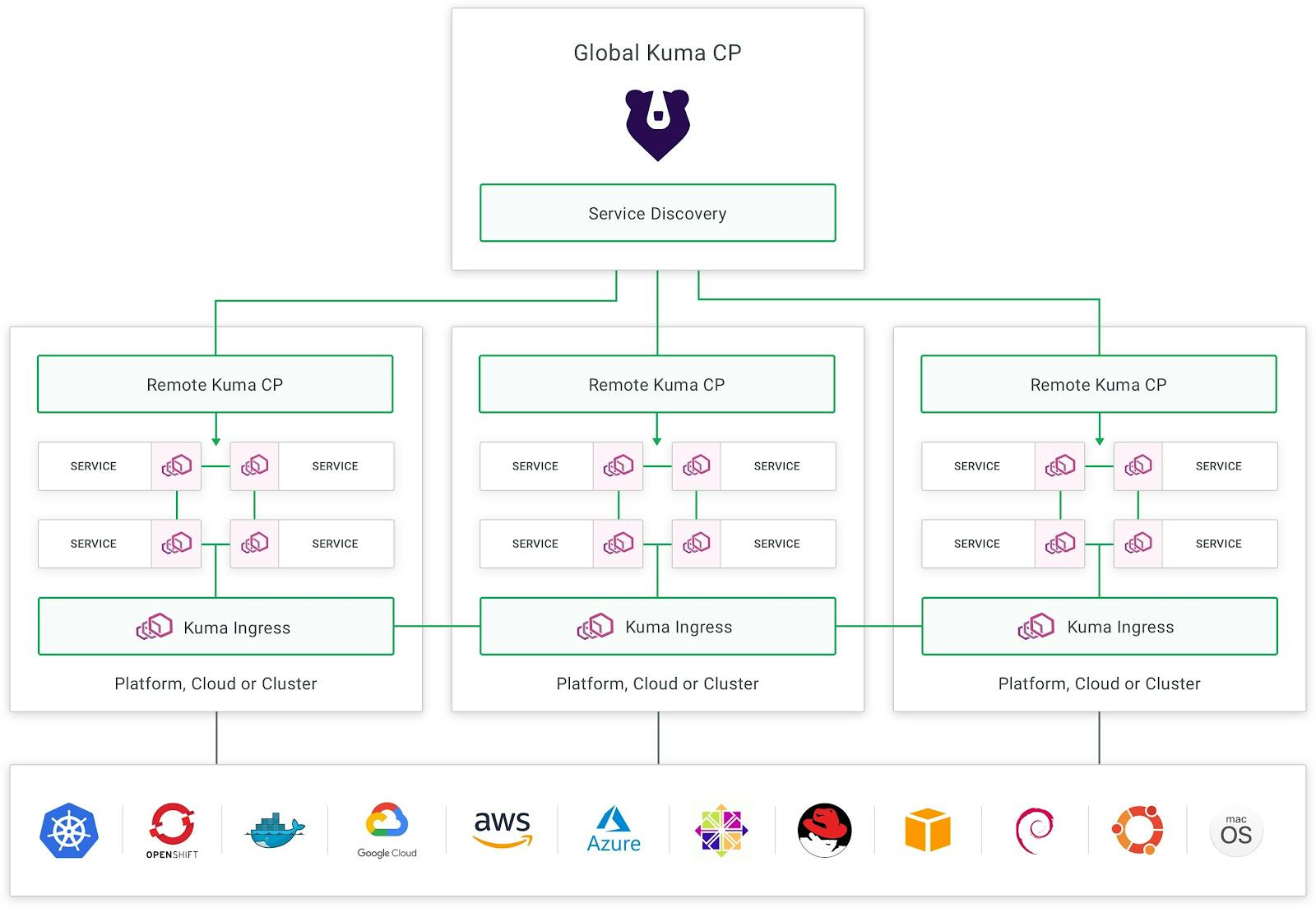
Kuma can natively run a distributed service mesh across clouds and clusters - including hybrid Kubernetes + VMs - via its multi-zone deployment mode.
With Kuma, we can deploy a service mesh that can deliver zero-trust security across both containerized and VM workloads in a single or multiple cluster setup. To do so, we need to first:
- Download and install Kuma at: kuma.io/install.
- Start our services and start `kuma-dp` next to them (in Kubernetes, `kuma-dp` is automatically injected). We can follow the getting started instructions in the installation page to do this for both Kubernetes and VMs.
Then, once our control plane is running and the data plane proxies are successfully connecting to it from each instance of our services, we can execute the final step:
3. Enable the mTLS and Traffic Permission policies on our service mesh via the "Mesh" and "TrafficPermission" Kuma resources.
In Kuma, we can create multiple isolated virtual meshes on top of the same deployment of service mesh, which is typically used to support multiple applications and teams on the same service mesh infrastructure. To enable zero-trust security, we first need to enable mTLS on the "Mesh" resource of choice by enabling the "mtls" property.
In Kuma, we can decide to let the system generate its own certificate authority (CA) for the "Mesh" or we can set our own root certificate and keys. The CA certificate and key will then be used to automatically provision a new TLS certificate for every data plane proxy with an identity, and it will also automatically rotate those certificates with a configurable interval of time. In Kong Mesh, we can also talk to a third-party PKI (like HashiCorp Vault) to provision a CA in Kuma.
For example, on Kubernetes, we can enable a "builtin" certificate authority on the default mesh by applying the following resource via "kubectl" (on VMs, we can use Kuma's CLI "kumactl"):
This resource will enable mTLS on our "default" mesh and provision a new CA out of the box, and it will rotate our data plane proxy certificate every day automatically for us. All of this can be configured in this one resource.
In the permission above, we are effectively enabling every service to be able to consume every other service. We can determine in a more or less fine-grained way how our permissions should work using one or more Traffic Permission resources in Kuma.
Conclusion
With the adoption of microservices, we are compartmentalizing our resources in individual services that expose an interface (API) over the network, away from having every functionality in one individual monolithic code base where everything is accessible by every other resource. This change creates an opportunity for augmenting the networking layer in order to create a zero-trust security model - which is necessary in a microservices world - to apply both identities and permissions to our services and their connectivity, essentially improving the overall security of our applications. Implementing a zero-trust security model can be challenging since there are many activities that have to be implemented across every service, cloud and cluster where our applications are running, like issuing TLS certificates for each instance of our services, rotating the certificates, assigning connectivity permissions and more.
With the service mesh pattern, we can easily implement a zero-trust security model that is reliable and portable across every application that we create, while improving the efficiency of our application teams that now become consumers of the zero-trust model, and therefore, can allocate more time on their primary goals (building the services and the applications).
This content was originally published in InfoWorld