



_Blog_
[__Streamline AI Usage with Token Rate-Limiting & Tiered Access
__](/blog/engineering/token-rate-limiting-and-tiered-access-for-ai-usage)__Streamline AI Usage with Token Rate-Limiting & Tiered Access
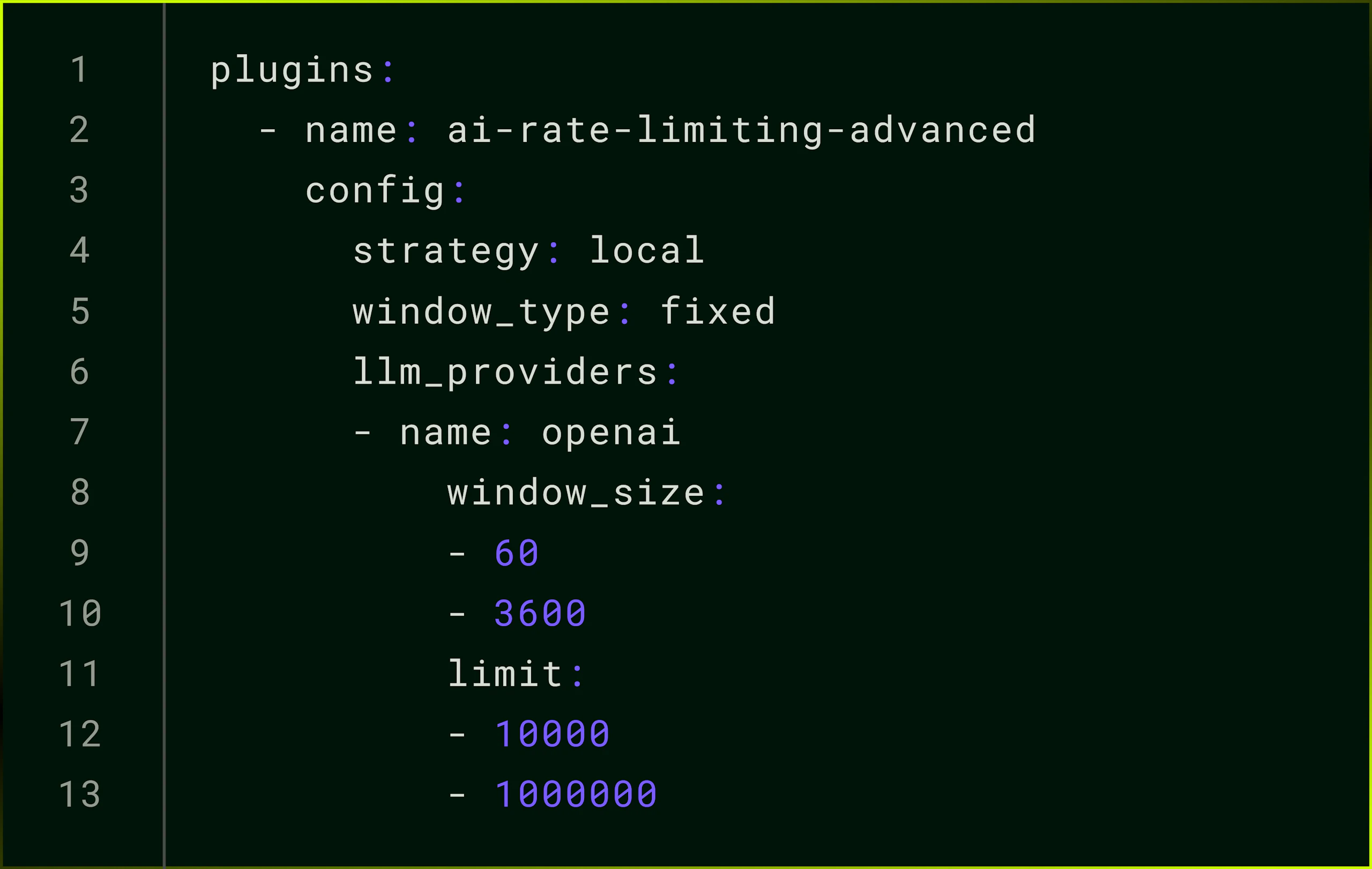
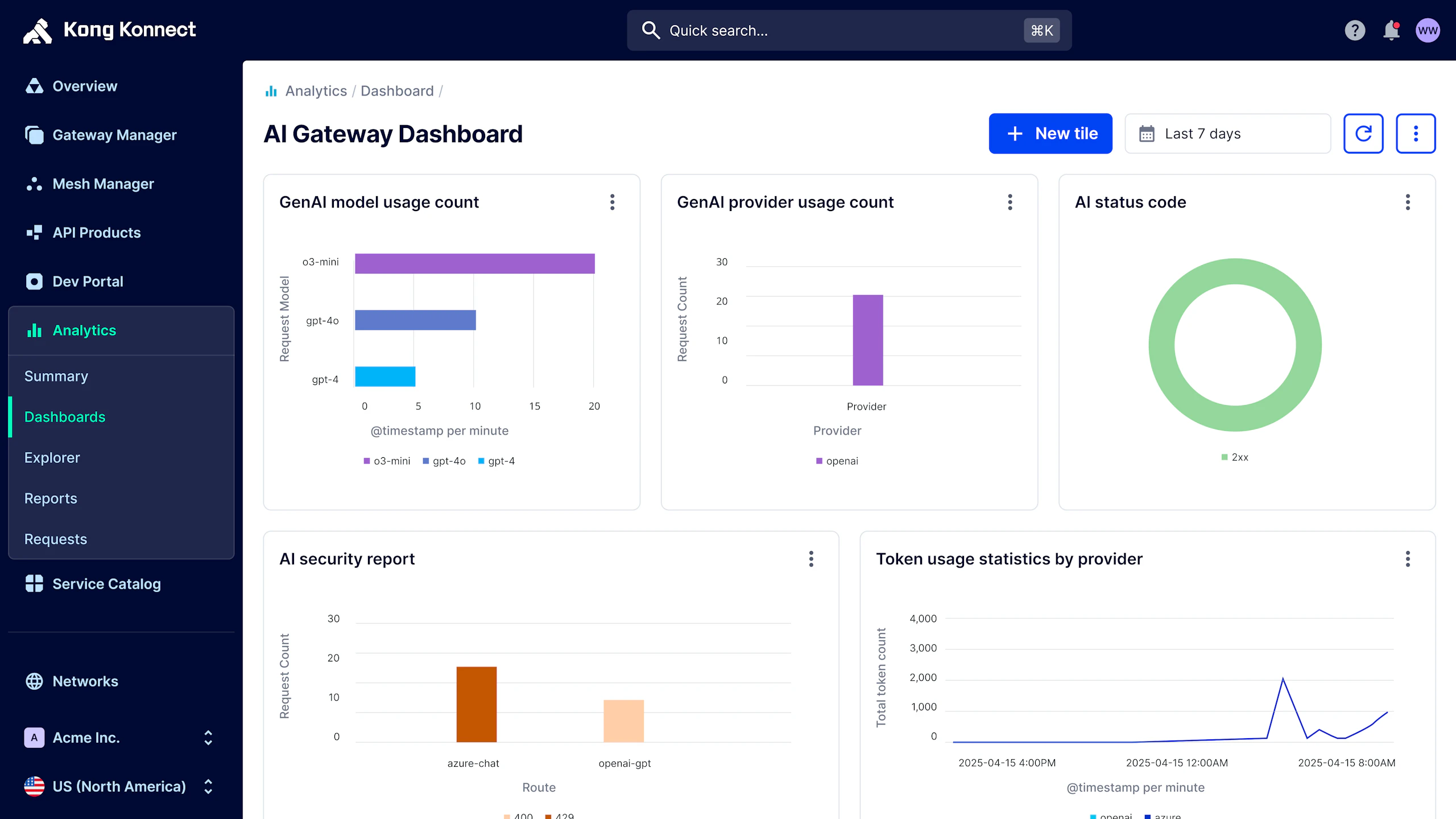
__Learn how to use Konnect and the AI Gateway to streamline LLM token consumption and control AI costs.