# Kong AI Gateway Goes GA, New Enterprise Capabilities Added
*More easily manage AI spend, build AI agents and chatbots, get real-time AI responses, and ensure content safety*
Marco Palladino
CTO and Co-Founder of Kong
We're introducing several new Kong AI Gateway capabilities in Kong Gateway 3.7 and Kong Gateway Enterprise 3.7, including enterprise-only and OSS improvements. Read on for a full rundown of the new AI-focused features.
## AI Gateway becomes a GA capability (OSS + Enterprise)
Kong AI Gateway supports a wide range of use cases to help accelerate the adoption and rollout of new AI applications into production.
## Support for the existing OpenAI SDK
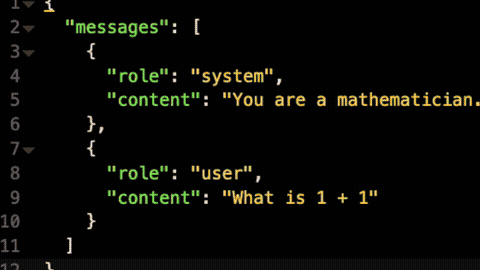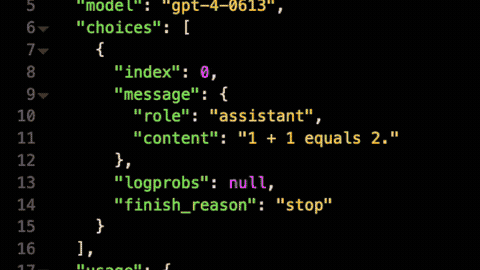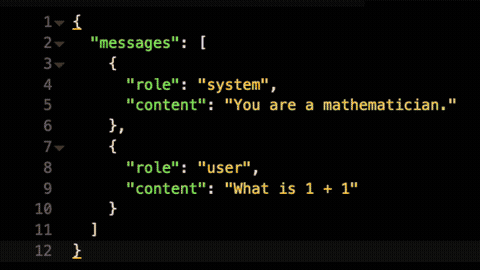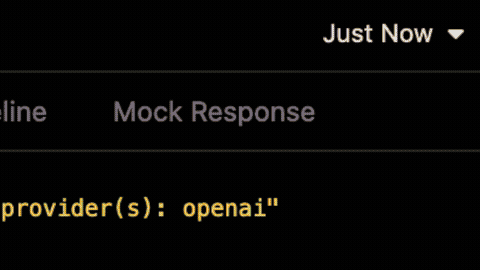
Kong AI Gateway provides one API to access all of the LLMs it supports. To accomplish this, we've standardized on the OpenAI API specification. This will help developers to onboard more quickly by providing them with an API specification that they’re already familiar with.
In this new release, we're making it even easier to build AI agents and applications using Kong AI Gateway by natively supporting the OpenAI SDK client library. You can start using LLMs behind the AI Gateway simply by redirecting your requests to a URL that points to a route of the AI Gateway.
If you have existing business logic written using the OpenAI SDK, you can re-use it to consume every LLM supported by Kong AI Gateway, removing the need to alter your code, given it will be 100% compatible.
## Introducing AI streaming support (OSS + Enterprise)
Streaming in the “ai-proxy” plugin when consuming every LLM provider is now natively supported by Kong AI Gateway. This unlocks more real-time experiences, rather than having to wait for the full response to be processed by the LLM before sending it back to the client.
The response will now be sent token-by-token in HTTP response chunks (SSE). The capability can be enabled in the plugin configuration by setting the following property of “ai-proxy”:
Which then allows the clients to request streaming by making requests like:
{"prompt":"What is 1 + 1?","stream":true}
With this capability, Kong AI Gateway users can create more compelling and interactive AI experiences.
## New plugin: AI token rate limiting advanced (Enterprise)
We're introducing a new enterprise-only AI capability to rate-limit the usage of any LLM by the number of request tokens. By enabling the new “ai-rate-limiting-advanced” plugin, customers can better manage AI spend across the board by specifying different levels of consumption for different teams in the organization. For self-hosted LLM providers, customers will be able to better scale their traffic on the AI infrastructure when the AI traffic increases across the applications.
Kong already provides API rate-limiting capabilities which rate-limits based on the number of requests that are being sent to an API. The new ai-rate-limiting-advanced plugin instead focuses on the number of AI tokens requested, regardless of the number of raw HTTP requests being sent to it. If the customer wants to rate-limit both raw requests and AI tokens specifically, the ai-rate-limiting-advanced plugin can work in combination with the standard Kong rate-limiting plugin.
The ai-rate-limiting-advanced plugin is the only rate-limiting plugin available today for AI.
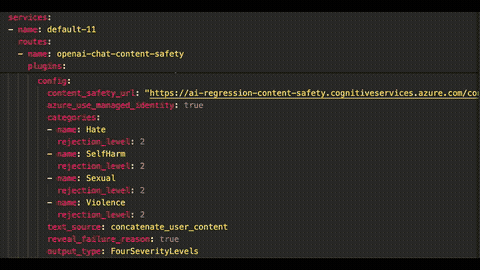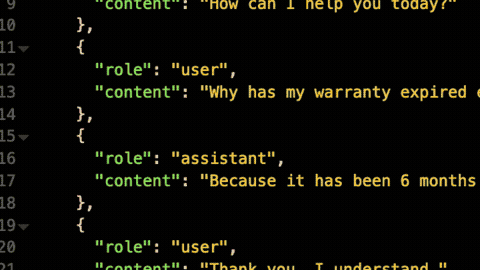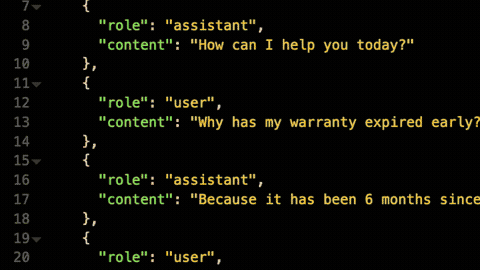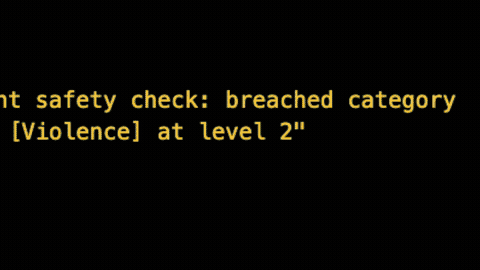
## New plugin: New AI Azure Content Safety (Enterprise)
For example, the customer may want to detect and filter out all violence, hate, sexual, and self-harm content across all prompts sent to any LLM provider in Kong AI Gateway using Azure’s native services.
## Dynamic URL-sourced LLM model in ai-proxy (OSS + Enterprise)
It's now possible to configure the requested model dynamically via the URL path requested by the client. Additionally, users can consume a model by hard coding its name in the plugin configuration. By enabling this capability, it becomes easier to scale Kong AI Gateway across the teams that want to experiment with a wide variety of models, without having to pre-configure them in the “ai-proxy” plugin.
By allowing “ai-proxy” to set up the LLM route using the URL requested by the client, it's possible to apply the “ai-proxy” plugin once and then support all models available by the underlying AI provider by parsing the URL path requested instead.
This capability can be configured with the new “config.route_source” configuration parameter in “ai-proxy”.
## Support for Anthropic Claude 2.1 Messages API (OSS + Enterprise)
Kong AI Gateway provides one API interface to consume models across both cloud and self-hosted providers. We've expanded our unified API interface to also support the Anthropic Claude 2.1 Messages API typically used to create chatbots or virtual assistant applications. The API manages the conversational exchanges between a user and an Anthropic Claude model (assistant).
Kong AI Gateway will continuously add support for more LLMs and models based on user demand.
## Updated AI analytics format (OSS + Enterprise)
With Kong AI Gateway going into GA, we've updated our analytics logging format for all AI requests processed by Kong.
With this new logging format, we can now measure consumption across every model that has been requested by “ai-proxy,” “ai-request-transformer,” and “ai-response-transformer.”
"ai":{"ai-proxy":{"meta":{"request_model":"gpt-35-turbo","provider_name":"azure","response_model":"gpt-35-turbo","plugin_id":"5df193be-47a3-4f1b-8c37-37e31af0568b"},"payload":{},"usage":{"prompt_token":89,"completion_token":56,"total_tokens":145}}, … more AI Plugins
This new analytics log format replaces the old one.
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
# RAG Application with Kong AI Gateway, AWS Bedrock, Redis and LangChain
For the last couple of years, Retrieval-Augmented Generation (RAG) architectures have become a rising trend for AI-based applications. Generally speaking, RAG offers a solution to some of the limitations in traditional generative AI models, such as
AI governance is the set of principles, roles, processes, and controls an organization uses to deploy AI safely, ethically, and in compliance with the law. It defines who is accountable for AI decisions, how risk is managed, and how systems stay tra
Kong
# How We Used Agentic AI to Fix Kong Gateway's Flakiest Tests
Quality is at the core of every product we build. To move fast without compromising on quality, we rely on an extensive set of test suites that tell us quickly whether a change has caused a regression. Those suites are large enough that a single ful
Datong Sun
# Move More Agentic Workloads to Production with AI Gateway 3.13
MCP ACLs, Claude Code Support, and New Guardrails
New providers, smarter routing, stronger guardrails — because AI infrastructure should be as robust as APIs We know that successful AI connectivity programs often start with an intense focus on how
Greg Peranich
# Kong Konnect: Introducing HashiCorp Vault Support for LLMs
If you're a builder, you likely keep sending your LLM credentials on every request from your agents and applications. But if you operate in an enterprise environment, you'll want to store your credentials in a secure third-party like HashiCorp Vault
Marco Palladino
# Kong AI Manager: Govern & Observe Agentic Traffic to Thousands of LLMs
Today, we're excited to announce the general availability of AI Manager in Kong Konnect, the platform to manage all of your API, AI, and event connectivity across all modern digital applications and AI agents. Kong already provides the fastest and m
Marco Palladino
# Kong AI/MCP Gateway and Kong MCP Server Technical Breakdown
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
# RAG Application with Kong AI Gateway, AWS Bedrock, Redis and LangChain
For the last couple of years, Retrieval-Augmented Generation (RAG) architectures have become a rising trend for AI-based applications. Generally speaking, RAG offers a solution to some of the limitations in traditional generative AI models, such as
AI governance is the set of principles, roles, processes, and controls an organization uses to deploy AI safely, ethically, and in compliance with the law. It defines who is accountable for AI decisions, how risk is managed, and how systems stay tra
Kong
# How We Used Agentic AI to Fix Kong Gateway's Flakiest Tests
Quality is at the core of every product we build. To move fast without compromising on quality, we rely on an extensive set of test suites that tell us quickly whether a change has caused a regression. Those suites are large enough that a single ful
Datong Sun
# Move More Agentic Workloads to Production with AI Gateway 3.13
MCP ACLs, Claude Code Support, and New Guardrails
New providers, smarter routing, stronger guardrails — because AI infrastructure should be as robust as APIs We know that successful AI connectivity programs often start with an intense focus on how
Greg Peranich
# Kong Konnect: Introducing HashiCorp Vault Support for LLMs
If you're a builder, you likely keep sending your LLM credentials on every request from your agents and applications. But if you operate in an enterprise environment, you'll want to store your credentials in a secure third-party like HashiCorp Vault
Marco Palladino
# Kong AI Manager: Govern & Observe Agentic Traffic to Thousands of LLMs
Today, we're excited to announce the general availability of AI Manager in Kong Konnect, the platform to manage all of your API, AI, and event connectivity across all modern digital applications and AI agents. Kong already provides the fastest and m
Marco Palladino
# Kong AI/MCP Gateway and Kong MCP Server Technical Breakdown
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
# RAG Application with Kong AI Gateway, AWS Bedrock, Redis and LangChain
For the last couple of years, Retrieval-Augmented Generation (RAG) architectures have become a rising trend for AI-based applications. Generally speaking, RAG offers a solution to some of the limitations in traditional generative AI models, such as
AI governance is the set of principles, roles, processes, and controls an organization uses to deploy AI safely, ethically, and in compliance with the law. It defines who is accountable for AI decisions, how risk is managed, and how systems stay tra
Kong
# How We Used Agentic AI to Fix Kong Gateway's Flakiest Tests
Quality is at the core of every product we build. To move fast without compromising on quality, we rely on an extensive set of test suites that tell us quickly whether a change has caused a regression. Those suites are large enough that a single ful
Datong Sun
# Move More Agentic Workloads to Production with AI Gateway 3.13
MCP ACLs, Claude Code Support, and New Guardrails
New providers, smarter routing, stronger guardrails — because AI infrastructure should be as robust as APIs We know that successful AI connectivity programs often start with an intense focus on how
Greg Peranich
# Kong Konnect: Introducing HashiCorp Vault Support for LLMs
If you're a builder, you likely keep sending your LLM credentials on every request from your agents and applications. But if you operate in an enterprise environment, you'll want to store your credentials in a secure third-party like HashiCorp Vault
Marco Palladino
# Kong AI Manager: Govern & Observe Agentic Traffic to Thousands of LLMs
Today, we're excited to announce the general availability of AI Manager in Kong Konnect, the platform to manage all of your API, AI, and event connectivity across all modern digital applications and AI agents. Kong already provides the fastest and m
Marco Palladino
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.