Starting with the 2.7 release, using Cassandra as a configuration datastore for the [Kong Gateway](https://konghq.com/kong)Kong Gateway will be considered deprecated.
Cassandra features will remain in Kong through 3.3, and its use will not be prohibited. However, some newly introduced functionality may not be optimized for performance or have full functionality when using Cassandra.
The removal of Cassandra support is scheduled for the Kong Gateway 3.4 release — giving users and customers time to plan their next steps with Kong's more powerful deployment models. Enterprise customers who wish to use Cassandra for the longer term should use the 2.8 Long Term Support version of Kong Enterprise, which has full support until 2025.
## Early History
Our journey with Cassandra started very early on in Kong Gateway's history. Cassandra was the only supported backend store for Kong configurations until version 0.8.0, which added support for Postgres. A year later, in 2016, the support for Postgres joined with Cassandra to form our initial public release — after some 1,500 commits to our public GitHub repository.
As a fun side note, the very first "issue" in Kong Gateway's GitHub repository is about tracking the adoption of Cassandra: [](https://github.com/Kong/kong/issues/1)[https://github.com/Kong/kong/issues/1](https://github.com/Kong/kong/issues/1)https://github.com/Kong/kong/issues/1
One of the early needs we had was to support Kong Clusters across distributed data centers. Cassandra has an important feature set that enables that. Almost to the point that we didn't need to worry about it.
For example, if we were asked, "Do you support rate-limiting counters across distributed data centers?" we could just reply, "Sure!" (proudly and with confidence). It was Cassandra that enabled these important use cases. When it comes to rate-limiting counters, Cassandra supported native TTLs too! For us, Cassandra seemed to be the obvious choice as a backend store for Kong. Since then, we have generally recommended Cassandra for distributed Kong clusters and Postgres for single data-center deployment.
You may be asking yourself, "Why deprecate the support for Cassandra then?" Read on.
## How Kong Gateway Deployment Models Evolved
On the 0.x.y series of Kong, the great open-source contributors and we continued to improve the codebase. Behind the scenes, we also prepared for the all-important 1.0 release (you can only do it once).
For the 1.0 release, we rewrote most of the data layer:
- - Introduced a new declarative schema language
- - Rewrote the data access layers and the database connectors
- - Implemented support for blue-green deployment
- - Rewrote the Kong Admin APIs
We started to utilize Kong schemas as a single source of truth to many things in Kong. Kong generates many things from the schemas, including DAOs, admin APIs, documentation, declarative configuration format, and OpenAPI specifications. There was one major addition worth mentioning in Kong Gateway 1.0: the addition of raw TCP/TLS stream proxying.
After releasing Kong Gateway 1.0, it became inevitable that running Kong proxies (data planes) with an active connection to the configuration database was not what everyone wanted. Container automation was getting much attention with [Kubernetes](https://konghq.com/blog/learning-center/what-is-kubernetes)Kubernetes, GitOps, and other tools, patterns, and methodologies. Some users wanted Kong to be integrated deeper into the systems and workflows, which needed a different approach than what we offered. Or at least where our supported deployment models were not optimal. We also started to hear more and more that we need to have a clean and proper separation of data planes and control planes.
### DB-Less and Declarative Config
This led to the implementation of DB-less and Declarative Config. The first version was released with the Kong Gateway 1.1. You no longer needed a database to deploy Kong; you just needed a file somewhere (YAML). We spend most of our time in the 1.x series to improve the existing feature set. We did introduce GRPC proxying and initial support for plugins written in other programming languages (besides Lua).
While DB-less was a good addition and deployment model for some, like the traditional deployment model is for some, it was still not a good fit for everyone or every use case. More importantly, it missed the integrated control plane. You could use Git-based flows, etc., other software to distribute shared configurations, and DevOps tools and techniques to manage DB-less data plane nodes. It is a valid and supported way to deploy Kong, but those processes need to be set up.
### Hybrid Mode
The [hybrid deployment mode](https://docs.konghq.com/gateway/2.6.x/plan-and-deploy/hybrid-mode/#main)hybrid deployment mode was introduced with Kong Gateway 2.0 to answer the need for a clean separation of control planes and data planes. And to provide the control plane to DB-less data plane nodes. People familiar with Kong might question the difference between DB-less nodes connecting to the control plane and traditional Kong nodes (that don't enable Admin API) connecting to databases. One big difference is that DB-less data plane nodes are autonomous while the traditional nodes require an active database connection. The traditional nodes may work without an active database connection because of caching, but we don't promise that they always do. When it comes to deployment, the traditional nodes also need to reach the configuration store, which is not always desired or even possible.
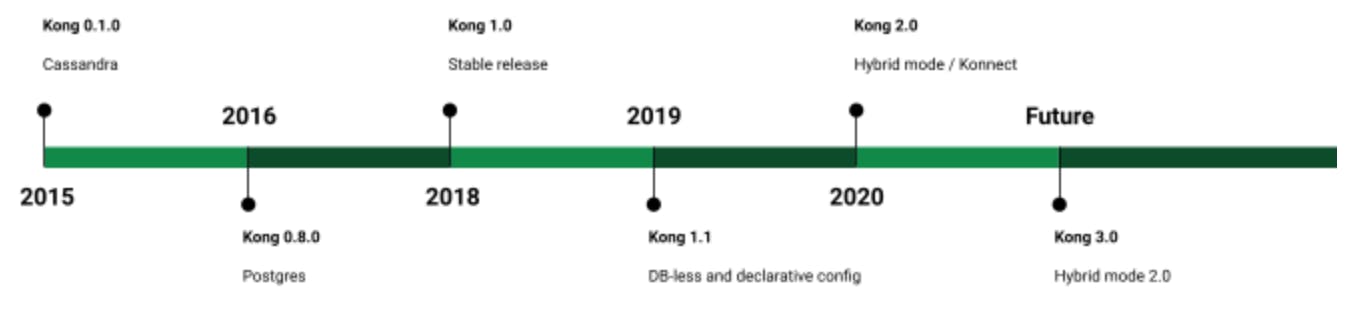
### Kong Konnect
To give users the best experience managing Kong Gateway, we have also introduced [Konnect](https://konghq.com/kong-konnect)Konnect. This SaaS service can effectively be the control plane for your data plane nodes—if you prefer not to run the control plane on your own, as many don't. We truly believe that this gives the best of both worlds and allows us to continuously deliver new value to Kong customers with enhancements to the SaaS control plane and the on-premises data plane. We also envision delivering new features directly from the control plane to the data plane.
### What's Next?
As you may have noticed, we are obsessed with the deployment models. We want users to run our gateways the way it fits best to them and make it as easy as possible. As the world around us finds new patterns and better ways to do things, we adopt. We are already planning enhancements to adapt to arising use cases and limitations of our current deployment models. We have gained a lot of knowledge, not only the technical aspects, during the years, and we hope we lead our industry to better practices. In that sense, we are on a journey - together.
Where are we going next with the deployment models? Currently, one of the big limitations we have with the control plane and data plane separation is that we do not support incremental synchronization of changes or partial synchronization. We don't have bi-directional communication between control planes and data planes, either. That leads to limitations such as those distributed rate limiting counters the Cassandra solved. That is a good segue back to Cassandra.
## Why Deprecate Cassandra?
At this point, you should have some picture, perhaps a bit blurry, of where this all is going.
For us, it doesn't matter where our gateway's configuration data is stored or what technology is used to store it. We have been proud to support such amazing open-source projects as Cassandra and Postgres. And they have been reliable and fantastic to work with. But as with everything, it comes with a price.
During the years, the customers and open source community members have asked us to support other databases such as Redis, MySQL / MariaDB / Percona, Hazelcast and many others. There have been even implementations by the community to add some of those. While adding support to other databases could solve some of the problems or help Kong Gateway integrate with environments where such databases are already deployed and well-understood and approved, it is not exactly something on our focus. We want the Kong Gateway to be, first and foremost, the best possible solution as an ingress gateway (north-south). Similarly, we want the [Kuma](https://kuma.io/)Kuma and [Kong Mesh](https://konghq.com/kong-mesh)Kong Mesh to be the best solution to deploy [service mesh](https://konghq.com/blog/learning-center/what-is-a-service-mesh)service mesh (east-west). Adding support for additional databases means mostly unnecessary work and maintenance, and sometimes confusion:
- - migrations
- - database types (key-value, relational, wide-column, document, graph)
- - documentation
- - best practices
- - sales
To ease the maintenance burden and simplify the Kong Gateway as a whole, we decided to start phasing out Cassandra support on Kong Gateway. As with everything in Kong, we don't take it lightly when we choose to break the backward compatibility. First, this gives our users and customers time to plan and migrate to a new database or deployment model. Secondly, it gives us time to improve our existing Postgres, Hybrid, and DB-less deployment models and deliver the features that will cover the current Cassandra use cases.
Cassandra, in general, is a very good solution for a SaaS service where access patterns design the schemas, but a less good option for an extensible platform like Kong, where the access patterns can vary a lot.
Kong is available to you to make the transition for existing Cassandra users as smooth as possible. Please feel free to [connect with us](https://discuss.konghq.com/)connect with us if you have any questions or concerns about deprecation.
*Editor's note: Since the publication of this post, Kong has introduced *[*Kong-EE 2.8 LTS*](https://konghq.com/blog/product-releases/kong-enterprise-2-8-lts-support)*Kong-EE 2.8 LTS** (long-term support), which is fully supported until 2025. The original version of this post said support would continue through the entirety of the 3.x series, which we intended to conclude in 2023. With the LTS support Kong now offers, we will support Cassandra until 2025. Learn more about *[*Kong Enterprise 2.8 Long-Term Support*](https://konghq.com/blog/product-releases/kong-enterprise-2-8-lts-support)*Kong Enterprise 2.8 Long-Term Support**.*







