*This blog and video were co-created by David La Motta (Kong), Ross McDonald (Kong) and Alex Dworjan (Red Hat).*
**Murphy's Law**
*“Anything that can go wrong will go wrong.”*
To us mortals, that means we should try to prepare for the worst and hope for the best.
Disaster Recovery (DR) is crucial to every organization. Business continuity is important whether you live in an area prone to natural disasters or need to prepare for unseen events like a data center outage. But how do you ensure that the changes behind the scenes don't impact the end user?
Red Hat Ansible Automation Platform ([AAP](https://www.redhat.com/en/technologies/management/ansible)AAP) is the automation tool of choice for many enterprises. AAP does various tasks, such as enforcing security policies, deploying applications and provisioning resources. It’s a critical—even vital—component for most organizations.
In this post and the video below, we'll discuss leveraging a combination of [Kong Gateway](https://konghq.com/kong)Kong Gateway and [Kong Mesh](https://konghq.com/kong-mesh)Kong Mesh to maintain business continuity for the Ansible Automation Platform. AAP can stand up a replica of one or more AAP production clusters in the event of a disaster. However, you might have Service Level Agreements to maintain or regulatory compliance requirements to meet that demand for an always-on DR AAP cluster. Whatever the case might be, this exercise expects at least one DR AAP cluster to be active. It can be active all the time or provisioned on the fly—the choice is yours, based on your needs.
## The Challenge: Load Balancing
The figure below shows a 10,000-foot overview of the scenario used in this post. Imagine a user-facing application, which leverages AAP APIs to invoke a CLI-based legacy application. Ansible Automation Program clusters should—at least—sit behind a load balancer, so that our user-facing application is oblivious to where API requests are served from. If the load balancer detects the production site is down, incoming requests are routed to the DR site.
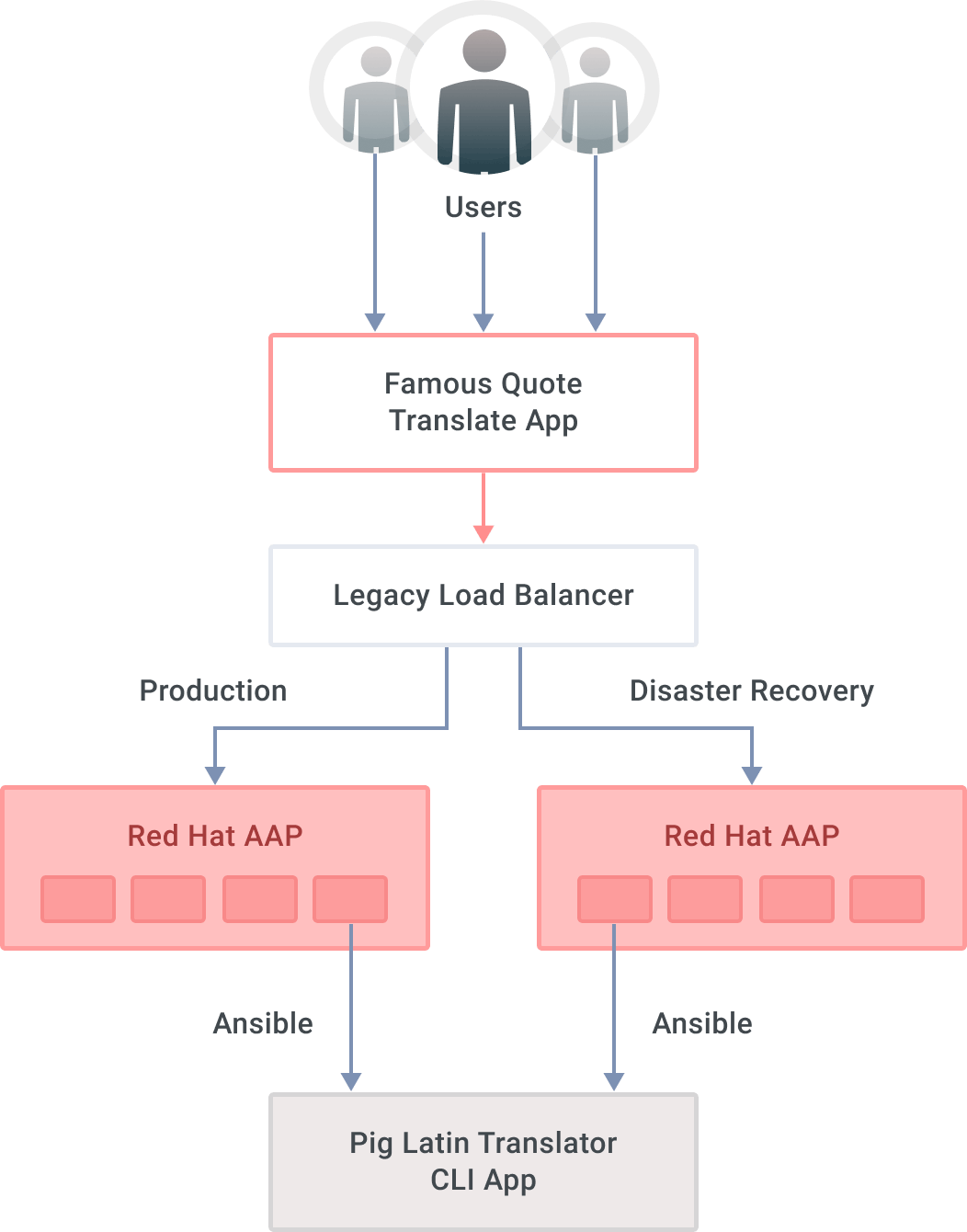
For this exercise, our user-facing application is a Python script that grabs notable quotes from the Internet and translates them into Pig Latin. It displays both the original and the translations on the screen in a never-ending loop.
We have named that application the Famous Quote Translate App. The actual translator (i.e., our [legacy application](https://konghq.com/blog/legacy-application-api-plugin)legacy application) is a Perl program that we can only access via a CLI, so you have to SSH into the machine where it exists to run it. We have two AAP mirror clusters, production and DR, with a playbook that invokes the actual translation. While leveraging our custom Python app to showcase this AAP DR scenario, we could replace that layer with an ITSM, such as ServiceNow or any other application that leverages AAP's REST APIs.
While there is technically nothing wrong with leveraging a traditional load balancer to route requests between two sites, it is pretty vanilla. A legacy load balancer does not pack the same punch as a modern, [cloud native API gateway and service mesh combination](https://konghq.com/blog/zerolb)cloud native API gateway and service mesh combination. Sure, you could cluster those legacy load balancers, but complexity and cost will increase as a result while remaining bland.
A data center or a public cloud region outage is not a matter of "if" but rather "when" it will happen—you recall Murphy's law, right? The outage can be triggered manually, for example, by organizations that routinely test their disaster recovery preparedness (*hint: if you are not doing this today, you definitely should*).
In an outage, a monitoring tool might trigger a set of automation steps to provision resources. That way, a business can continue operating in the face of adversity. That is, of course, if your monitoring tool isn't in the same data center that went belly up. Or, an outage might just happen, leaving little-to-no time to react by hand or through automation.
### *An outage is one big problem, especially because everything pointing to a production AAP cluster now needs to point to a DR AAP cluster. *
Relying on an inflexible legacy load balancer strategy exacerbates the problem, as depicted above. If that load balancer layer fails, all those AAP API endpoints that custom applications or ITSMs were using become obsolete in a matter of seconds, if not less. The same is true for monitoring tools providing remediation via automation. At the end of the day, all those AAP API endpoints that once were backed by a live AAP cluster now lay in a dark, powerless data center.
## The Pièce de Résistance: Continued Operations
Herein lies the conundrum: There is no time to replace the myriad of API calls to an AAP cluster once an outage takes place. However, despite the outage, all those API calls must continue working. So how do we solve that problem?
This new solution is a two-step process involving Kong Gateway and Kong Mesh in front of Ansible Automation Platform clusters.
**The first layer of protection**—**and indirection**—**takes the form of the Kong Gateway.** This API gateway serves, as its name suggests, as the pathway to all those AAP APIs that an organization uses. Details on the scalability and resiliency of this layer are out of scope for this blog but rest assured that[ it can be done.](https://docs.konghq.com/enterprise/2.5.x/deployment/hybrid-mode) it can be done. What matters is the [API gateway](https://konghq.com/blog/learning-center/what-is-an-api-gateway)API gateway provides an ingress point into the Ansible Automation Platform that doesn't change, outage or not. Furthermore, Kong’s [about 100 plugins](https://docs.konghq.com/hub)about 100 plugins extend its functionality.
**Kong Mesh provides the second layer of protection.** A [service mesh](https://konghq.com/blog/learning-center/what-is-a-service-mesh)service mesh adds many capabilities to your applications, one of them being service failure recovery. In a [multi-zone deployment](https://kuma.io/docs/latest/deployments/multi-zone)multi-zone deployment of Kong Mesh, [locality-aware load balancing](https://kuma.io/docs/latest/policies/locality-aware)locality-aware load balancing allows for prioritizing traffic to services in one zone over others. If one service in a zone fails, the mesh will reroute traffic as needed. Detecting failure and routing requests are provided transparently and seamlessly to the end user. That way, if our AAP production zone service is down, Kong Mesh will route any new incoming requests to the AAP DR zone service instead. The capabilities of the service mesh replace the legacy load balancer layer.
Two new components visible in the diagram below are the Kong Gateway control plane and the Kong Mesh control plane. Each is responsible for enforcing configuration to their respective data plane. These puzzle pieces are deployed in [Kubernetes](https://konghq.com/blog/learning-center/what-is-kubernetes)Kubernetes environments, so there is scalability built into those platforms.
If you are wondering how one, or both, of the control planes being unavailable would affect this whole setup, we commend you for your keen observation. The truth of the matter is the setup would continue working if both control planes were down for whatever reason. The only callout to make is that no configuration could be applied to the data planes until the control planes came back online.
The graph below illustrates the new architecture at a high level.
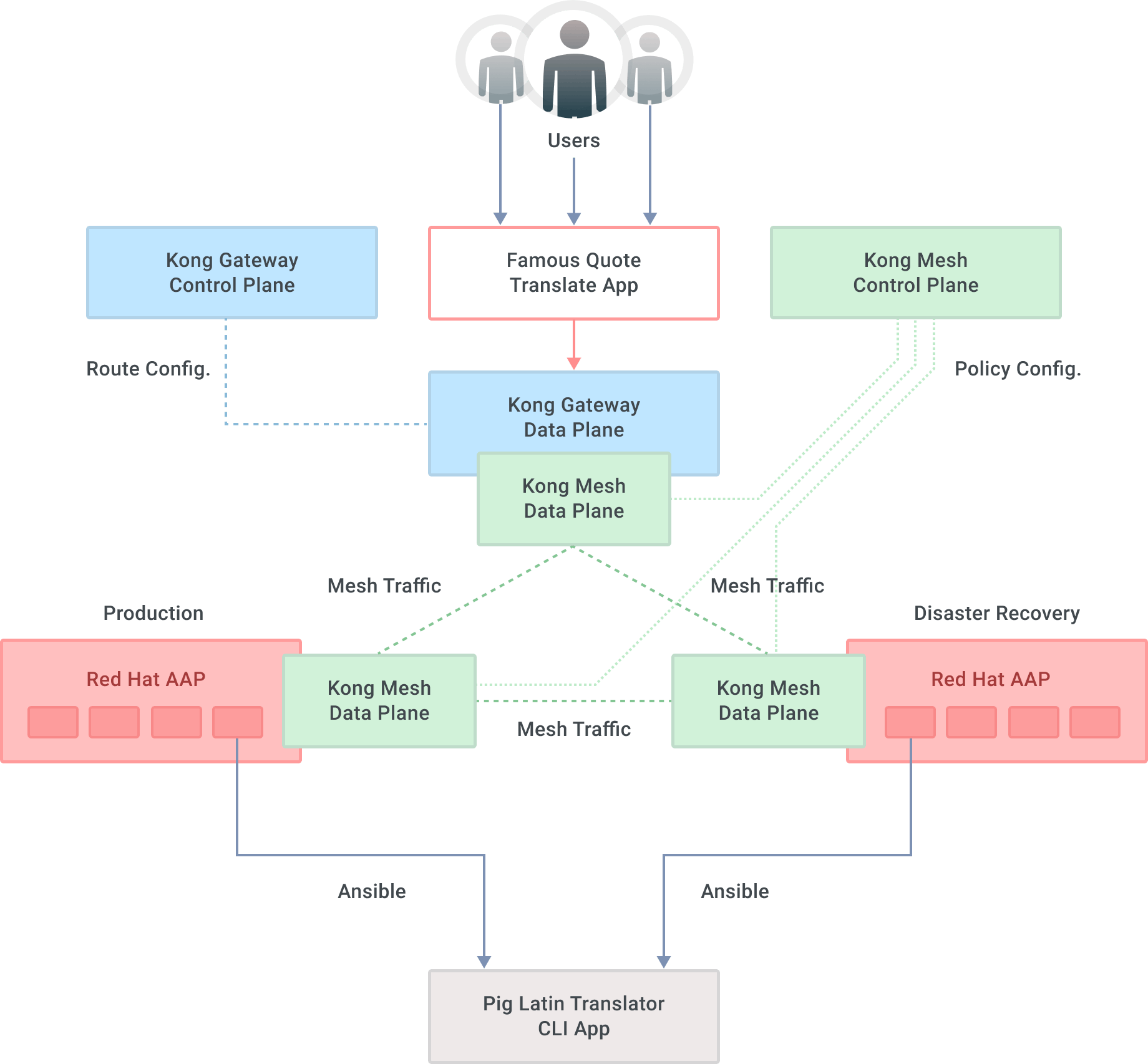
With the one-two punch of Kong Gateway and Kong Mesh, the Ansible Automation Platform can continue doing what it does best, even if an outage takes place. Moreover, tools invoking AAP via its API need not change because of Kong Gateway's resilient, fault-tolerant ingress endpoints.
## Proof Is in the Pudding: Zero-Touch Ansible Automation Disaster Recovery in Action
To illustrate how all this works in practice, we have two AAP clusters running in two different regions of the Azure public cloud, East US2 and West US2, with Kong Gateway running in the Central US1 region. We'll call the East AAP cluster production and the West AAP cluster DR. The Kong Gateway control plane runs in an EKS cluster in AWS, and the Kong Mesh control plane runs in a GKE cluster in GCP. Those clusters could be Red Hat OpenShift clusters, so you are ready to go if you have access to that in your environments.
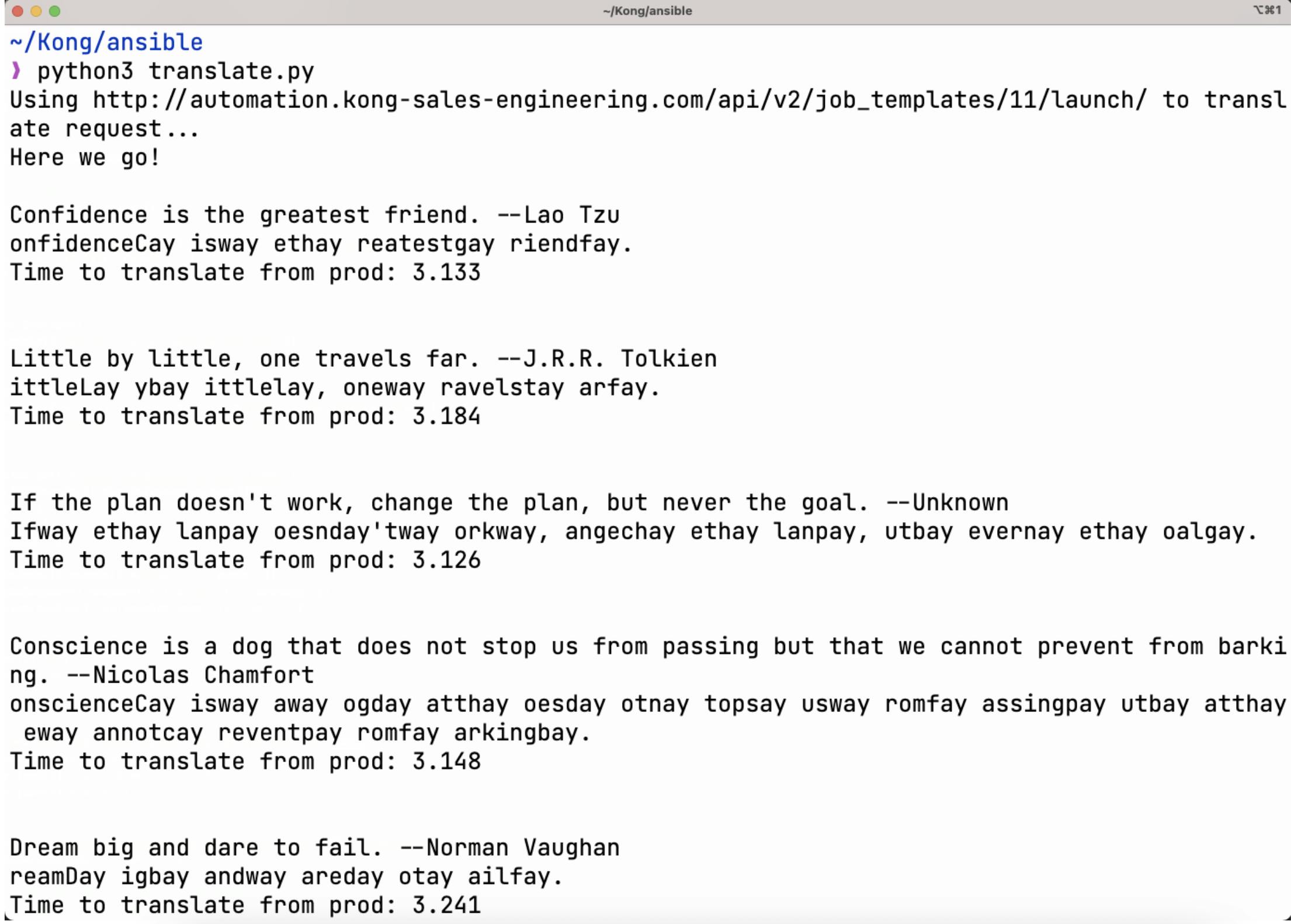
Our critical workload is the legacy Pig Latin Translator CLI App that we invoked through our Famous Quote Translate App script. The app, in turn, leverages the AAP API and fulfills the actual translation through an Ansible playbook that executes Perl code to do the actual translation. When requesting a translation via the Kong Gateway API, we get back text translated into Pig Latin, and—as a user—we are not concerned where the request was served from.
We simulate the production AAP cluster going down by stopping the Kong Mesh Data Plane Proxy in the AAP production cluster—removing it from the service mesh. If you recall, our Python script translates quotes in a forever-loop, so there is no time to change API endpoints. Because Kong Mesh is doing its magic, the DR AAP cluster in Azure West serves new requests. As you can see in the recorded demonstration, the time to execute a translation nearly doubles when executing requests from the DR AAP cluster in the West, but the execution continues to be seamless. In addition, you can see the jobs executing in the West cluster instead of the one in the East, as seen in the AAP user interfaces.
So, there you have it: seamless, zero-touch DR in action. It doesn't get any better than this. Actually, we take that back. It does get better! See further below.
Check [the video](https://youtu.be/N-NzqiUUXwg)the video to see a demo of this scenario in action:
## Future-Proof Your Application Modernization Efforts
Once we introduce Kong Mesh, we can get creative with our workloads, and it doesn't matter where they run: VMs, containers, bare-metal, on-prem or in the cloud. Imagine, after the scare of the outage has transpired, that you'd like to set up a brand new AAP cluster with a new version running in a containerized environment, such as OpenShift. Thanks to Kong Mesh, you can do that, and you can initially treat your new AAP environment as a canary deployment. Routing a minimal portion of the traffic, say 10%, to the new AAP cluster with a [Traffic Routing Policy](https://kuma.io/docs/1.3.1/policies/traffic-route/#l7-traffic-split)Traffic Routing Policy, can take place until you have verified everything is working. Once that is determined, you can shut down AAP clusters you no longer need, with your customers continuing to invoke the never-changing APIs in Kong Gateway they know and love. Pretty slick, if we might say so ourselves.
Take this same setup, and apply it to your application modernization efforts. Once you have workloads under the blanket of Kong Mesh ingesting requests via Kong Gateway, you can start chipping at your monoliths under the covers. Secure them, DR them, modernize them, move them around and replace them, with the peace of mind that your users are unaffected because ingress routes don't change.
## In Closing
In this post, we showed you how to gain zero-touch disaster recovery preparedness for Ansible Automation Platform clusters with the assistance of Kong Gateway and Kong Mesh. We also demonstrated the universal nature of Kong Mesh by using workloads on VMs in the service mesh.
If you feel adventurous, you could deploy a third AAP instance and create a canary using Kong Mesh constructs. Once you are confident your new deployment is sound, you could decommission any other AAP clusters. Or, you could add more AAP clusters to the mix and do geo-routing based on where the requests are coming from or load balance equally across your different environments.
There is a symbiotic relationship between Ansible Automation and the Kong components that we haven't yet explored. For example, Kong Mesh agent lifecycle management (specifically when running in a non-containerized environment) or provisioning and configuring Kong data and control planes. If your goal is to have configuration as code in addition to zero-touch DR, you can achieve it with Ansible Automation Platform and Kong.
**Don't let an outage catch you off guard! Reach out to **[**Kong**](https://konghq.com/contact-sales)**Kong**** or **[**Red Hat**](https://www.redhat.com/en/contact?contact=sales)**Red Hat**** if you would like to explore a joint Disaster Recovery solution tailored to your needs.**








