### *The API spec is a contract. It is a promise that an API will function in a certain way. *
API builders implement the spec, while API consumers reference the spec to know what behavior to expect. Yet, somewhere along the evolutionary process of an API, the API specification needs to be reviewed:
- Does the API spec comply with a standard format?
- Does the API implementation behave in accordance with the spec?
- Has the expected behavior been verified through testing?
### *When either the API spec or implementation changes, you must perform all of these review steps again. *
In this article, we'll walk through the steps involved in reviewing an API specification. We start with a running example of an API service with a few endpoints. In our hands, we have a purported API spec document corresponding to that service. As is often the case, a development team that consumes our API service has complained that the spec is outdated and incorrect. We'll consider the steps we would take to review this spec manually. Then, we'll look at what the spec review process would look like when using [Insomnia](https://insomnia.rest)Insomnia.
Are you ready? Let's dive in.
## Our API Service: Names and IDs
First, let's briefly describe our simple API service. Our API service manages a database of users. Each User has an id and a name. Our service exposes four endpoints:
- GET /users returns the entire list of users.
- GET /users/:id returns the user with the given id.
- DELETE /users/:id deletes the user with the given id.
It's Friday afternoon, and you get an email from the marketing features project team with the subject line, "Users API – PLEASE HELP." It reads like this:
*We're building a new feature that uses your team's Users API. We looked at the API documentation page (which, by the way, was last updated over a year ago) for the available endpoints, but the responses we're getting don't look consistent. Are we doing something wrong? I'm attaching the spec document we're working from…*
You reluctantly open the attached file, aptly named users_api_spec_201911-v0-9 copy (1).yaml, and scan it briefly. Below are some of the salient parts:
You spot some problems immediately. For example, the shape of the response to GET /users references a schema (ArrayOfUsers) that isn't defined in the schema components. Some schema instances are of type obj, which isn't a valid data type in OAS 3. It looks like it's time to do a thorough API spec review. Let's get to work.
### Validate and Lint
At the very least, you *know* that obj is not a valid type in an OpenAPI specification, but object is. And the GET /users response references an ArrayOfUsers schema, but the schema defined lower down is called Users, not ArrayOfUsers. Who wrote this spec? You quietly hope that they've taken a job with your competitor.
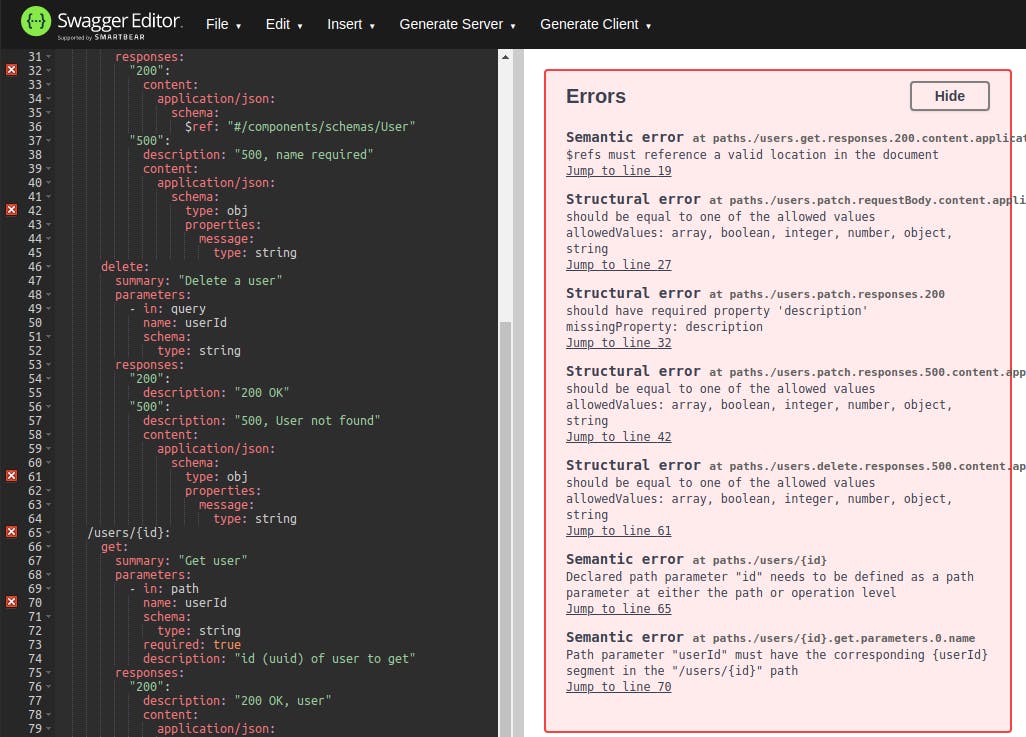
Those are just some of the glaring syntax issues that jumped out right away—and there has to be more. We need a way to validate the entire spec, ensuring that it conforms with the OpenAPI standard. One way to do this linting is by using the [Swagger Editor](https://editor.swagger.io)Swagger Editor. We can pull up that website and then copy-paste our spec. The linter in the Swagger Editor will tell us where our mistakes live.
It looks like there are several problems with our syntax beyond the ones we spotted. We could work within the Swagger Editor to clean up the syntax.
### Test API Implementation Against API Specification
After cleaning up the file to have a syntactically valid spec, the next step is to run a test case in the production API service. Does it behave the way the API spec says it ought to?
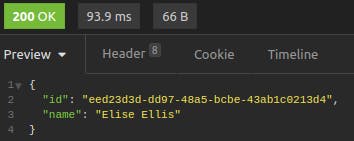
Let's start with a cURL request to get an existing user. Our original GET /users response had a user with an id or eed23d3d-dd97-48a5-bcbe-43ab1c0213d4. We send a request to get that user:
$ curl -X GET https://users-api-uxngcvgmwq-uc.a.run.app/users/eed23d3d-dd97-48a5-bcbe-43ab1c0213d4{"id":"eed23d3d-dd97-48a5-bcbe-43ab1c0213d4","name":"Elise Ellis"}
That looks like what we would expect. How about if we try to get a non-existent user?
$ curl -i -X GET https://users-api-uxngcvgmwq-uc.a.run.app/users/abcdeHTTP/2404x-powered-by: Express
content-type: text/html; charset=utf-8…
User not found.
The API spec said that we should expect a status code of 500, not 404, and that the response would be a JSON object with a message rather than a response of simple text. It looks like the API implementation has evolved, but the API spec has gotten stale.
Let's test out one more request. This time, we'll try to delete a user. The API spec says we should send a DELETE request to /users and include the user's id as a query parameter:
Well, *that* was unexpected. Our API spec could use some serious work.
### Manual Validation is Unsustainable
While it's wonderful that our manual review steps have surfaced where there are problems in our API spec, this manual validation process is unsustainable. Even if your API spec was versioned, the manual process of copy-pasting the latest proposed version into Swagger Editor for linting is tedious and time-consuming.
Our cURL requests for testing the API service were nice because we could run them at the command line. However, will you have the time to craft, execute and examine an entire set of cURL requests every time you want to test the API service for regressions? This manual process is error-prone and would benefit from automation.
There is a better way.
## API Specification Validation with Insomnia
[Insomnia](https://insomnia.rest)Insomnia is more than just an API client; it facilitates better API design with Git synchronization, OpenAPI format validation, and automated testing. By integrating Insomnia into your APIOps (DevOps+GitOps) workflow, you'll end up with validated, tested and up-to-date API specs that reside right beside your API implementation.
Let's walk through how to get there.
### Create a Design Document
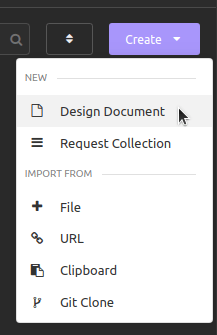
After installing and starting up Insomnia, you'll arrive at the Dashboard. Click on **Create** and select **Design Document**.
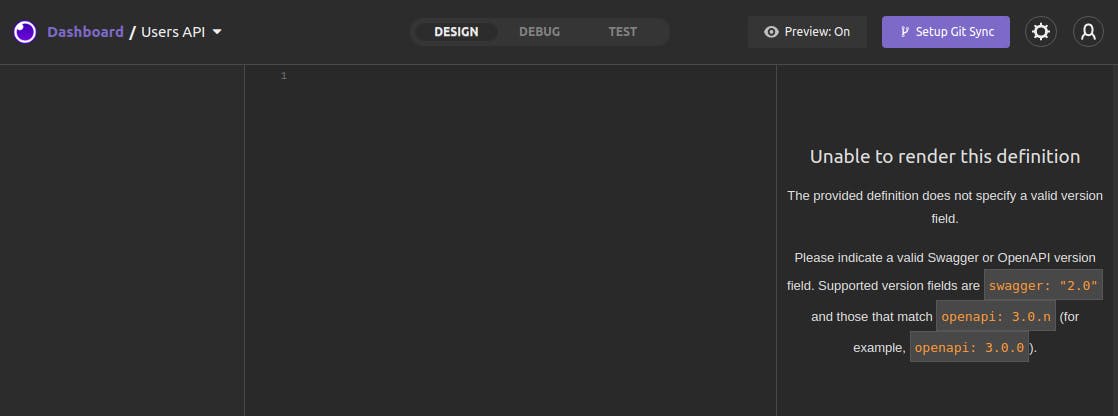
After entering a name for your Design Document (for example, "Users API") and clicking on **Create**, you'll end up at an OpenAPI specification editor with an empty document.
### Set Up Git Sync
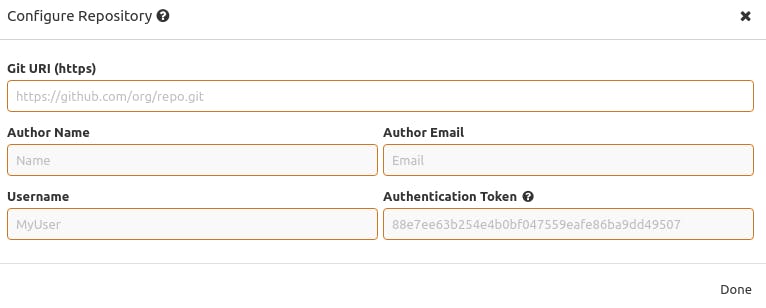
Insomnia can sync your design document with a Git repository (GitHub, GitLab and Bitbucket). As you make changes to your API spec, you can commit and push those changes to your remote repository—all from within Insomnia! When you sync to a repository, Insomnia will keep all of its work within a .insomnia subfolder.
After you have connected your Insomnia Design Document to your Git repository, you'll be able to navigate between branches, see commit history and commit and push your changes.
### Real-Time Linting and Syntax Validation
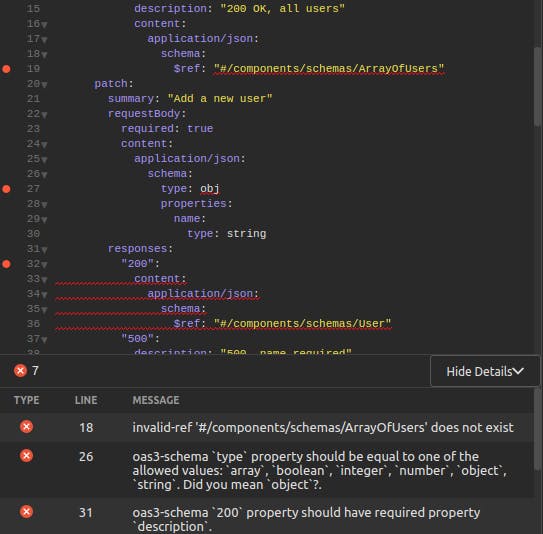
Now that we set up our repository, we paste in our syntax-violating, out-of-date API specification. As soon as we do that, we see Insomnia's real-time linter go into action. We're immediately notified of our API spec's syntax violations:
Yes, this is similar to what we would see in Swagger Editor. But remember, we will do *all* of our design and testing here in Insomnia, and we'll also push our changes to Git. Syntax validation can happen here, within our main working environment, rather than copy-pasted to a third-party site.
With our linter pointing out our violations, we click on each violation to navigate directly to the offending line. One by one, we go through the API spec and clean it up so that it is at least API standards-compliant. From here, we can commit our changes to the repository.
We enter a commit message:
Then, we push our commit to the remote repository:
Now, our latest API specification document is available for others who pull down the repository's latest commits.
### "Debug" With Example Requests
Although our API spec no longer violates OpenAPI syntax, we still have some consistency issues between the spec and the actual implementation. You'll recall that the spec says to expect a 500 status code on a non-existent user, but the API service (rightly) returns a 404.
In Insomnia, we enter "Debug" mode to create a set of stored API requests. These requests will also comprise the available requests we can use in our automated test suite.
When we enter Debug mode, we notice that Insomnia has already generated a set of requests inferred from our API spec document!
This is a great start.
We do notice several things about our actual API implementation which our spec has gotten wrong. First, the request method for adding a new user should be PUT, not PATCH. Also, the request for deleting a user should have the user's id as a path parameter rather than a query parameter.
We go back to "Design" mode to make those changes to our spec. And while we're at it, any "user not found" responses should have a status code of 404 in our spec, not 500. After making those changes, we go back to "Debug" mode. Now, we see two new requests added to the top of the list:
Our DELETE /users/:id request (now using a path parameter rather than a query parameter to /users) is shown, followed by our PUT request for adding a new user. We can delete our old PATCH and DELETE requests.
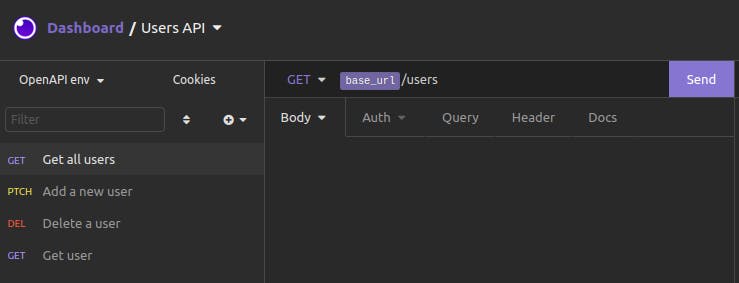
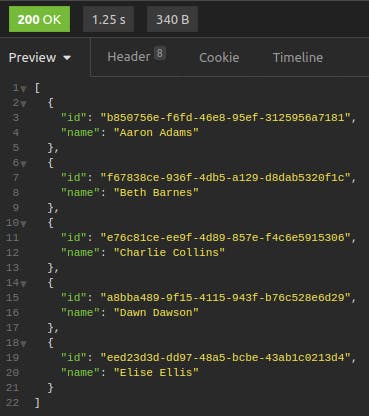
We select and send the "Get all users" requests. The response is as follows:
For the "Get User" request, we need to add a user id as a path parameter.
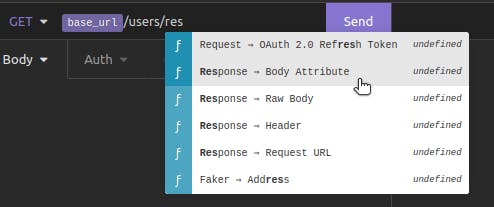
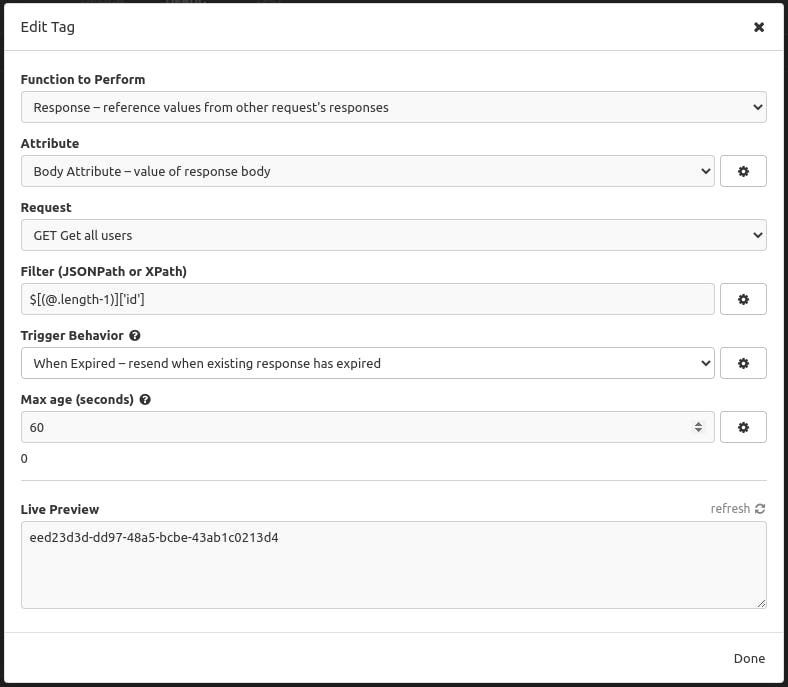
We'll tell Insomnia that the value to use for id should be based on the response body from our recent request to "Get all users." In *that* response body, we want to get the id from the last object in the array (the last user).
Whenever we test our "Get user" request, the response to the "Get all users" request will automatically supply the id. When we send the "Get user" request, the response looks like this:
We also create several more example requests so that we have all of the following:
- GET all users
- GET user (based on the id of the last user in the "Get all users" request)
- GET non-existing user (with an id that is not in the list)
- PUT (create) user, providing a valid name
- PUT (create) user, without providing a name
- DELETE user (based on the id of the last user in the "Get all users" request)
- DELETE non-existing user (with an id that is not in the list)
Now that we've created all of our requests, we can sync them to our remote Git repository, too! They will always be available and can be updated as our API evolves.
### Automated Testing
While manually validating our API specification, you'll recall that we were sending cURL requests and manually evaluating the responses for expected behavior. You might be thinking that the requests we've just created are essentially the same thing, and they still require manual sending and evaluating the response.
This is where Insomnia's API "Test" mode comes in.
Then, we create tests for our suite. We click on "New Test" and give our first test a name.
For this test, we select our "Get all users" request. Then, we write the test code with our assertion:
We write another test, asserting that our "Get existing user" request also returns a 200. Then, we write a test to assert that "Get non-existing user" returns a 404 with a message.
When we click on **Run Tests**, all of our tests pass:
Just like with our requests, we can commit and push these tests to our repository, too. Other team members working in Insomnia and synced to this repository will have access to the same test suite. Once you have a fully built-out test suite, both API spec writers and API implementation engineers can use this centralized test suite to verify correct API behavior.
### As the API Specification and Implementation Evolve
The API spec document is the first piece to change when the API designer adds new endpoints or updates existing ones. This should happen in Insomnia, and you should push changes to the spec document to the repository. You should update requests and tests to reflect expected behavior—the behavior declared by the API specification. Those updated tests will likely fail, as the API implementation has yet to be updated. This is an excellent lead-in for test-driven development on the part of your API implementation team.
Perhaps the API implementation team deploys some changes to the API service. While this is not the ideal order of operations, a similar validation process can happen, but this time in reverse. In Insomnia, you would run the test suite and realize that tests that were once passing now fail. You would update your tests and requests to conform to the updated API implementation and update your API spec accordingly. Once again, everything is in sync.
With Insomnia fully integrated into your API spec review workflow, you might consider taking advantage of two additional companion tools to level up your APIOps chops.
### Deploy to Portal
[Kong Konnect](https://konghq.com/kong-konnect)Kong Konnect is a service connectivity platform that allows your organization to publish a catalog of services for easy connection and consumption. Part of Konnect's offering includes the Developer Portal, which makes your APIs available for consumption by external developers.
API spec review is essential. With today's shift toward microservices architecture and the broad adoption of building reusable APIs, there is no getting around the need for meticulous validation of API specs. However, *manual* review is no longer a feasible option. Manually validating API specifications is time-consuming and error-prone, and therefore is neither scalable nor trustworthy.
The faster and better approach to API spec review is an API design client like Insomnia. With syntax validation in real-time, the ability to build a fully automated test suite around real API requests and repository synchronization that brings versioning and collaboration, you'll likely never go back to manual API review ever again.
## Developer agility meets compliance and security. Discover how Kong can help you become an API-first company.
What You'll Build
To explore the new integration, I'll build a realistic API platform workflow using Konnect, Kong Gateway, and Insomnia.
By the end of this tutorial, I'll have:
A Konnect Control Plane (KongAir Dev)
A local Kong Gateway Data Pl
Juhi Singh
# Insomnia 13: Native Kong Konnect Integration for Real-Time API Testing
Have you ever…. Copied an API spec out of Kong Konnect, or where you manage your APIs, pasted it into your API client, and immediately wondered if it’s the latest version? Sent an email to your platform team with the subject line “ which endpoint sh
Insomnia is a fast and lightweight open source desktop application that doubles as a tool for API design and testing and as an API client for making HTTP requests. It has built-in support for REST Client , gRPC and GraphQL . All of that is just
As more companies invest in a cloud native infrastructure , they're choosing to prioritize their applications as microservices —architecting them into distinct servers. Each component is responsible for one (and only one) feature. For example, yo
Here at Kong, we're advocates for architecting your application as a group of microservices . In this design style, individual services are responsible for handling one aspect of your application, and they communicate with other services within you
Garen Torikian
# Migrating Your Collections and Requests from Postman to Insomnia
Local-first: your data stays with you: Insomnia stores everything on your machine by default. No forced cloud sync, no account needed just to send a request. This is helpful if privacy or working in a regulated environment is a priority for you Fre
Juhi Singh
# Can You Trust What You’re Shipping? You Will with Insomnia v12
AI Assist: Clean commits, transparent teams Building trust starts with small things, like making sure every commit tells the right story. That’s where Insomnia’s v12 AI Commit capability comes in. Developers want to write code. It’s what they’re go
Haley Giuliano
# How to Test Gateway APIs Directly from Kong Konnect with Insomnia
What You'll Build
To explore the new integration, I'll build a realistic API platform workflow using Konnect, Kong Gateway, and Insomnia.
By the end of this tutorial, I'll have:
A Konnect Control Plane (KongAir Dev)
A local Kong Gateway Data Pl
Juhi Singh
# Insomnia 13: Native Kong Konnect Integration for Real-Time API Testing
Have you ever…. Copied an API spec out of Kong Konnect, or where you manage your APIs, pasted it into your API client, and immediately wondered if it’s the latest version? Sent an email to your platform team with the subject line “ which endpoint sh
Insomnia is a fast and lightweight open source desktop application that doubles as a tool for API design and testing and as an API client for making HTTP requests. It has built-in support for REST Client , gRPC and GraphQL . All of that is just
As more companies invest in a cloud native infrastructure , they're choosing to prioritize their applications as microservices —architecting them into distinct servers. Each component is responsible for one (and only one) feature. For example, yo
Here at Kong, we're advocates for architecting your application as a group of microservices . In this design style, individual services are responsible for handling one aspect of your application, and they communicate with other services within you
Garen Torikian
# Migrating Your Collections and Requests from Postman to Insomnia
Local-first: your data stays with you: Insomnia stores everything on your machine by default. No forced cloud sync, no account needed just to send a request. This is helpful if privacy or working in a regulated environment is a priority for you Fre
Juhi Singh
# Can You Trust What You’re Shipping? You Will with Insomnia v12
AI Assist: Clean commits, transparent teams Building trust starts with small things, like making sure every commit tells the right story. That’s where Insomnia’s v12 AI Commit capability comes in. Developers want to write code. It’s what they’re go
Haley Giuliano
# How to Test Gateway APIs Directly from Kong Konnect with Insomnia
What You'll Build
To explore the new integration, I'll build a realistic API platform workflow using Konnect, Kong Gateway, and Insomnia.
By the end of this tutorial, I'll have:
A Konnect Control Plane (KongAir Dev)
A local Kong Gateway Data Pl
Juhi Singh
# Insomnia 13: Native Kong Konnect Integration for Real-Time API Testing
Have you ever…. Copied an API spec out of Kong Konnect, or where you manage your APIs, pasted it into your API client, and immediately wondered if it’s the latest version? Sent an email to your platform team with the subject line “ which endpoint sh
Insomnia is a fast and lightweight open source desktop application that doubles as a tool for API design and testing and as an API client for making HTTP requests. It has built-in support for REST Client , gRPC and GraphQL . All of that is just
As more companies invest in a cloud native infrastructure , they're choosing to prioritize their applications as microservices —architecting them into distinct servers. Each component is responsible for one (and only one) feature. For example, yo
Here at Kong, we're advocates for architecting your application as a group of microservices . In this design style, individual services are responsible for handling one aspect of your application, and they communicate with other services within you
Garen Torikian
# Migrating Your Collections and Requests from Postman to Insomnia
Local-first: your data stays with you: Insomnia stores everything on your machine by default. No forced cloud sync, no account needed just to send a request. This is helpful if privacy or working in a regulated environment is a priority for you Fre
Juhi Singh
# Can You Trust What You’re Shipping? You Will with Insomnia v12
AI Assist: Clean commits, transparent teams Building trust starts with small things, like making sure every commit tells the right story. That’s where Insomnia’s v12 AI Commit capability comes in. Developers want to write code. It’s what they’re go
Haley Giuliano
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.