[Kong Mesh](https://konghq.com/kong-mesh)Kong Mesh (and [Kuma](https://kuma.io)Kuma, the open source project upon which Kong Mesh is built) supports multiple zones and meshes. What is the difference between a zone and a mesh, though? And when should one use a zone versus a mesh or vice versa? By the time you're done reading this blog post, you'll have a better understanding of the role of zones and meshes and where each of them fit into a Kong Mesh deployment.
Although this blog post refers only to Kong Mesh, everything also applies to Kuma unless noted otherwise.
Let's start with an in-depth discussion of both zones and meshes.
[**Webinar On-Demand: Observability, Service Mesh and Troubleshooting Distributed Services**](https://konghq.com/webinars/observability-with-service-mesh)**Webinar On-Demand: Observability, Service Mesh and Troubleshooting Distributed Services**
## **A Zone Is a Model of Physical Connectivity**
A **zone** is a model of physical connectivity. All data plane proxies (DPs) **must be able to communicate directly** with other DPs in the same zone. Being in the same zone does not imply that two DPs *will* communicate, only that they are *able* to communicate with each other. Other factors (services and policies, for example) can determine whether two DPs in the same zone will communicate.
A zone does not limit connectivity; rather, it provides structure around the flow of connectivity. Within a zone, DPs can communicate; between zones, communication flows between each zone's Zone Ingress. The Zone Ingresses must be able to communicate with each other (in a cloud environment, this may mean using a cloud load balancer in front of each Zone Ingress). Unless otherwise configured via policy, services in one zone can communicate with services in another zone without limitation.
Zones allow platform DevOps to model things like:
- - **Cloud providers (different zones for different cloud providers)**: You would use a separate zone for each cloud provider for a multi-zone deployment that spans two cloud providers. This is especially true when you are using private (non-routable) addresses in each cloud provider, as the presence of network address translation (NAT) within a zone is a definite no-no.
- - **Regions within a single cloud provider**: Within a single cloud provider, we could use zones to represent different regions (on AWS, one zone could represent us-east-1 while another zone could represent us-west-2, for example). While NAT across regions isn't typically a concern, platform DevOps or architects may want the flexibility to influence traffic routing between regions, which is possible through multiple zones and locality-aware load balancing.
- - **Different physical data centers**: For deployments not on a cloud provider but in one or more self-managed/self-hosted data centers, we would use zones to represent other physical locations. The key drivers here would be the presence of NAT or the desire to influence traffic routing between the various on-premises locations.
Because of the connectivity requirements (every DP should be able to communicate with every other DP in the zone), zones could also combine [Kubernetes](https://konghq.com/blog/learning-center/what-is-kubernetes)Kubernetes-based and VM/bare metal-based workloads in a single deployment. Kubernetes network configurations will typically use NAT on the Pod IPs, interfering with the ability of non-Kubernetes DPs to communicate with Kubernetes DPs. This necessitates putting Kubernetes in a separate zone from VM/bare metal-based DPs. This is also true for combining multiple Kubernetes clusters in a single deployment; again, each Kubernetes cluster is typically in a separate zone. If the Pod IPs are routable among multiple clusters, the requirement to use separate zones goes away (although you may wish to use separate zones for other reasons).
[**Technical Guide: A GitOps Approach to Kong Gateway and Kong Mesh**](https://konghq.com/technical-guide/a-gitops-approach-to-kong-gateway-and-kong-mesh-2)**Technical Guide: A GitOps Approach to Kong Gateway and Kong Mesh**
## **A Mesh Is a Logical Boundary**
A **mesh** is a logical boundary intended for use in multi-tenant deployments. Platform DevOps can use multiple meshes to provide numerous, independent, completely isolated islands of connectivity for separate teams, separate applications or separate security domains (or any other form of logical isolation needed). Each mesh is a separate policy enforcement domain, meaning that policy applies to a specific mesh and each mesh has its own policies, even if the meshes share a common control plane.
Unlike a zone, a mesh does limit connectivity. Services in one mesh cannot communicate with services in another mesh. Traffic must exit the originating mesh and re-enter the destination mesh. As such, inter-mesh traffic is subject to intervening traffic control mechanisms like firewalls, network address translation (NAT) devices, traffic gateways, access control lists and the like.
Meshes allow platform DevOps to model logically separate domains to accommodate requirements like:
- - **Providing separate environments for different teams or applications**: If platform DevOps want separate teams or applications to have separate environments with their own policies, using multiple meshes can address this requirement.
- - **Accommodating different per-mesh configurations**: Perhaps some applications require mTLS, while others do not. Since mTLS is a per-mesh configuration, using separate meshes allows platform DevOps to meet this need.
- - **Hosting separate security domains**: In the event platform DevOps wish to host multiple security domains, such as a demilitarized zone (DMZ) and an internal zone, on the same control plane, using multiple meshes can allow additional security controls on inter-mesh traffic.
[**eBook: The Importance of Zero-Trust Security When Making the Microservices Move**](https://konghq.com/ebooks/the-importance-of-zero-trust-security-when-making-the-microservices-move)**eBook: The Importance of Zero-Trust Security When Making the Microservices Move**
## **Interactions Between Zones and Meshes**
Now that you understand what zones and meshes address, let's discuss how zones and meshes interact when combined in a single deployment. There are two key questions this section answers:
- - Can multiple meshes be present in a single zone?
- - Can a single mesh span multiple zones?
The answers to these questions will help you understand how these two building blocks of Kong Mesh interact with each other.
First, **multiple meshes may be present in a single zone**. This could represent, for example, a single Kubernetes cluster with multiple meshes to provide isolation for multiple teams, applications or security domains. Even though all the DPs in this example are *capable* of communicating with each other (because they are all in the same zone), it's important to note that DPs in separate meshes *will not* communicate with each other (the meshes provide logical separation).
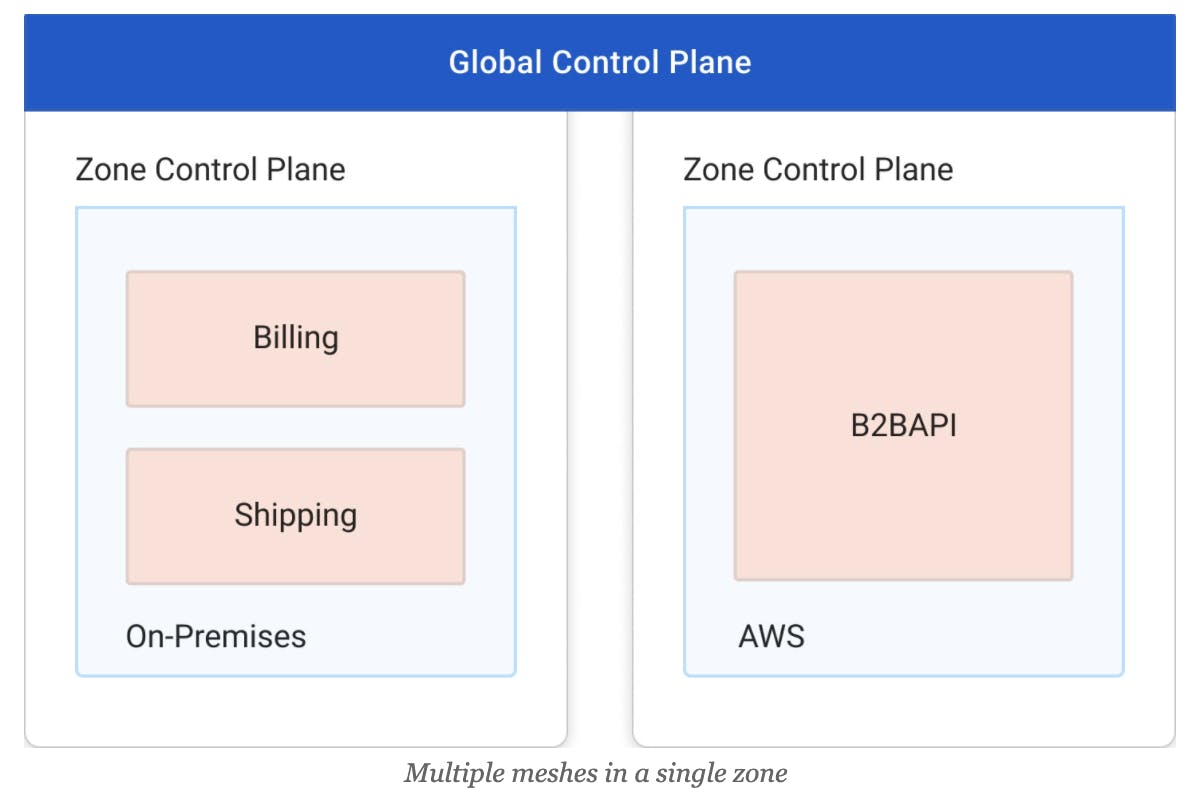
Here's a diagram to graphically illustrate the idea of multiple meshes in a zone. Two zones are present; they are used to model domains of physical connectivity. Within the "On-Premises" zone, two different meshes are present: one for the Billing team and their applications, and another for the Shipping team and their applications. Although data plane proxies in the Billing and Shipping meshes are present in the same zone and can communicate, they are logically separated by being in two different meshes. Traffic between the Billing and Shipping meshes would need to exit the originating mesh and re-enter the destination mesh. The same is true for traffic from either the Billing or Shipping mesh that's headed for the B2BAPI mesh found in the "AWS" zone.
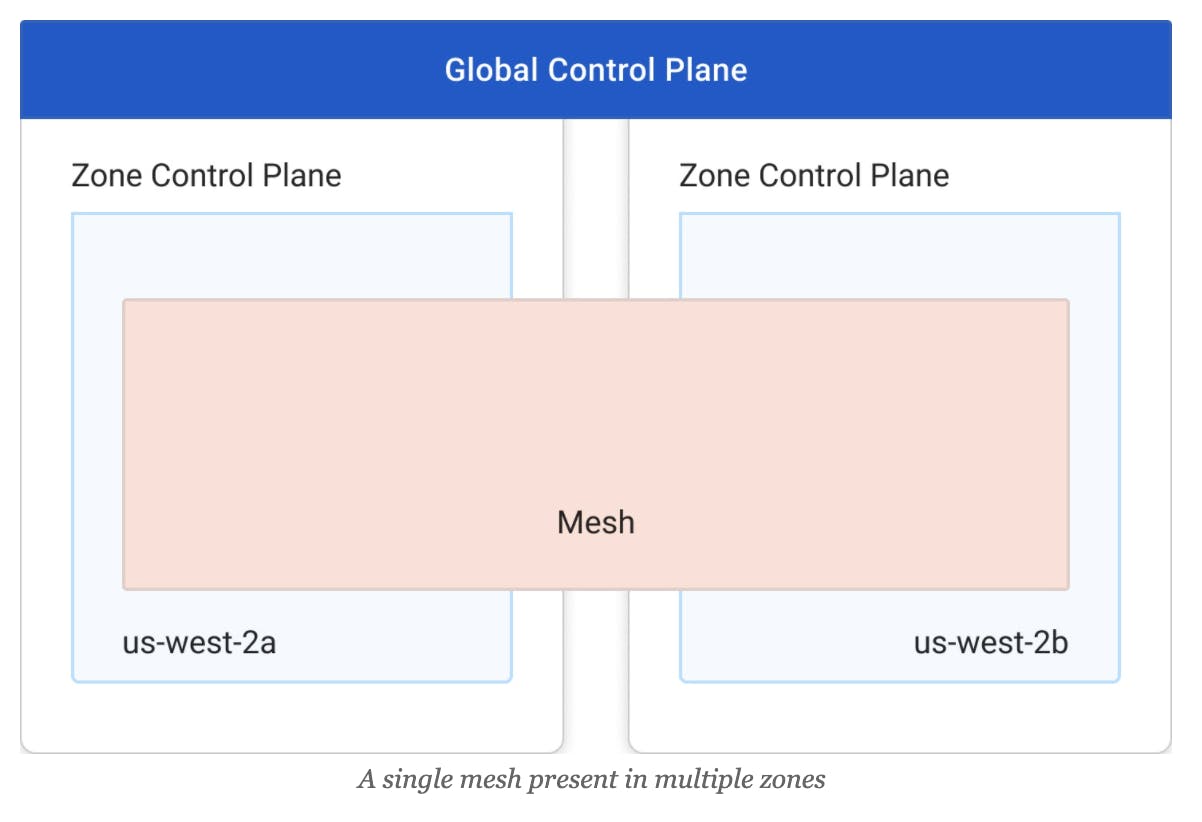
Second, **a single mesh may be present in multiple zones**. This could represent, for example, multiple Kubernetes clusters (each in their own zone), but with separate meshes for logical isolation across all the different Kubernetes clusters. As noted earlier, DPs in different meshes *will not* communicate with each other, regardless of their zone location.
This diagram illustrates the idea of a mesh present in multiple zones. In this example, separate zones describe availability zones in the US West 2 region of AWS. There are various reasons we might take this approach; limiting cross-AZ traffic (and the resulting charges) via locality-aware load balancing might be one reason. A single mesh is present in both zones.
## **When to Use Multiple Zones, Multiple Meshes or Both**
The answer to the question, "When should I use multiple zones or multiple meshes?" really comes back to the primary purpose for zones and meshes.
Use multiple zones when you want to inform Kong Mesh that certain groups of data plane proxies cannot communicate with each other. One excellent example mentioned already is using separate zones for each Kubernetes cluster. Typically, Kubernetes networking is set up so that pod IPs are not routable. Therefore, data plane proxies in one cluster can't communicate with those in another cluster. In this situation, the use of zones helps inform Kong Mesh that traffic must flow through a Zone Ingress, which would be exposed to allow "external" (external to the cluster) traffic. Other examples of when to use multiple zones would include modeling connectivity around cloud provider regions or availability zones, or modeling connectivity between and among on-premises workloads and cloud provider-based workloads.
We should use multiple meshes when it's necessary to logically separate workloads for some reason. This may accommodate organizational requirements, such as logically separating workloads managed by different teams. Alternatively, this may accommodate security requirements, such as logically separate workloads that should run in different security domains (a topic for a future blog to discuss in more detail!).
Ultimately, the use of multiple zones or multiple meshes is independent of the other. Platform architects should feel free to use multiple zones as needed to model physical network topologies while also using multiple meshes as necessary to provide the required logical separation as dictated by organizational, business or security requirements. The use of multiple zones does not preclude using multiple meshes, nor vice versa.
If you're interested in Kong Mesh or Kuma, try [installing Kuma](https://kuma.io/install/latest)installing Kuma or [requesting a demo of Kong Mesh](https://konghq.com/request-demo-kong-mesh)requesting a demo of Kong Mesh.
We'd love to help answer your questions in [the Kuma Slack community](https://kuma-mesh.slack.com)the Kuma Slack community.








