In this section of the blog post, we're going to evolve the architecture one more time to add two new LLM infrastructures sitting behind the Gateway: Mistral and Anthropic, in addition to OpenAI.
### Multi-LLM scenarios and use cases
In the main scenario, the Agent needs to communicate to multiple LLMs selectively, depending on its needs. Having the Kong AI Gateway intermediating the communication, provides several benefits:
- Decide which LLM to use based on the cost, latency times, reliability, and mainly on semantics (some LLMs are better at a specific topic, others at coding, etc.).
- Route queries to the appropriate LLM(s).
- Act based on the results.
- Fallback and redundancy: If one LLM fails or is slow, use another.
### Semantic Routing Architecture
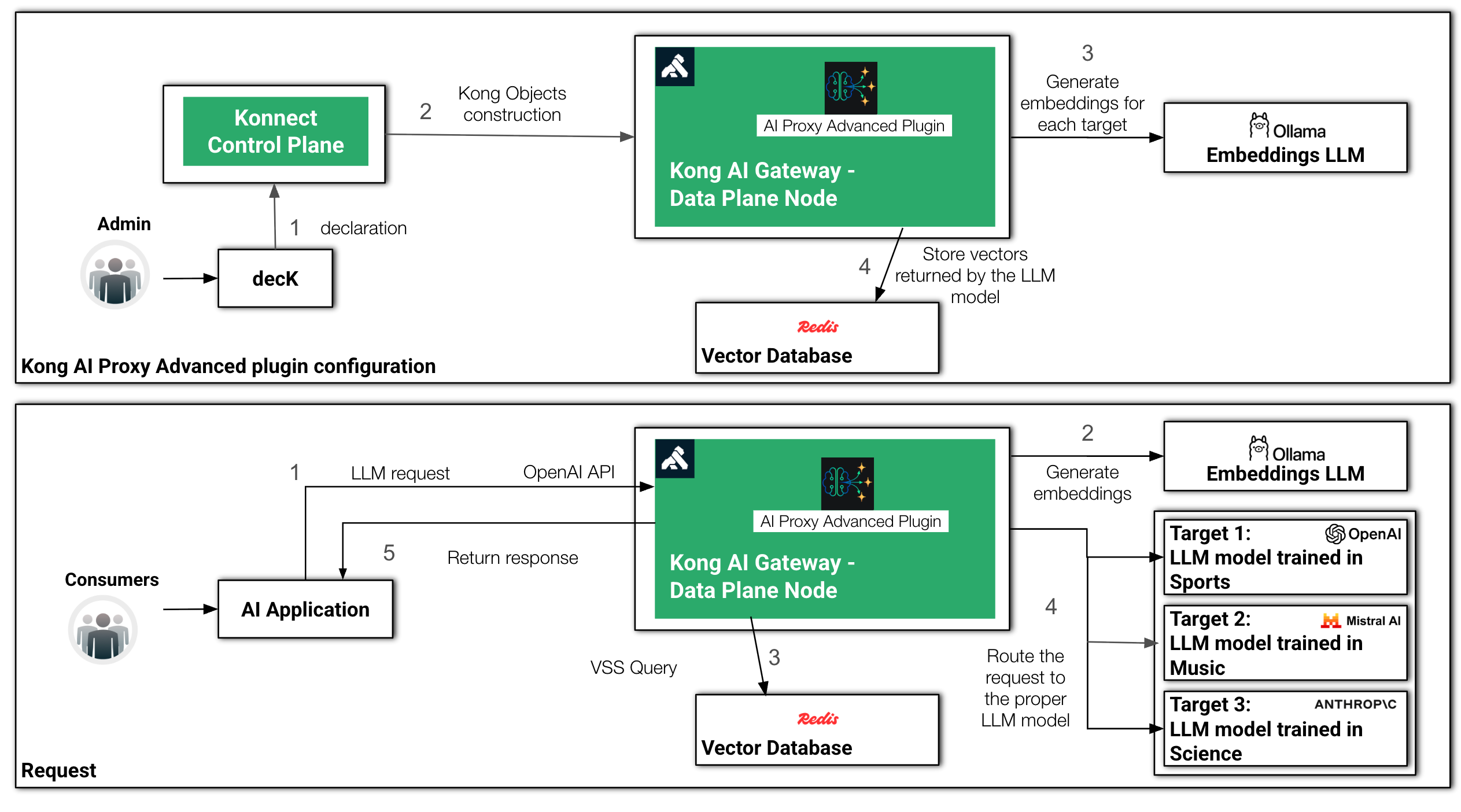
Kong AI Gateway offers a range of semantic capabilities including Caching and Prompt Guard. To implement the Multi-LLM Agent infrastructure, we're going to use the Semantic Routing capability provided by the AI Proxy Advanced plugin we've been using for the entire series of blog posts.
The AI Proxy Advanced Plugin has the ability to implement various load balancing policies, including distributing requests based on semantics or similarity between the prompts and description of each model. For example, consider that you have three models: the first one has been trained in sports, the second in music and the third one in science. What we want to do is route the requests accordingly, based on the topic each prompt has presented.
What happens is that, during configuration time, done by, for example, submitting decK declarations to Konnect Control Plane, the plugin hits the embeddings model for each description and stores the embeddings into the vector database.
Then, for each incoming request, the plugin submits a VSS (or Virtual Similarity Search) to the vector database to decide to which LLM the request should be routed to.
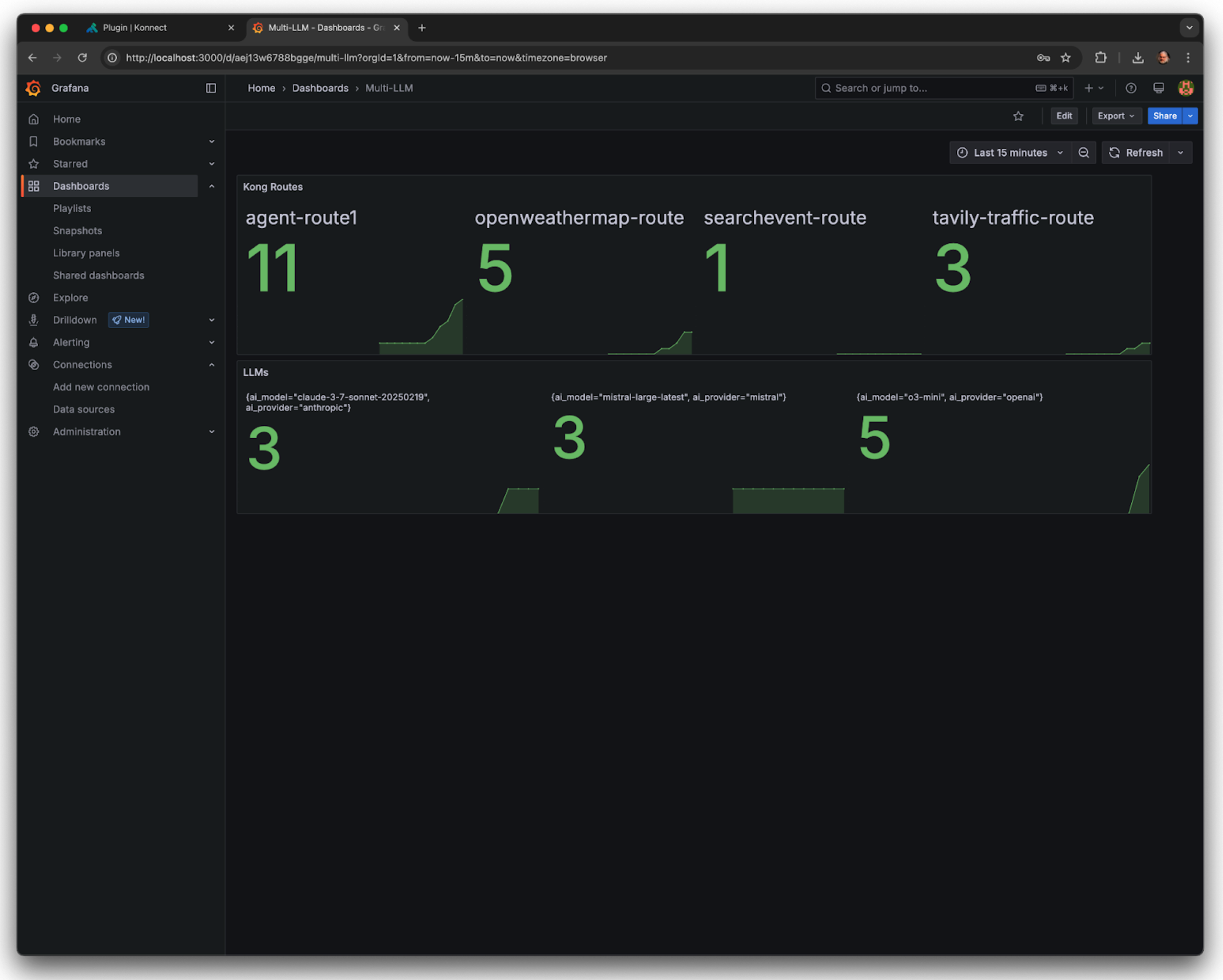
*Semantic Routing configuration and request processing times*
The pre-built function “create_react_agent” is very helpful to implement the fundamental ReAct graph that we created programmatically before. That is, the agent is composed by:
- A Node sending requests to the LLM
- A “conditional_edge” associated with this Node and making decisions about how the Agent should proceed when getting a response from the LLM.
- A Node to call tools
In fact, if you print the output of the graph with “graph.get_graph().draw_ascii())” function again, you'll see the same graph structure we'd in the previous version of the agent.
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain_community.utilities.openweathermap import OpenWeatherMapAPIWrapper
import httpx
@tool
def get_weather(location: str):"""Call to get the weather from a specific location."""
print("starting get_weather function")
openweathermap_url = kong_dp + "/openweathermap-route" result = httpx.get(openweathermap_url, params={"q": location})
print("finishing get_weather function")
return result.json()
@tool
def get_music_concert(location: str):"""Call to get the events in a given location."""
print("starting get_music_concerts function")
searchevent_url = kong_dp + "/searchevent-route" location = location.replace(" ","_")
data={"query":{"$query":{"$and":[{"categoryUri":"dmoz/Arts/Music/Bands_and_Artists"},{"locationUri": f"http://en.wikipedia.org/wiki/{location}"}]},"$filter":{"forceMaxDataTimeWindow":"31"}},"resultType":"events","eventsSortBy":"date","eventImageCount":1,"storyImageCount":1} result = httpx.post(searchevent_url, json=data)
print("finishing get_music_concert function")
return result.json()["events"]["results"][0]["concepts"][0]["label"]["eng"]
@tool
def get_traffic(location: str):"""Call to get the traffic situation of a given location."""
print("starting get_traffic function")
traffic_url = kong_dp + "/tavily-traffic-route" data={"query": f"Generally, what is the worst time of day for car traffic in {location}","search_depth":"advanced"} result = httpx.post(traffic_url, json=data)
print("finishing get_traffic function")
return result.json()["results"][0]["content"]tools = [get_weather, get_music_concert, get_traffic]kong_dp = "http://127.0.0.1"agent_url = kong_dp + "/agent-route"client = ChatOpenAI(base_url=agent_url, model="", api_key="dummy", default_headers={"apikey":"123456"})
graph = create_react_agent(client, tools)
print(graph.get_graph().draw_ascii())
def print_stream(stream): for s in stream: message = s["messages"][-1] if isinstance(message, tuple): print(message)
else: message.pretty_print()
inputs = {"messages":[("user","In my next vacation, I'm planning to visit the city where Jimi Hendrix was born? Is there any music concert to see? Also provide weather and traffic information about the city")]}print_stream(graph.stream(inputs, stream_mode="values"))
For this execution, the AI Proxy Advanced Plugin will route the request to Mistral, since it's related to music.
### decK Declaration
Below you can check the new decK declaration for the Semantic Routing use case. The AI Proxy Advanced plugin has the following sections configured:
- embeddings: where the plugin should go to generate embeddings related to the LLM models
- vectordb: responsible for storing the embeddings and handling the VSS queries
- targets: an entry for each LLM model. The most important setting is the description, which defines where the plugin should route the requests to.
The first step is to create the Docker image for the server. The code below removes the lines where we execute the graph. Another change is for the Kong Data Plane address, referring to the Kubernetes FQDN Service.
from langgraph.prebuilt import create_react_agent
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain_community.utilities.openweathermap import OpenWeatherMapAPIWrapper
import httpx
@tool
def get_weather(location: str):"""Call to get the weather from a specific location."""
print("calling get_weather function")
openweathermap_url = kong_dp + "/openweathermap-route" result = httpx.get(openweathermap_url, params={"q": location})
return result.json()
@tool
def get_music_concerts(location: str):"""Call to get the events in a given location."""
print("calling get_music_concerts function")
searchevent_url = kong_dp + "/searchevent-route" location = location.replace(" ","_")
data={"query":{"$query":{"$and":[{"categoryUri":"dmoz/Arts/Music/Bands_and_Artists"},{"locationUri": f"http://en.wikipedia.org/wiki/{location}"}]},"$filter":{"forceMaxDataTimeWindow":"31"}},"resultType":"events","eventsSortBy":"date","eventImageCount":1,"storyImageCount":1} result = httpx.post(searchevent_url, json=data)
return result.json()["events"]["results"][0]["concepts"][0]["label"]["eng"]
@tool
def get_traffic(location: str):"""Call to get the traffic situation of a given location."""
print("calling get_traffic function")
traffic_url = kong_dp + "/tavily-traffic-route" data={"query": f"Generally, what is the worst time of day for car traffic in {location}","search_depth":"advanced"} result = httpx.post(traffic_url, json=data)
return result.json()["results"][0]["content"]tools = [get_weather, get_music_concerts, get_traffic]#kong_dp = "http://127.0.0.1"kong_dp = "http://proxy1.kong"agent_url = kong_dp + "/agent-route"client = ChatOpenAI(base_url=agent_url, model="", api_key="dummy", default_headers={"apikey":"123456"})
graph = create_react_agent(client, tools)
#### langgraph.json
The Docker image requires a “langgraph.json” file with the dependencies and the name of the graph variable inside the code, in our case “graph”.
The “values.yaml” defines the service as “LoadBalancer” to make it available. Currently, only Postgres is supported as a database for LangGraph Server and Redis as the task queue. The file specifies Postgres resources for its Kubernetes deployment. Finally, LangGraph Server requires a [LangSmith](https://docs.smith.langchain.com/)LangSmith API Key. LangSmith is a platform used to monitor your server. Log to [LangSmith](https://smith.langchain.com/)LangSmith and create your API Key.
curl -s http://localhost:8090/runs/wait \--header 'Content-Type: application/json' \
--data '{"assistant_id":"agent","input":{"messages":[{"role":"user","content":"In my next vacation, I''m planning to visit the city where Jimi Hendrix was born? Is there any music concert to see? Also provide weather and traffic information about the city."}]}}' | jq -r '.messages[5].content'
The expected response is:
In Seattle, it is currently overcast with a temperature of 69.8°F (20.4°C) and feels like 68.9°F (20.5°C). The city has a humidity of 80% and wind speed of 4.12 mph from the west. There is a music concert of Phish happening in the city, but be aware that the worst period of travel is generally Thursday afternoons, especially 4-6 pm.
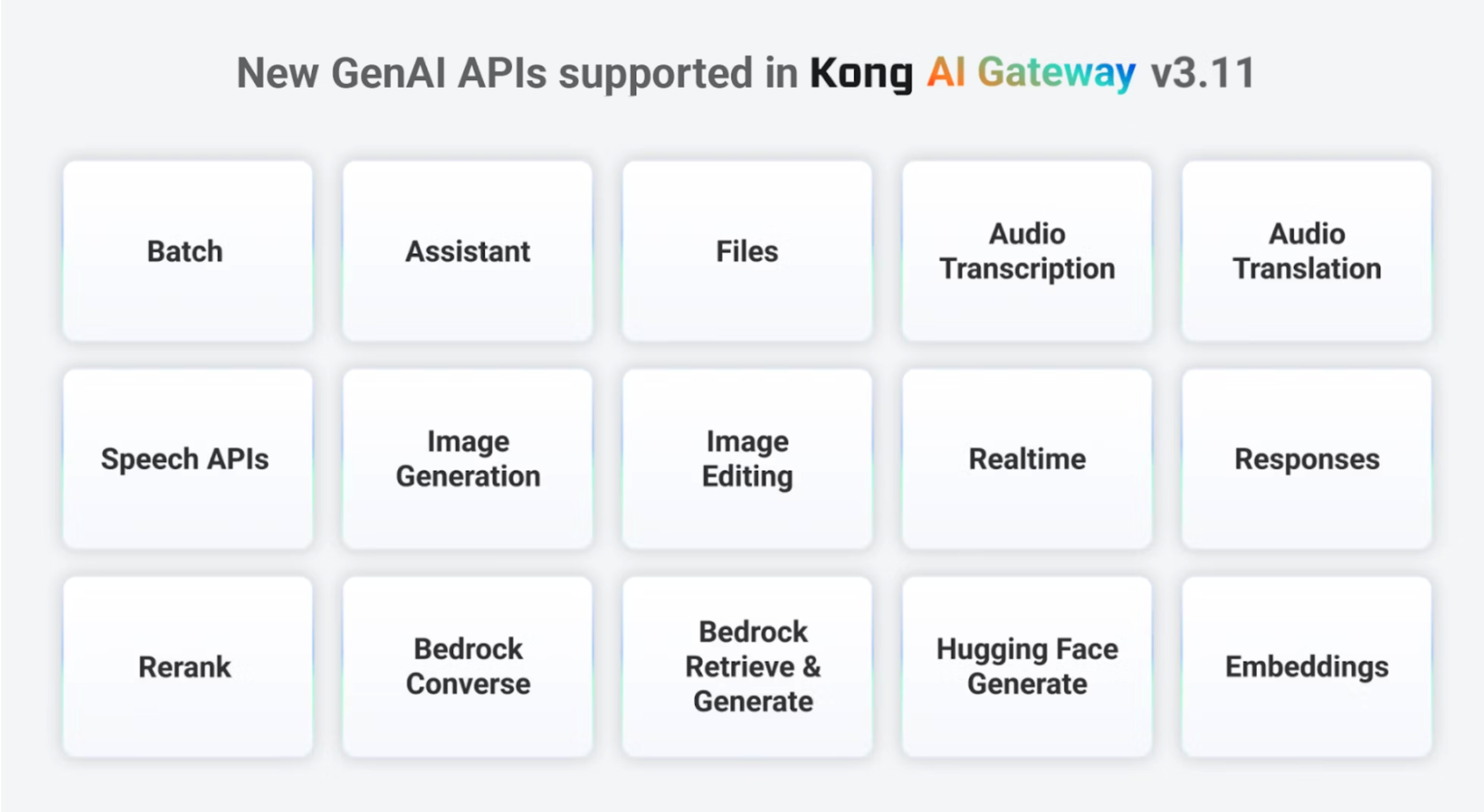
## Kong AI Gateway 3.11 and Support for New GenAI Models
With Kong AI Gateway 3.11, we'll be able to support other GenAI infrastructures besides LLMs - which include video, images, etc. The following diagram lists the new modes supported:
In order to do it, Kong AI Gateway 3.11 defines new configuration parameters like:
- genai-category: is used to configure the GenAI infrastructure that the gateway protects. Besides `image/generation`, it supports, for example, `text/generation` and `text/embeddings` for regular LLMs and embedding models, `audio/speech` and `audio/transcription` for audio based models implementing speech recognition, audio-to-text, etc.
- route_type: this existing parameter has been extended to support new types, such as:
- LLM: `llm/v1/responses`, `llm/v1/assistants`, `llm/v1/files` and `llm/v1/batches`
- Audio: `audio/v1/audio/speech`, `audio/v1/audio/transcriptions` and `audio/v1/audio/translations`
- Realtime: `realtime/v1/realtime`
## Conclusion
This blog post has presented a basic AI Agent using Kong AI Gateway and LangGraph. Redis was used as a vector database and a local Ollama was the infrastructure that provided the Embedding Model.
Behind the Gateway, we've three LLM infrastructures (OpenAI, Mistral and Anthropic) and three external functions were used as tools by the AI Agent.
The Gateway was responsible for abstracting the LLM infrastructures and protecting the external functions with specific policies including Rate Limiting and API Keys.
Built on top of Kong API Gateway, the Kong AI Gateway is designed to address key challenges in enterprise AI adoption. Modern AI applications rarely rely on a single model; instead, they orchestrate multiple GenAI providers, agent frameworks, Age
Anika Suri
# Practical Strategies to Monetize AI APIs in Production
Traditional APIs are, in a word, predictable. You know what you're getting: Compute costs that don't surprise you Traffic patterns that behave themselves Clean, well-defined request and response cycles AI APIs, especially anything that runs on LLMs
AI vendor lock-in is the condition where switching providers requires rewriting application code, reconfiguring infrastructure, or retraining teams. Unlike traditional SaaS lock-in, AI vendor lock-in carries compounding risks: proprietary prompt for
Kong
# Kong AI/MCP Gateway and Kong MCP Server Technical Breakdown
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
# AI Voice Agents with Kong AI Gateway and Cerebras
Kong Gateway is an API gateway and a core component of the Kong Konnect platform . Built on a plugin-based extensibility model, it centralizes essential functions such as proxying, routing, load balancing, and health checking, efficiently manag
Claudio Acquaviva
# From Chaos to Control: How Kong AI Gateway Streamlined My GenAI Application
🚧 The challenge: Scaling GenAI with governance While building a GenAI-powered agent for one of our company websites, I integrated components like LLM APIs, embedding models, and a RAG (Retrieval-Augmented Generation) pipeline. The application was d
Sachin Ghumbre
# AI Guardrails: Ensure Safe, Responsible, Cost-Effective AI Integration
Why AI guardrails matter It's natural to consider the necessity of guardrails for your sophisticated AI implementations. The truth is, much like any powerful technology, AI requires a set of protective measures to ensure its reliability and integrit
Jason Matis
# A Unified Gateway for APIs + Agentic Applications on VMware VKS with Kong Konnect
Built on top of Kong API Gateway, the Kong AI Gateway is designed to address key challenges in enterprise AI adoption. Modern AI applications rarely rely on a single model; instead, they orchestrate multiple GenAI providers, agent frameworks, Age
Anika Suri
# Practical Strategies to Monetize AI APIs in Production
Traditional APIs are, in a word, predictable. You know what you're getting: Compute costs that don't surprise you Traffic patterns that behave themselves Clean, well-defined request and response cycles AI APIs, especially anything that runs on LLMs
AI vendor lock-in is the condition where switching providers requires rewriting application code, reconfiguring infrastructure, or retraining teams. Unlike traditional SaaS lock-in, AI vendor lock-in carries compounding risks: proprietary prompt for
Kong
# Kong AI/MCP Gateway and Kong MCP Server Technical Breakdown
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
# AI Voice Agents with Kong AI Gateway and Cerebras
Kong Gateway is an API gateway and a core component of the Kong Konnect platform . Built on a plugin-based extensibility model, it centralizes essential functions such as proxying, routing, load balancing, and health checking, efficiently manag
Claudio Acquaviva
# From Chaos to Control: How Kong AI Gateway Streamlined My GenAI Application
🚧 The challenge: Scaling GenAI with governance While building a GenAI-powered agent for one of our company websites, I integrated components like LLM APIs, embedding models, and a RAG (Retrieval-Augmented Generation) pipeline. The application was d
Sachin Ghumbre
# AI Guardrails: Ensure Safe, Responsible, Cost-Effective AI Integration
Why AI guardrails matter It's natural to consider the necessity of guardrails for your sophisticated AI implementations. The truth is, much like any powerful technology, AI requires a set of protective measures to ensure its reliability and integrit
Jason Matis
# A Unified Gateway for APIs + Agentic Applications on VMware VKS with Kong Konnect
Built on top of Kong API Gateway, the Kong AI Gateway is designed to address key challenges in enterprise AI adoption. Modern AI applications rarely rely on a single model; instead, they orchestrate multiple GenAI providers, agent frameworks, Age
Anika Suri
# Practical Strategies to Monetize AI APIs in Production
Traditional APIs are, in a word, predictable. You know what you're getting: Compute costs that don't surprise you Traffic patterns that behave themselves Clean, well-defined request and response cycles AI APIs, especially anything that runs on LLMs
AI vendor lock-in is the condition where switching providers requires rewriting application code, reconfiguring infrastructure, or retraining teams. Unlike traditional SaaS lock-in, AI vendor lock-in carries compounding risks: proprietary prompt for
Kong
# Kong AI/MCP Gateway and Kong MCP Server Technical Breakdown
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
# AI Voice Agents with Kong AI Gateway and Cerebras
Kong Gateway is an API gateway and a core component of the Kong Konnect platform . Built on a plugin-based extensibility model, it centralizes essential functions such as proxying, routing, load balancing, and health checking, efficiently manag
Claudio Acquaviva
# From Chaos to Control: How Kong AI Gateway Streamlined My GenAI Application
🚧 The challenge: Scaling GenAI with governance While building a GenAI-powered agent for one of our company websites, I integrated components like LLM APIs, embedding models, and a RAG (Retrieval-Augmented Generation) pipeline. The application was d
Sachin Ghumbre
# AI Guardrails: Ensure Safe, Responsible, Cost-Effective AI Integration
Why AI guardrails matter It's natural to consider the necessity of guardrails for your sophisticated AI implementations. The truth is, much like any powerful technology, AI requires a set of protective measures to ensure its reliability and integrit
Jason Matis
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.