Let’s take a look at each one of these capabilities.
*Kong AI Gateway is the combination of 10+ AI plugins, in addition to every other plugin (100+) supported by the underlying Kong Gateway technology.*
## Understanding Kong AI Gateway’s new semantic intelligence
Today, [Kong’s AI Gateway](https://konghq.com/products/kong-ai-gateway)Kong’s AI Gateway is being used in between the AI applications that developers are building and the GenAI models that they are consuming. Textual and media prompts (video, image, audio, etc.) are constantly flowing through the AI Gateway. With this new release, we're introducing the ability for the AI Gateway to semantically understand these prompts, which will in turn further improve the performance, security, and routing of AI applications.
The AI Gateway can now better understand user prompts via the introduction of **semantic intelligence**. This brings the ability to generate embeddings on the fly for each prompt and to store them in a vector database of choice.
Starting from this new 3.8 release, the AI Gateway can now understand if the prompts share a high or low level of similarity among each other, even if the prompts are using different words.
*This is how Kong AI Gateway 3.8 may understand different prompts before being sent to an upstream LLM technology.*
This capability can also be entirely configured by the user with respect to which embeddings, models, and vector databases should be used.
## Introducing AI Semantic Cache
Kong AI Gateway 3.8 ships with a new “AI Semantic Cache” plugin that dramatically improves the performance of GenAI applications and significantly reduces LLM processing costs as well. It's now possible to provide intelligent caching across prompts that share the same meaning, but perhaps use different words to express this meaning.
**This content contains a video which can not be displayed in Agent mode**
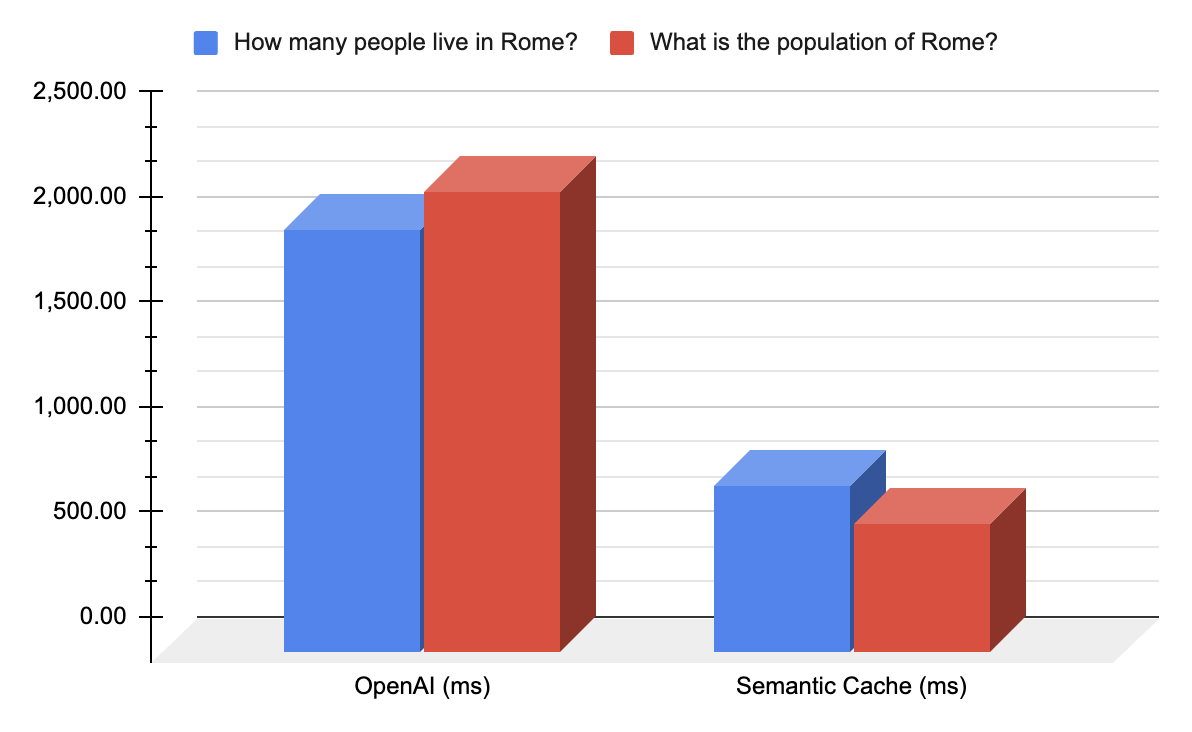
In the following benchmark, we show the processing latency (in milliseconds) of two similar prompts (“How many people live in Rome?” and “What is the population of Rome?”) across both vanilla OpenAI and through AI Gateway with semantic caching enabled.
As you can see in this benchmark, consuming OpenAI is **150% slower** than using the equivalent prompt with semantic caching enabled. In the second prompt, OpenAI is **255% slower **than using the same prompt with the Kong AI Gateway with semantic caching enabled.
*With semantic caching, Kong AI Gateway can accelerate all GenAI traffic significantly. The lower the value, the lower the latency.*
The results of this benchmark showcase that every end-user experience that is built with GenAI could be delivered 3-4x faster with Kong’s AI Gateway, which is pretty neat. In some cases, the performance improvements exceed 10x.
Installing the semantic cache plugin is as easy as installing a regular Kong Gateway plugin. This is an example configuration:
Of course, there are many more configuration options, but this really shows how easy it is to use it.
## Introducing AI Semantic Prompt Guard
Kong AI Gateway already supports the ability to create guardrails of allow-lists and deny-lists to block specific prompts via the “AI Prompt Guard” plugin. We're further expanding on this capability with a new “AI Semantic Prompt Guard” plugin.
Unlike the traditional Prompt Guard plugin that was leveraging regex to identify the patterns, this new plugin can semantically block the intent and meaning of the prompt, whether it matches a specific keyword or not.
For example, we can block “all political content” from being discussed in the AI Gateway, and that will work regardless of the actual words being used in the prompt.
*All political content will be blocked, but the “steak” question will go through.*
The new AI Semantic Prompt Guard is great for improving accuracy. It can still be used together with the traditional AI Prompt Guard for better performance in evaluating the guardrail rules.
## Introducing advanced load balancing, and semantic routing
To increase the operational maturity of running GenAI in production, we're introducing six new load-balancing algorithms specifically designed for LLM load balancing, including a semantic routing capability. These capabilities are shipping in the “AI Proxy Advanced” plugin.
Organizations running GenAI at scale will find they need to increase their maturity posture to consider all of the AI models that they deploy, fine-tune, and use to become products. Just like APIs need a lifecycle, GenAI models need a product lifecycle too. As users continuously fine-tune new models and make them available for consumption, there needs to be an infrastructure in place to provide modern load balancing for blue/green deployments, canary releases, and failover strategies. And this is exactly what this new capability allows us to do.
*The six new load balancing algorithms for AI.*
The algorithms are:
- **Round robin**: route across all LLM/Model pairs in the target group.
- **Weighted**: route with custom weights to any LLM/Model pair in the target group.
- **Least busy**: route to the LLM/model pair with the least number of ongoing calls.
- **Lowest usage**: route to the LLM/model pair with the lowest TPM usage.
- **Lowest latency**: route to the LLM/model pair with the lowest response time.
- **Semantic routing**: route to the LLM/model pair with the highest semantic similarity.
This new capability also ships with the ability to configure the number of retries and can be incredibly useful for scenarios like:
- Providing high availability across LLM/model pairs with failover mechanisms.
- A new model being available, to slowly route traffic to it, and making sure the responses and performance are still acceptable.
- Running on a more cost-effective self-hosted model but still using a cloud model as a failover in case of performance issues.
- Being able to always use the LLM/model with the best performance to improve the end-user experience.
The semantic routing model is quite unique compared to the others, as it enables the AI Gateway to route to the model that’s best fine-tuned for a specific incoming prompt, without having to know in advance what model to consume. This is very effective in organizations where the developers building the AI applications are different from the developers fine-tuning the models.
With semantic routing, Kong AI Gateway will intelligently determine at runtime which model is best suited to handle the incoming prompt, automatically picking the right one based on a similarity threshold that you can configure.
For example, you can fine-tune a model to be very good at answering sales questions, and then you can fine-tune another model to be very good at answering support questions. Based on the incoming prompt, the AI Gateway will choose the right model for the job.
*With semantic routing, the AI Gateway intelligently chooses the right model for the job.*
## Introducing support for more LLM providers
With this new release of AI Gateway, we're also introducing official support for AWS Bedrock and GCP Vertex (including Gemini). This is in addition to the other LLM providers we already support: OpenAI, Azure AI, Anthropic, Cohere, Mistral, and LLAMA.
By continuously expanding the LLM technologies that we natively support, we're providing access to thousands of public and private models that can be used immediately via AI Gateway, including private fine-tuned models that you may have created internally.
Also, the new LLM providers are automatically supported in our “ai-proxy” and “ai-proxy-advanced” plugins, where you can build your GenAI code once and automatically support all LLMs at the “flip of a switch” without having to replace your client SDK or your code. This makes it extremely easy to not only benchmark and integrate models from multiple LLMs, but it also allows for cross-LLM and cross-model routing without any change in your applications for high availability and failover scenarios.
## Migrating an existing application to Kong AI Gateway
Migrating to Kong AI Gateway is incredibly easy, and it supports all existing GenAI applications built with both LLM SDKs or frameworks like LangChain. All users need to do is update one line of code to point to the AI Gateway.
*With one line of code, you can get access to the bountiful capabilities that Kong AI Gateway has to offer, including all the new capabilities in the 3.8 release.*
Of course, all the new capabilities announced in this new release are in addition to the many popular AI Gateway features including out-of-the-box AI analytics and cost metrics, prompt templates and security management, credential store and multi-LLM routing, prompt decoration, and much more.
If you're a developer and don’t want to deploy your own infrastructure, we've also repackaged a subset of the AI Gateway features (like semantic caching and prompt guardrails) into a ready-to-use product for developers called Insomnia AI Runner. You can [get started for free](https://ai.insomnia.rest/)get started for free today.
*With Insomnia’s AI Runner, you can semantically accelerate every GenAI request in one click, and it's powered by Konnect and AI Gateway under the hood.*
You'll be able to accelerate your GenAI Requests to multiple LLMs using different semantic caching thresholds that have been pre-configured for you, and you'll also be able to set up ready-to-use guardrails for all AI traffic running through the AI Runner.
*With the AI Runner, acceleration and security for GenAI traffic are very easy to configure.*
Everything that the Insomnia AI Runner can do, you can also run on Konnect using hybrid or Dedicated Cloud Gateways and — by doing so — you'll always be in full control of your GenAI traffic within your own organization. And by running it yourself, you also get access to all the other AI plugins that are currently not available in AI Runner.
We’re pleased to announce the new LLM Usage reporting feature in Advanced Analytics, which aims to help organizations better manage their large language model (LLM) usage. This feature offers insights into token consumption, costs, and latency, allo
Christian Heidenreich
# Consistently Hallucination-Proof Your LLMs with Automated RAG
AI is quickly transforming the way businesses operate, turning what was once futuristic into everyday reality. However, we're still in the early innings of AI, and there are still several key limitations with AI that organizations should remain awa
Adam Jiroun
# Move More Agentic Workloads to Production with AI Gateway 3.13
MCP ACLs, Claude Code Support, and New Guardrails
New providers, smarter routing, stronger guardrails — because AI infrastructure should be as robust as APIs We know that successful AI connectivity programs often start with an intense focus on how
Greg Peranich
# Kong AI Gateway 3.11: Reduce Token Spend, Unlock Multimodal Innovation
New Multimodal Capabilities, New AI Prompt Compression, Integration with AWS Bedrock Guardrails, and More Today, I'm excited to announce one of our largest Kong AI Gateway releases (3.11), which ships with several new features critical in building m
Marco Palladino
# Kong Konnect: Introducing HashiCorp Vault Support for LLMs
If you're a builder, you likely keep sending your LLM credentials on every request from your agents and applications. But if you operate in an enterprise environment, you'll want to store your credentials in a secure third-party like HashiCorp Vault
Marco Palladino
# Kong AI Manager: Govern & Observe Agentic Traffic to Thousands of LLMs
Today, we're excited to announce the general availability of AI Manager in Kong Konnect, the platform to manage all of your API, AI, and event connectivity across all modern digital applications and AI agents. Kong already provides the fastest and m
Marco Palladino
# LLM Cost Management: How to Implement AI Showback and Chargeback
Bring Financial Accountability to Enterprise LLM Usage with Konnect Metering and Billing
Showback and chargeback are not the same thing. Most organizations conflate these two concepts, and that conflation delays action. Understanding the LLM showb
Alex Drag
# Introducing LLM Analytics in Kong Konnect for GenAI Traffic
We’re pleased to announce the new LLM Usage reporting feature in Advanced Analytics, which aims to help organizations better manage their large language model (LLM) usage. This feature offers insights into token consumption, costs, and latency, allo
Christian Heidenreich
# Consistently Hallucination-Proof Your LLMs with Automated RAG
AI is quickly transforming the way businesses operate, turning what was once futuristic into everyday reality. However, we're still in the early innings of AI, and there are still several key limitations with AI that organizations should remain awa
Adam Jiroun
# Move More Agentic Workloads to Production with AI Gateway 3.13
MCP ACLs, Claude Code Support, and New Guardrails
New providers, smarter routing, stronger guardrails — because AI infrastructure should be as robust as APIs We know that successful AI connectivity programs often start with an intense focus on how
Greg Peranich
# Kong AI Gateway 3.11: Reduce Token Spend, Unlock Multimodal Innovation
New Multimodal Capabilities, New AI Prompt Compression, Integration with AWS Bedrock Guardrails, and More Today, I'm excited to announce one of our largest Kong AI Gateway releases (3.11), which ships with several new features critical in building m
Marco Palladino
# Kong Konnect: Introducing HashiCorp Vault Support for LLMs
If you're a builder, you likely keep sending your LLM credentials on every request from your agents and applications. But if you operate in an enterprise environment, you'll want to store your credentials in a secure third-party like HashiCorp Vault
Marco Palladino
# Kong AI Manager: Govern & Observe Agentic Traffic to Thousands of LLMs
Today, we're excited to announce the general availability of AI Manager in Kong Konnect, the platform to manage all of your API, AI, and event connectivity across all modern digital applications and AI agents. Kong already provides the fastest and m
Marco Palladino
# LLM Cost Management: How to Implement AI Showback and Chargeback
Bring Financial Accountability to Enterprise LLM Usage with Konnect Metering and Billing
Showback and chargeback are not the same thing. Most organizations conflate these two concepts, and that conflation delays action. Understanding the LLM showb
Alex Drag
# Introducing LLM Analytics in Kong Konnect for GenAI Traffic
We’re pleased to announce the new LLM Usage reporting feature in Advanced Analytics, which aims to help organizations better manage their large language model (LLM) usage. This feature offers insights into token consumption, costs, and latency, allo
Christian Heidenreich
# Consistently Hallucination-Proof Your LLMs with Automated RAG
AI is quickly transforming the way businesses operate, turning what was once futuristic into everyday reality. However, we're still in the early innings of AI, and there are still several key limitations with AI that organizations should remain awa
Adam Jiroun
# Move More Agentic Workloads to Production with AI Gateway 3.13
MCP ACLs, Claude Code Support, and New Guardrails
New providers, smarter routing, stronger guardrails — because AI infrastructure should be as robust as APIs We know that successful AI connectivity programs often start with an intense focus on how
Greg Peranich
# Kong AI Gateway 3.11: Reduce Token Spend, Unlock Multimodal Innovation
New Multimodal Capabilities, New AI Prompt Compression, Integration with AWS Bedrock Guardrails, and More Today, I'm excited to announce one of our largest Kong AI Gateway releases (3.11), which ships with several new features critical in building m
Marco Palladino
# Kong Konnect: Introducing HashiCorp Vault Support for LLMs
If you're a builder, you likely keep sending your LLM credentials on every request from your agents and applications. But if you operate in an enterprise environment, you'll want to store your credentials in a secure third-party like HashiCorp Vault
Marco Palladino
# Kong AI Manager: Govern & Observe Agentic Traffic to Thousands of LLMs
Today, we're excited to announce the general availability of AI Manager in Kong Konnect, the platform to manage all of your API, AI, and event connectivity across all modern digital applications and AI agents. Kong already provides the fastest and m
Marco Palladino
# LLM Cost Management: How to Implement AI Showback and Chargeback
Bring Financial Accountability to Enterprise LLM Usage with Konnect Metering and Billing
Showback and chargeback are not the same thing. Most organizations conflate these two concepts, and that conflation delays action. Understanding the LLM showb
Alex Drag
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.