
Many companies are leveraging DevOps, microservices, automation, self-service, cloud and CI/CD pipelines. These megatrends are changing how companies are building and running software. One thing that often slips through the cracks is security. With microservices, there's an increase in the number of APIs companies have to protect.
Zero-trust is an excellent way of mitigating many security concerns for these new cloud native approaches to software design, implementation and operations. To me, zero-trust is the AAA of security:
- Authentication
- Authorization
- Accounting
Those three things, at the very least, should follow all your services. You shouldn't just implement them at the edge. AAA will enable you to have control over every API across your software stack.
This article will focus on authorization—the problem of controlling actions that people or machines have taken. End users, people, machines or services could take those actions. For example, "Can Alice withdraw money from the account?" or "Can this service request invoices from another service?"
How is this different from authentication? Authentication is the problem of how you convince a computer system that you are who you say you are. A standard solution is with usernames, thumbprints and passwords.
Modern Application Authorization Responsibilities
Let's start by comparing authorization requirements in microservices vs. monolith.
In the monolithic world, you'd have four major components when making an application:
- API gateway
- Frontend
- Backend
- Database
In the new microservices world, there are many more components. Even so, you could still lump those components into some of the same functional categories as in the monolithic world. Each of these different collections of components plays in the context of authorization.
- An API gateway is an effective place to enforce authorization for external, customer-facing or user-facing APIs.
- The frontend is not going to enforce the authorization policy. Still, it will be responsible for understanding those authorization policies. That way, when it renders the GUI, that frontend can make sure that it’s not showing a user something they’re not authorized to access or change. The frontend helps administrative users set up their end users' roles or permissions within the application.
- The backend handles enforcing public, external-facing APIs at a finer level of granularity. It's also responsible for authorization controls over the internal APIs within an application.
- A database is another force to think about enforcing authorization. Companies have been doing this forever by ensuring the correct users can read the correct columns from their databases. Companies are also using databases to store attributes that inform authorization decisions.
Architectural Choices (Pick One or More)
When putting authorization controls in place for the backend, there are several options to consider. Every time a backend service receives an API call, you'll want to put an authorization policy in place to have adequate controls over those APIs.
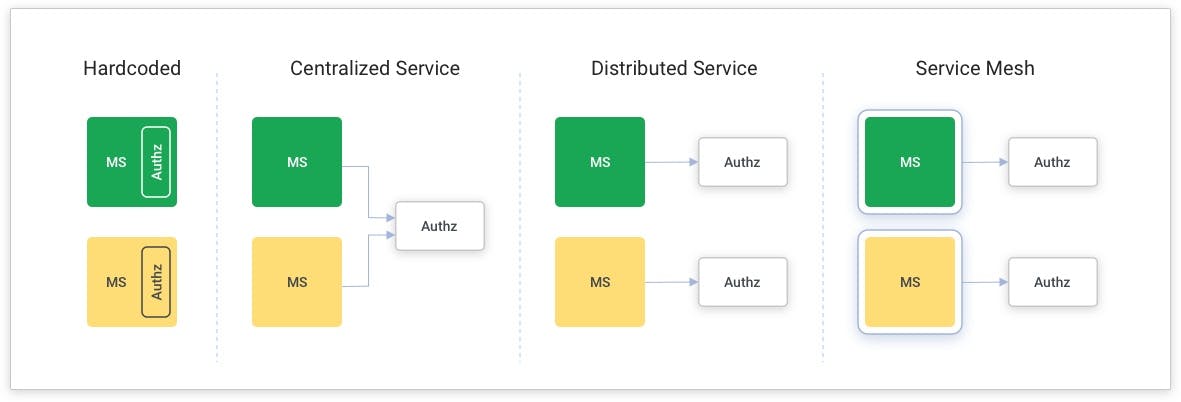
Hardcoded
One option is to hardcode those authorization policies into every microservice. It's a great idea from an availability and performance point of view, and it gives the app developer a great deal of control over the policy.
However, there are many drawbacks. To repeat the authorization policy across services, you'll have to repeat that work in every language you’re using. That could cause policies and enforcement to become inconsistent because it’s up to the developer to make sure they’re calling the authorization policy at the right time.
Security reviews are often slow because the security team has to review each service manually. There’s no way to hot patch or update that authorization policy without redeploying the microservice, so logging also becomes inconsistent.
Centralized Service
Another option for implementing authorization on the backend is to outsource that authorization logic to a dedicated microservice. When a microservice needs an authorization decision, it hits that dedicated authorization microservice.
There are several benefits here. You’re not repeating work and have one place to implement this. Authorization policies are super consistent, security reviews are much faster, hot patching is quick and easy, and you can just update that authorization service.
This option still has some drawbacks — the biggest ones being availability and performance. In a microservice architecture, an end-user request might hit many different microservices. Each one incurs a network hop cost, and that’s going to impact availability performance. If you add to every one of those backend services a second network hop to check for authorization, you'll double the number of network hops. That can have drastic effects on your availability performance globally.
Distributed Service
Another option is to turn that centralized service into a distributed service. In this setup, you'd have an authorization service running on the same server as each microservice.
Here you still have all the benefits in the previous centralized service category.
The downside here is you’ve got to take a dependency on this distributed authorization service.
Service Mesh
Let’s look at one final option here, and that is the service mesh.
The benefit of a service mesh is that you have a network proxy running on each microservice. That network proxy handles receiving and sending all the APIs to and from the service. Then you can integrate that microservice with that distributed authorization service. In doing so, you drop a lot of the drawbacks the previous options have:
- No repeated work
- Consistent policies
- Fast security reviews
- Hot patching
- Availability and performance
- Consistent enforcement
- No service modification
The downside is that you need to deploy the service mesh. But if you’re planning to do that anyway, then this is the right solution.
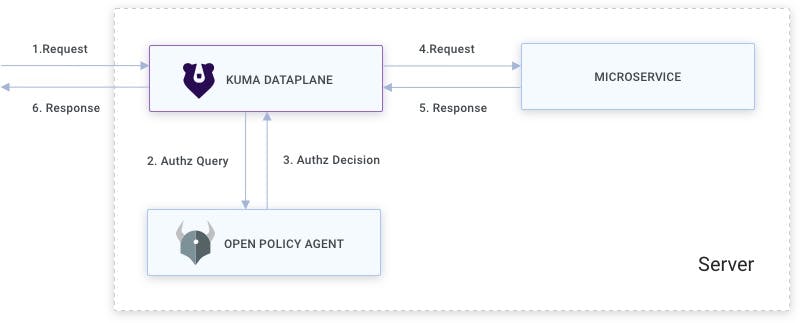
Kuma for Service Mesh. OPA for Authorization.
Kuma is a great way to think about putting a service mesh in place. What you can also do for this authorization system is use Open Policy Agent (OPA). The idea here is you've deployed the Kuma data plane and the OPA all on the same server. You can hook up Kuma to the OPA, and then whenever an external request comes in, Kuma will send the agent an authorization query that says, "Hey, is this API call authorized or not?" OPA returns that authorization decision and Kuma is responsible for enforcing that decision.
Policy Examples With OPA and Kuma
Once you put OPA and Kuma in place, what kind of policy can you write? Here are a couple of examples.
Service-Level Policies
Service-level policies control which service talks to which other services over which APIs. You would write a straightforward allow statement that says allow GET requests on the path /pets if you’re looking at the source and the destination for those service identities. And you have to decide on how you’re going to deal with service identities.
User-Level Policies
User-level policies control which end-user can perform which actions on which APIs. For these, you'd write an allow statement. Again, you’re going to do a check on the path. Instead of looking at the headers for source and destination, you should look at the token.
External Data Dependencies
External data dependencies are all about what’s going on in the world. Here you could use LDAP for employee information or use any kind of external data you like.
OPA Applied to Microservice Authorization
Authorization is not just a problem for the backend. It's a problem that you should solve at the API gateway and the front of the database. If you’re running Kong Gateway, you could connect that to OPA and enforce authorization at the API gateway level. One of the nice things about OPA is that you can go ahead and use OPA for really any use case. It's a general-purpose policy engine.
OPA Applied to Cloud Native Policy
OPA solves authorization across the cloud native stack, including the three pillars of cloud native:
- CI/CD pipelines
- Cloud platforms
- Applications
You can leverage OPA for each of these categories.
And using OPA to do admission control within Kubernetes is another popular use case and controlling what resources on the public cloud get deployed with Terraform. I've even seen people also use it for SSH control.
Styra DAS: A Control Plane for OPA and Cloud Native Policy
In a service mesh, you may have 500 microservice instances across data centers. In that case, you'd end up with OPA as a sidecar like you would with the Kuma data plane. That would make 500 copies of OPA. Each copy needs to have policies deployed, status updates and policies written. To manage this, you'll need to add a control plane for all those OPAs.
Styra Declarative Authorization Service (DAS) is one option to solve this issue. From day one, we designed it to be a control plane for OPA, and it can be used to manage OPA across many different use cases. Styra DAS has specialized support for Kubernetes and the service mesh and provides a vertically integrated policy-as-code solution designed for the enterprise. You can try out DAS Free at styra.com.