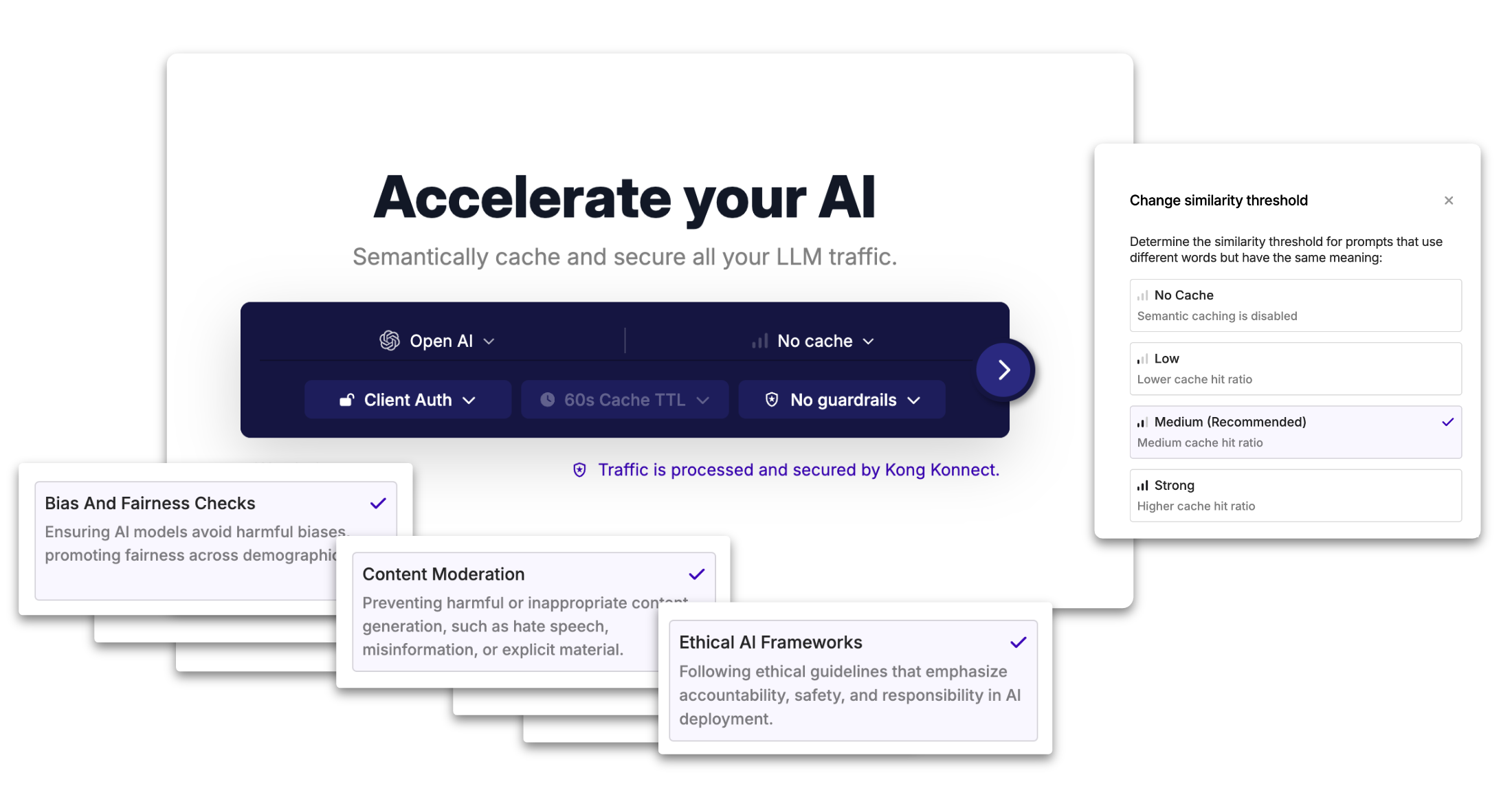
*You can easily configure the AI Runner’s similarity threshold.*
Additionally, you can configure the caching time to live (TTL) for each AI Runner, as well as store credentials for your LLM within the AI Runner itself. This makes it so that you don’t need to update your applications when you want to modify your credentials, as it will be applied on the fly by the AI Runner.
## Secure AI with out-of-the-box guardrails
It is crucial to ensure that AI traffic follows specific guidelines for improving security, reducing mishandling of sensitive customer information, and returning better responses.
As such, the AI Runner ships with AI guardrails out of the box. This makes it easier to protect your LLM traffic against security attacks while ensuring that personal and sensitive data is not returned by the LLMs.