*This article was written by Charles Boicey, Chief Innovation Officer at Clearsense.*
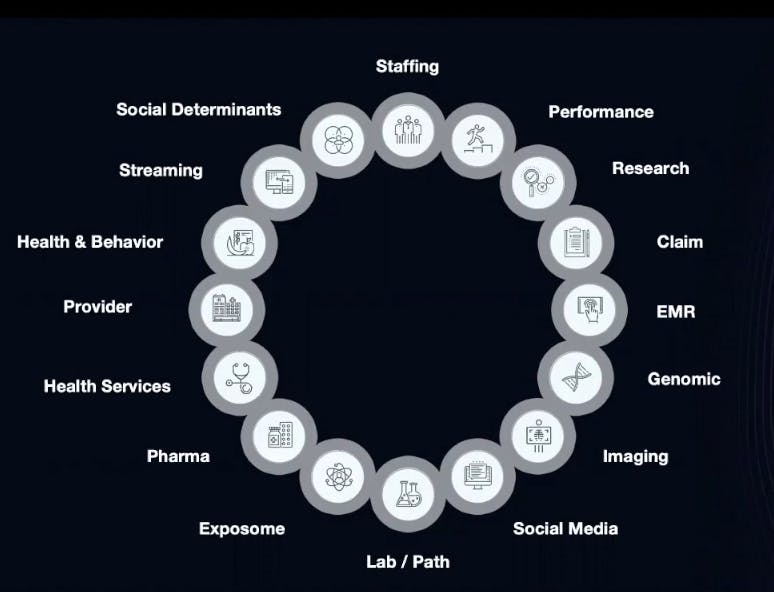
If healthcare data is genuinely going to impact a person’s well-being, we have to consider all patient data. Patients don’t spend much time with clinicians allowing them to collect data. Even most hospitalized patients only stay for a week or so. That’s why healthcare companies need to pull in external data as well. The data collected directly from patients is just a small sampling.
Here are some of the external data that could be valuable to collect.
### ***To do this, healthcare companies will need to move to a modern, service-oriented architecture. The applications should be containerized, API-centric and able to pull data from multiple sources.***
**In this post, or if you prefer to watch the video below, I'll explain how we achieved this using **[**Kong Gateway**](https://konghq.com/kong)**Kong Gateway****, **[**Kuma**](https://kuma.io)**Kuma**** service mesh and other modern tools.**
### ***Private Cloud***
Remaining compliant with healthcare industry regulations, such as HIPAA, requires total control of the environment. In reality, we don’t have to choose between private cloud, public cloud and on-prem. The decision was already made for us—all of the above.
That’s why I start in a private cloud. It gives me an API layer to connect to any other system I need to. And really, that is a hybrid approach. If I need to run something in Google BigQuery, I better accomplish that for my environment. We don’t want to box ourselves into an architecture that only works in a single environment.
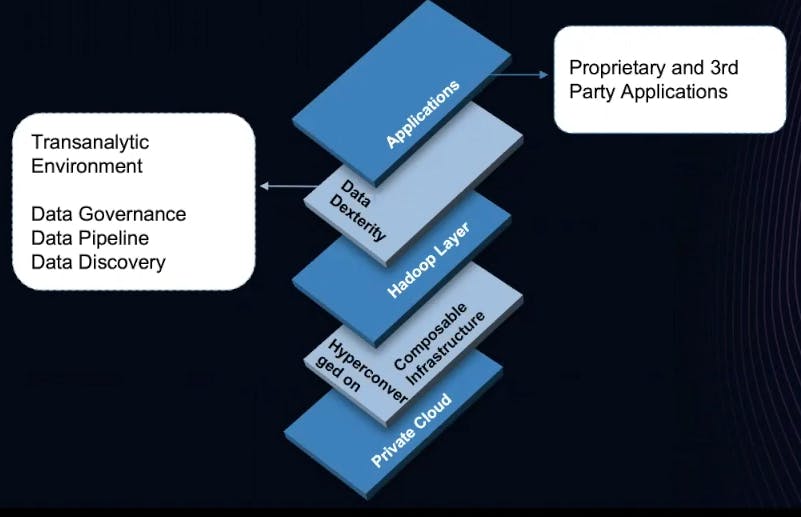
### ***Infrastructure***
I’m a proponent of both [hyper-converged](https://en.wikipedia.org/wiki/Hyper-converged_infrastructure)hyper-converged as well as [composable](https://en.wikipedia.org/wiki/Composability)composable. I’ve combined both of them. From a composable infrastructure, I can scale up on computing memory or scale out on storage using low-cost, commodity hardware, and then put a hyper-converged layer on top. That now gives me the ability to work in an environment that is bare metal, virtual, containerized and serverless.
### ***Hadoop Layer***
Next, we go up a layer with a [Hadoop infrastructure](https://en.wikipedia.org/wiki/Apache_Hadoop)Hadoop infrastructure. It may seem crazy, but think about what I mentioned in the introduction about all those data types—they need to land somewhere. Hadoop infrastructure is the proper place to start the process.
### ***Data Dexterity***
A fair clustered environment distribution is an excellent place to handle various healthcare data types from a processing perspective.
### ***Applications***
We go up to the next layer with an environment that can handle proprietary applications and third-party applications. This environment allows for [service mesh architecture](https://konghq.com/webinars/service-mesh-architecture)service mesh architecture, microservices and is API-centric. Some components include [Kubernetes](https://kubernetes.io)Kubernetes and [Kuma](https://kuma.io)Kuma. A modern application architecture like this can communicate with data within this environment and communicate via APIs to external environments.
Now that we’ve gone over the basics, let’s get into a little more detail.
Before I dive into the technical details, here’s a high-level overview of the situation.
## **Modern Data Architecture for Healthcare**
Clearsense has established the below architecture for our platform. We bring everything together through a RESTful API managed by [Kong Gateway](https://konghq.com/kong)Kong Gateway.
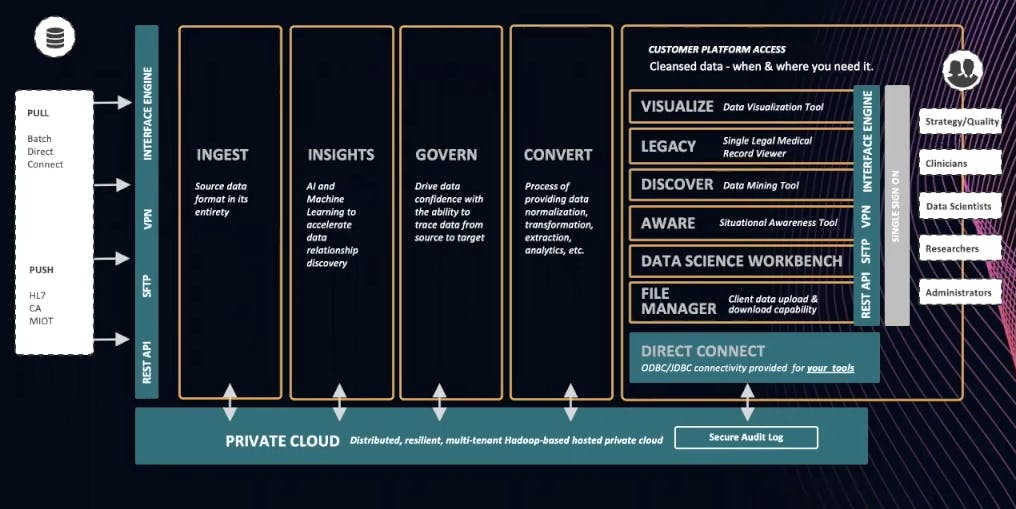
Data typically comes into a healthcare environment from a push or a pull. *Pull* is when we’re grabbing data by batch or direct connect. This is where interface engines or [restful APIs](https://konghq.com/blog/learning-center/what-is-restful-api)restful APIs come in. *Push* sends data to us. Again, an interface engine will accomplish this. [HL7](https://www.hl7.org/implement/standards)HL7 is a familiar standard within healthcare for streaming messages as well as from a fire API.
### ***Ingest***
As you move from left to right in the above chart, you’re bringing everything in its entire native state. You’ll want to do this because healthcare, from a data perspective, is rapidly maturing. You don’t want to leave data behind. As you build clinical models, operational models or research models, there will be a need for that data. We can do a lot more with 25 years’ worth of data than with one or two years’ worth.
### ***Insights***
Once data comes in, we can then produce insights on it. We may or may not have schemas. We may or may not know all the relationships. Either way, we throw AI against it so we can understand the insights a little bit more.
### ***Govern***
We govern all of the data produced by cataloging, an understanding based on the data product (data science model or digitalization). It's important to understand where the data came from and the calculations behind the results.
### ***Convert***
It’s one thing to land data, but it’s another thing to process it so that it’s at an endpoint as part of the API layer - in our case, Kong. I’m interested in bringing the data in and then applying a schema to it when I understand what that endpoint is. I prefer to do this over coming up with a bunch of dashboards with data science apps and then going back to sources to hunt for that data with an ETL process. That’s super laborious. It’s far more effective to bring everything in and apply a schema to it. That schema can later change as the requirements change.
## **Robotic Process Automation in a Healthcare Data Pipeline**
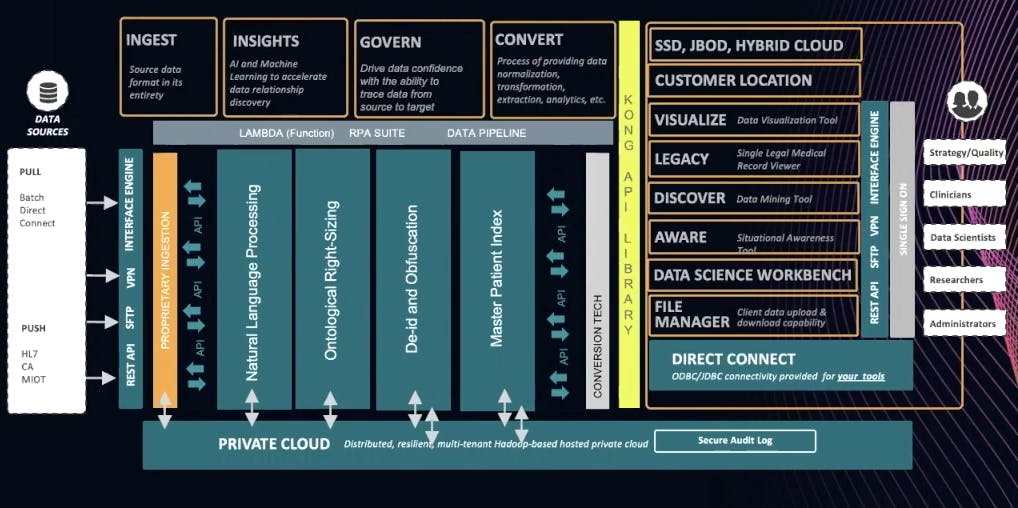
I’ve spent a long time researching and building out robotic process automation components in my environment. Healthcare data in its raw state contains both discrete as well as textual data. From the API perspective and a process perspective, we must not have a natural language processing capability within that data pipeline. We can send documents in that pipeline to extract information and then further enrich it to the pipeline. This would make a call out to MLP services and then bring that back.
For example, if I have laboratories coming through that aren’t coded with a point value or that point code is incorrect, I need to correct that as the data passes through. I don’t want to pass the data through and then correct it manually and/or using the service.
Many times in research, HIPAA requires that data is de-identified and/or obfuscated, depending on what the use case is within that data pipeline. At the same time, it’s crucial that we understand who those patients are and that we’ve given them a proper identifier. We can take advantage of that API library. Those other resources external to the data pipeline may be within the environment, or they may be a service that we call on. Much of this is so that developers can access data externally that’s not generally within the confines of a health care ecosystem.
## **Case Study #1: Meharry Medical College**
Three years ago, [Meharry Medical College](https://home.mmc.edu)Meharry Medical College decided to establish a data science institute and be entirely data-driven in their care and education. They’re now graduating medical students with MDs and a data science certificate. They’re also working on master’s level and PhDs as faculty grows within the environment.
The college is in an underserved community that’s primarily African-American. That’s the population that they served as COVID-19 first started. The hypothesis that we generated was: Is there a disparity in identification, treatment, outcomes and mortality in this community, and can this be extrapolated across other similar communities?
### The Disproportionate Impact of COVID-19 on Communities of Color
We used the [Clearsense](https://clearsense.com)Clearsense environment and APIs external to the various COVID-19 data sources from a population perspective and actual clinical testing. From an API perspective, we brought in publicly available data and clinical data.
With this data, we showed a disparity in diagnoses, treatment and outcomes within the African-American population in underserved environments. We also discovered that regardless of race and ethnicity, rural environments had a significant bit of disparity. Their mortality rates were high, and treatment was delayed.
We wrapped all this data up. We were able to present it to Dr. Hildreth, president of Meharry Medical College. He was able to bring that to Congress on May 29 and make the plea that HUBCs, or historically black colleges and universities, should do this type of research. He would not have been able to present without the ability to capture all of that data.
## **Case Study #2: UCI Future Health**
At [UCI Future Health](https://futurehealth.ics.uci.edu)UCI Future Health, we’ve determined that health is not just the absence of disease. Numerous environmental factors determine health. So what can we do as technologists to enable citizens in a low-cost way to manage their health? In the future, patients will see practitioners for some disease, an accident, or if we have a concerning genetic disposition. But again, the goal is to manage as much as we can ourselves.
### Adopting a New Perspective: Health State
Think health state, not disease state. An individual’s health state is always changing. What’s necessary to understand someone’s state? We need all kinds of data. We need to be able to understand a person, not just from a population perspective. For instance, I’m not only Charles with a hypertensive condition. I’m Charles, part of a population that does. But I am still unique, and I still need to be treated uniquely. We don’t treat all hypertensives the same. We have to treat them as individuals, although they’re also a group.
### From Data Streams to Events of Daily Living
Also, think about the activities that you do at any time during the day. It can be eating, or it can be the effect of the environment around you. We talked about all the different characteristics and whatnot. By collecting that data in the context of your experience, we can help you along the way. For example:
- - How much time do you spend commuting?
- - What was your heart rate during the commute?
- - What was your blood pressure during the commute?
### Personal Health Navigator
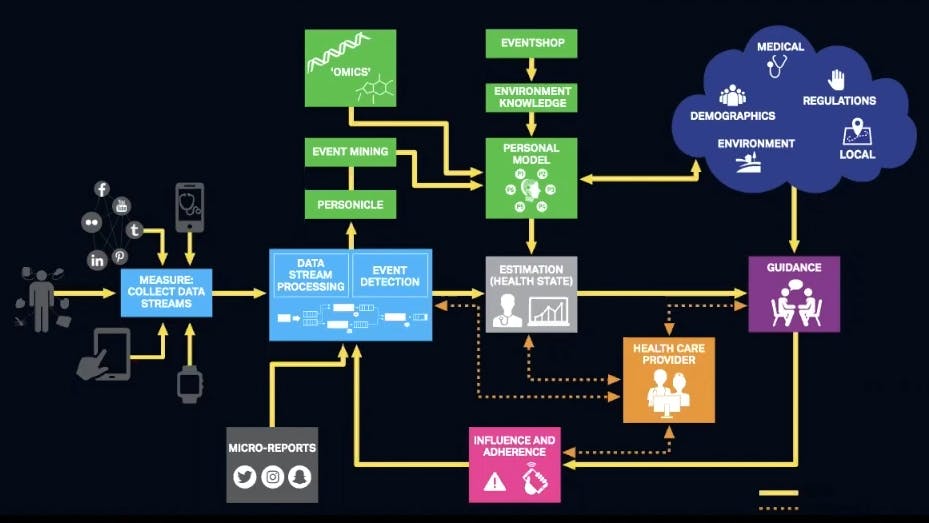
We’re collecting a bunch of data and streaming or processing it. We’re calling your 24-hour chronicle your 24-hour experience *personicle*. So that’s you. Combine it with your genomics and all that external data that I mentioned earlier, and you’ll have a personal model. We can then estimate your current state at any particular time, guide you to change your behavior and maybe notify a provider.
It goes something like this: I’m a diabetic. I eat five doughnuts at a Krispy Kreme on the West Coast and Dunkin Donuts on the East Coast, and now my blood sugar is up. My phone prompts me to do some exercise and gives guidance on what to eat for lunch. We take a glucose reading, and we go from there. We’re continually providing feedback.
### Application
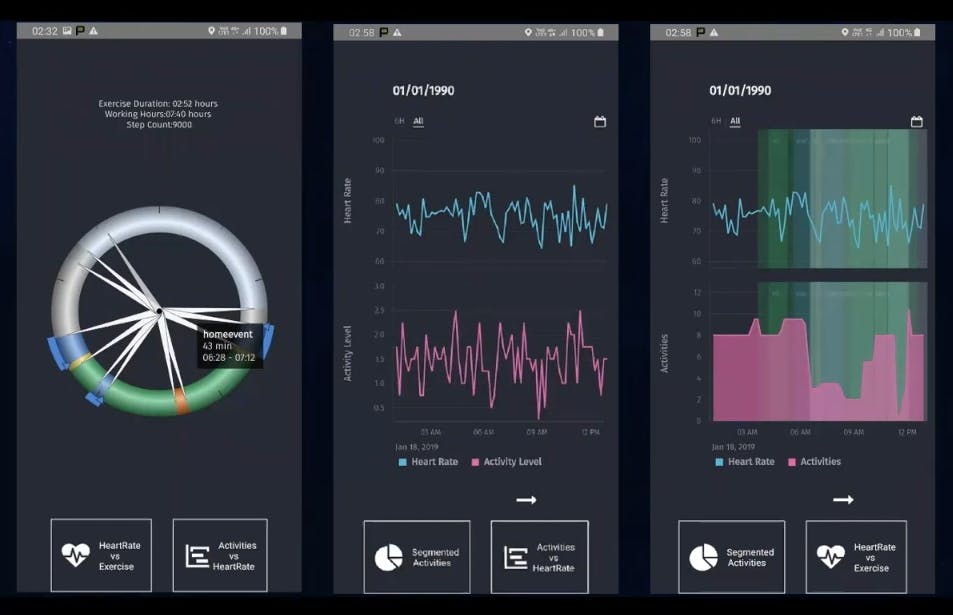
From an application perspective, you see all these spokes, or events, in the chart above. We can look at an activity level versus a heart rate. We can present you with a mini-exam. This is the *personicle* side of what we’re doing. The goal is to use the technology provided for us, especially taking advantage of all those data sources accessible through free and public APIs, and then bringing that back together in an environment from which we can do something.
### ***By containerizing microservices in that environment, we now have stable products that can be changed and upgraded without bringing everything down.***
You can imagine citizens relying on an application such as this. They’re not going to be tolerating any downtime.
### Interactive Event Mining: Correlation and Causality
With all this data in the system, we can now do what we as data scientists and analysts do best.
- - Take a look at the data and understand what the data is telling us.
- - Understand the various patterns.
- - Produce new data science products and interventions based on all the data collected in a de-identified form.
The goal is to leverage technology and data to identify personalized patient interventions.