At its core, [Kong’s AI Gateway](https://konghq.com/products/kong-ai-gateway)Kong’s AI Gateway provides a universal API to enable platform teams to centrally secure and govern traffic to LLMs, AI agents, and MCP servers. Additionally, as AI adoption in your organization begins to skyrocket, so do AI usage costs. With Kong, teams are able to keep their AI costs in check with several techniques, including applying token rate limiting per consumer, caching responses to redundant prompts, and automatically routing requests to the best model for the prompt.
In the latest 3.11 release, Kong continues to help customers deliver production-ready GenAI projects with comprehensive support for multi-modal and agentic use cases.
From playground to production: The real test for AI gateways
Experimenting with AI is easy, but when it comes to safely and efficiently rolling out AI projects into production, this is a far greater challenge. Many new AI gateways can handle basic GenAI use cases, but most have never been tested under the demanding, high-throughput conditions enterprises require. Additionally, once your organization begins working with natural language processing (NLP), embeddings, and unstructured data like images, performance isn’t optional — it’s critical.
Kong stands apart by extending its battle-tested API infrastructure to power modern AI workloads.
Kong AI Gateway is built on the same highly performant runtime — Kong Gateway — that already supports mission-critical APIs across the world’s largest organizations.
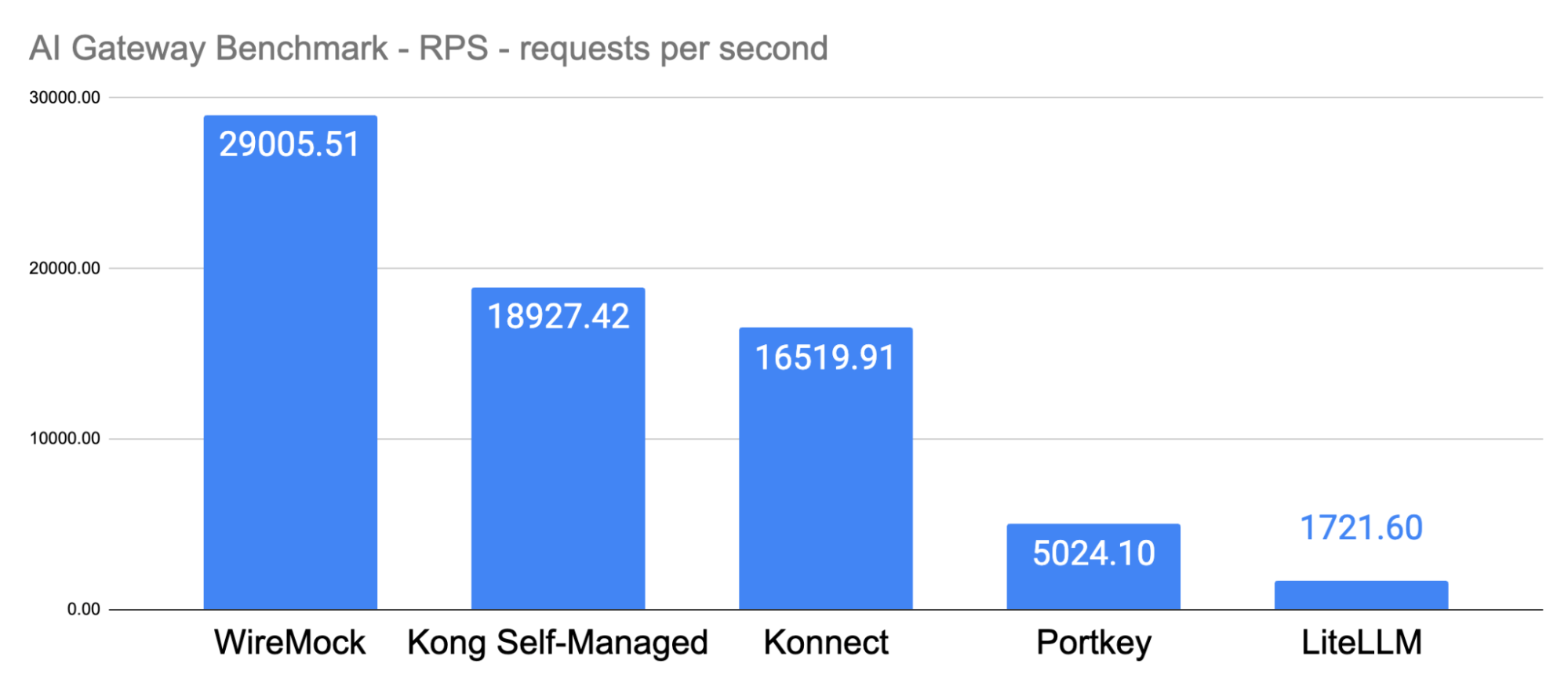
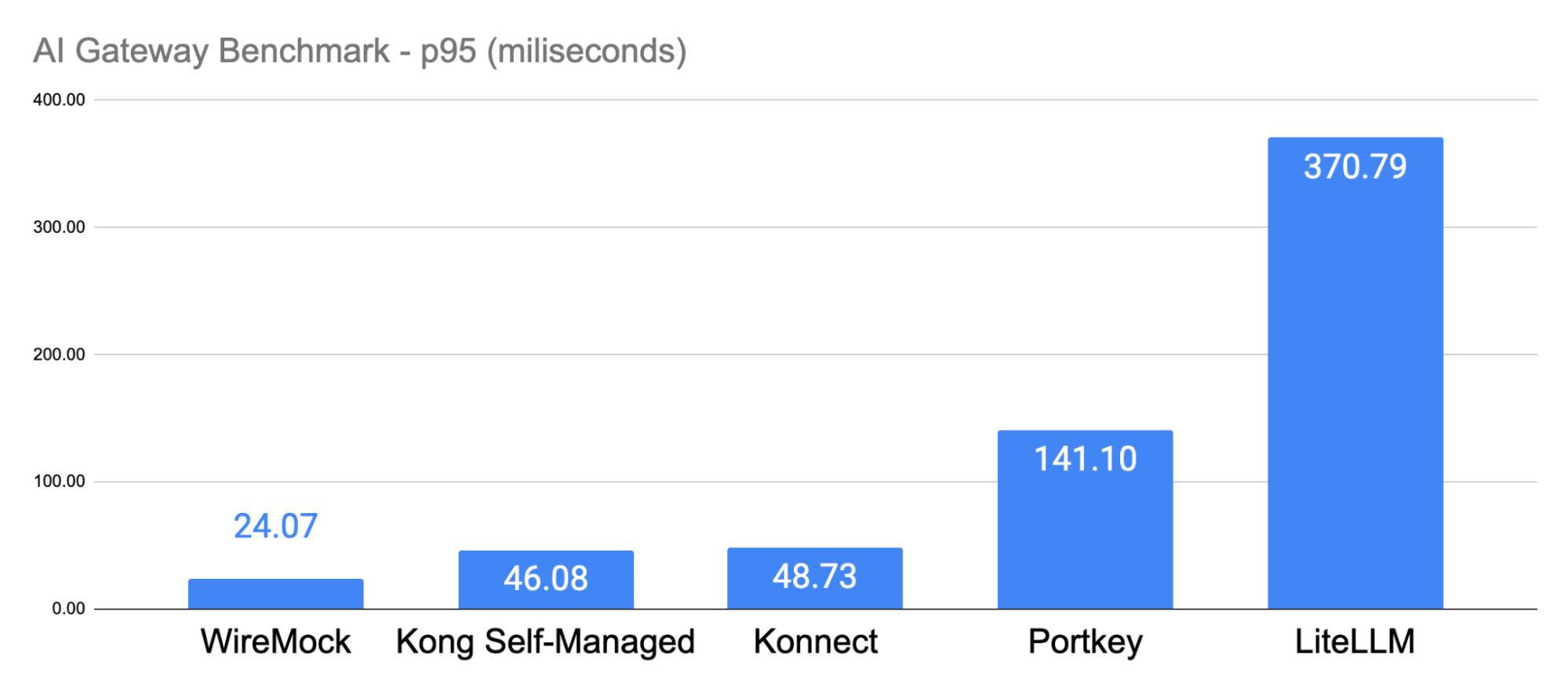
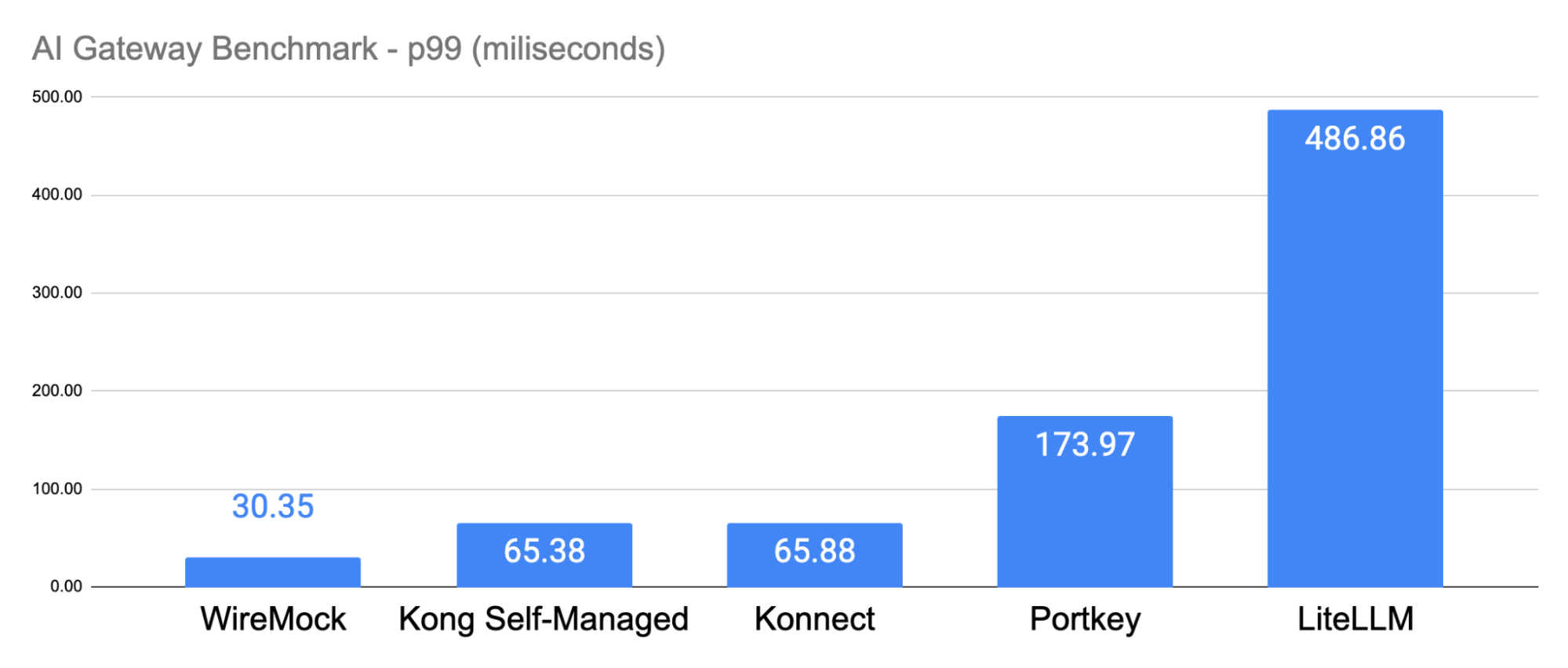
In this blog post, we'll share performance benchmark results comparing Kong AI Gateway to newer offerings like Portkey and LiteLLM. We’ll walk through the test setup, execution, and what the data reveals about each offering’s performance at scale.
Benchmark architecture
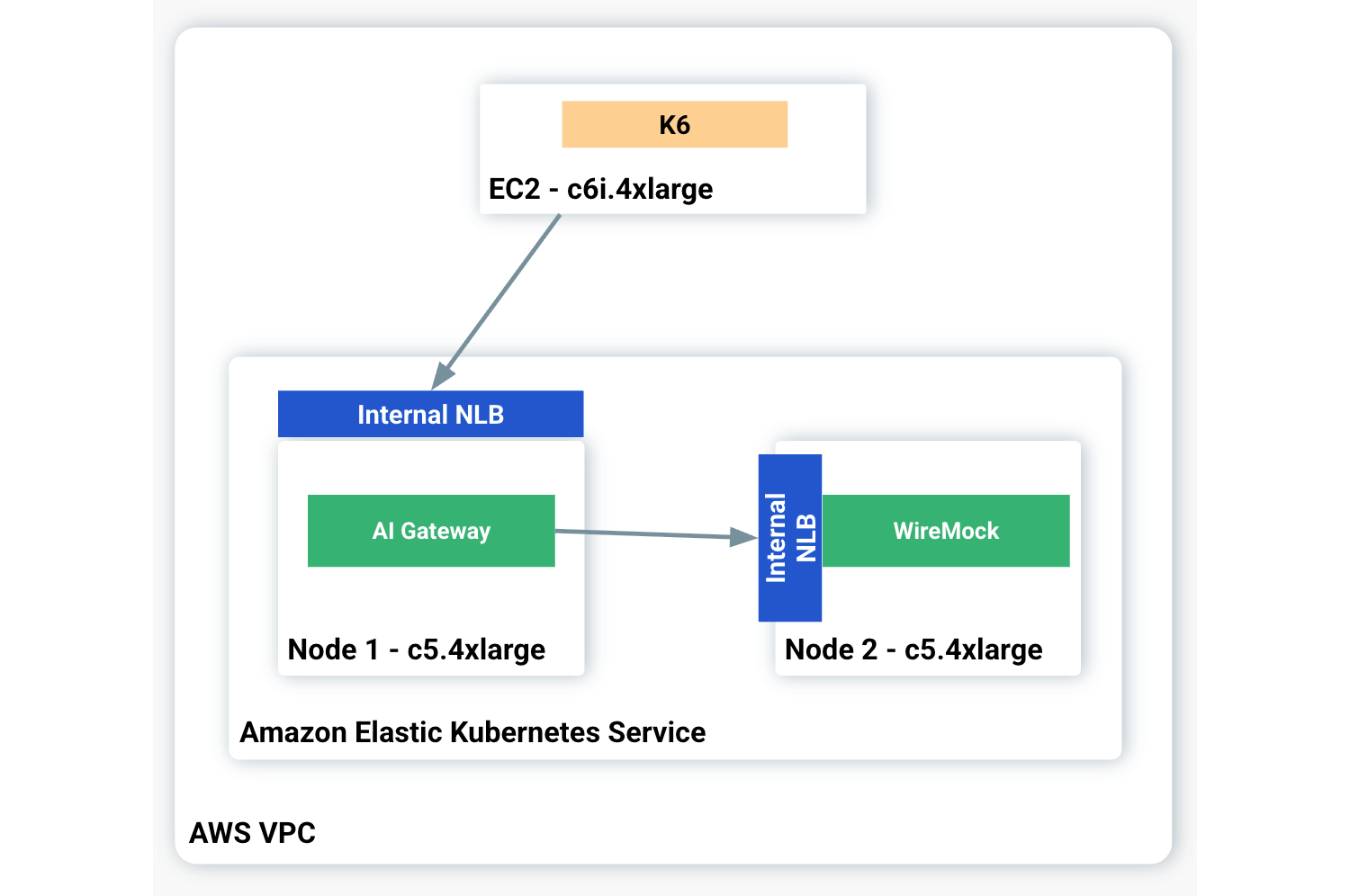
The benchmark tests were executed in AWS. The server infrastructure ran on an Amazon Elastic Kubernetes Service (EKS) cluster, 1.32. In order to have better control over the AI Gateways and remove the native LLM infrastructure variables, such as latency time and throughput, we mocked an LLM with WireMock to expose OpenAI-based endpoints. WireMock is an open-source tool used to simulate API responses.
The AI Gateways were exposed to the consumers through a Network Load Balancer (NLB) to protect them from external interference. Similarly, the mocking LLM was exposed with an NLB. In order to not compete for the same hardware (HW) resources, the AI Gateways and WireMock ran in their own EKS Nodes based on the c5.4xlarge instance type with 16 vCPUs and 32GiB of memory.
Lastly, K6 played the load generator role, running on an EC2 instance deployed in the same VPC as the EKS Cluster.
Here's a diagram illustrating the benchmark architecture: