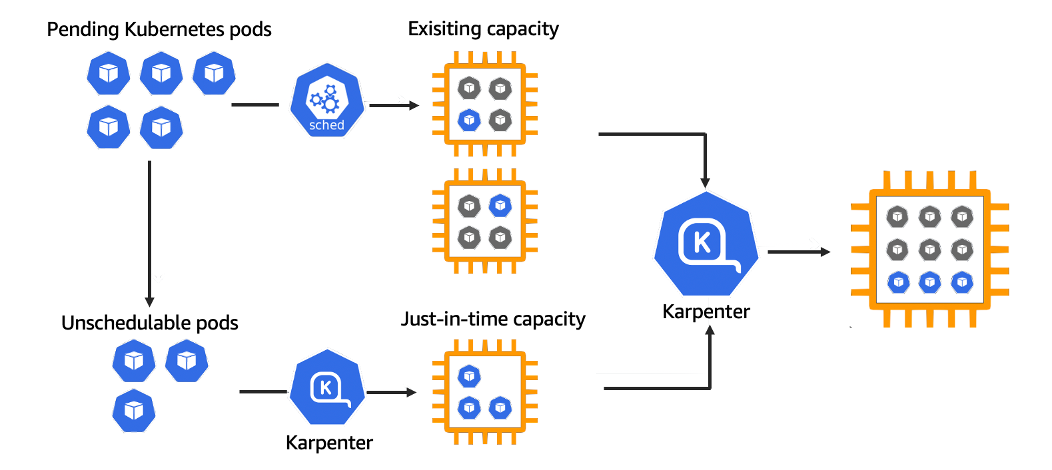
# Kong Konnect Data Plane Node Autoscaling with Karpenter on Amazon EKS 1.29
Claudio Acquaviva
Principal Architect, Kong
In this post, we're going to explore Karpenter, the ultimate solution for Node Autoscaling. Karpenter provides a cost-effective capability to implement your Kong Konnect Data Plane layer using the best EC2 Instances Types options available for your Kubernetes Nodes.
We can summarize [Karpenter](https://karpenter.sh/)Karpenter as a Kubernetes cluster autoscaler that right-sizes compute resources based on the specific requirements of Cluster workloads. In other words, Karpenter evaluates the aggregate resource requirements of the pending pods and chooses the optimal instance type to run them. That improves the efficiency and cost of running workloads.
Now, we are ready to install Karpenter. By default, Karpenter requests 2 replicas to run itself. For our simple exploration environment, we are changing that to 1.
EC2NodeClass: specific AWS settings for EC2 Instances. Each NodePool must reference an EC2NodeClass using `spec.template.spec.nodeClassRef` setting.
Let's create both NodePool and EC2NodeClass based on the basic instructions provided via the Karpenter website.
### NodePool
Note we've added the `nodegroupname=kong` label to it. This is important to make sure the new Nodes will be available for the Konnect Data Plane Deployment. Moreover, the `nodeClassRef` setting refers to the default NodeClass we create next. Please, check the Karpenter documentation to learn more about [NodePool configuration](https://karpenter.sh/docs/concepts/nodepools/)NodePool configuration.
The [EC2NodeClass](https://karpenter.sh/docs/concepts/nodeclasses/)EC2NodeClass declaration includes specific AWS settings to be used when creating a new Node such as AMI Family, Instance Profile, Subnets, Security Groups, IAM Role, etc. Note we are grating the `KarpenterNodeRole-kong35-eks129-autoscaling` Role, created by the CloudFormation template, to the new Nodes.
As we have Karpenter installed and configured, let's move on and install the Konnect Data Plane. Make sure you use the same declaration we used before and set the same CPU and memory (cpu=1500m, memory=3Gi) resources to it.
Since we are going to use HPA and Karpenter together, install the Metrics Server on your Cluster along with the HPA policy allowing 20 replicas to be created.
Finally, create the new Node for the Upstream and Load Generator as well as deploy the Upstream Service using the same declaration.
Start the same Fortio 60-minute-long load test with 5000 qps.
After some minutes we'll see both HPA and Karpenter in action. Here's one of the HPA results I got:
% kubectl get hpa -n kong
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
kong-hpa Deployment/kong-kong 37%/75% 12015 21h
You can see it in action if you leave the test load running a little longer. We'll see that Karpenter has consolidated the multiple Nodes into a single one:
% kubectl get hpa -n kong
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
kong-hpa Deployment/kong-kong 32%/75% 12015 21h
% kubectl get nodes -o json | jq -r '.items[].metadata.labels | select(.nodegroupname=="kong") | ."node.kubernetes.io/instance-type"'
t3.large
c5a.2xlarge
% kubectl top node --selector='karpenter.sh/nodepool=default'
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
ip-192-168-75-198.us-west-1.compute.internal 2056m 25% 4241Mi 28%
From the API consumption perspective, here are the results I got. As you can see the Data Plane layer with all its replicas was able to honor the QPS requested with expected latency time.
-
The P99 latency: for example, `# target 99% 0.0484703`
-
The number of requests sent along with the QPS: `All done 18000000 calls (plus 800 warmup) 98.065 ms avg, 4999.8 qps`
As a fundamental principle of Elasticity, if we stop the load test, deleting the Fortio Pod, we should see HPA and Karpenter reducing the resources allocated to the Data Plane.
kubectl delete pod fortio
% kubectl get hpa -n kong
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
kong-hpa Deployment/kong-kong 1%/75% 1201 22h
% kubectl get nodes -o json | jq -r '.items[].metadata.labels | select(.nodegroupname=="kong") | ."node.kubernetes.io/instance-type"'
t3.large
## Conclusion
Kong takes performance and elasticity very seriously. When we come to a Kubernetes deployment, it's important to support all Elasticity technologies available to provide our customers flexibility and a lightweight and performant API gateway infrastructure.
This blog post series described Kong Konnect Data Plane deployment to take advantage of the main Kubernetes-based Autoscaling technologies:
In the rapidly evolving landscape of API management, understanding the raw performance and reliability of your API gateway is not just an expectation — it's a necessity. At Kong, we're dedicated to ensuring our users have access to concrete, action
Kong
# Kong Konnect DP Node Autoscaling with Cluster Autoscaler on AWS EKS 1.29
After getting our Konnect Data Planes vertically and horizontally scaled, with VPA and HPA , it's time to explore the Kubernete Node Autoscaler options. In this post, we start with the Cluster Autoscaler mechanism. (Part 4 in this series is dedic
Claudio Acquaviva
# Kong Konnect Data Plane Elasticity on Amazon EKS 1.29: Pod Autoscaling with VPA
In this series of posts, we will look closely at how Kong Konnect Data Planes can take advantage of Autoscalers running on Amazon Elastic Kubernetes Services (EKS) 1.29 to support the throughput the demands API consumers impose on it at the lowest c
Claudio Acquaviva
# Kafka in a DMZ: Protecting AWS MSK with Kong Event Gateway
The MSK exposure problem
Amazon MSK brokers live in private subnets by default. That's the right default. Kafka's protocol wasn't designed for untrusted networks — it has no concept of rate limiting, no built-in field-level encryption, and its ACL
Hugo Guerrero
# How to Test Gateway APIs Directly from Kong Konnect with Insomnia
What You'll Build
To explore the new integration, I'll build a realistic API platform workflow using Konnect, Kong Gateway, and Insomnia.
By the end of this tutorial, I'll have:
A Konnect Control Plane (KongAir Dev)
A local Kong Gateway Data Pl
Juhi Singh
# Migrating Your Collections and Requests from Postman to Insomnia
Local-first: your data stays with you: Insomnia stores everything on your machine by default. No forced cloud sync, no account needed just to send a request. This is helpful if privacy or working in a regulated environment is a priority for you Fre
Juhi Singh
# Why Your API Gateway Should Be Your Testing Environment
You invested in Kong Konnect. You centralized your API governance, locked down your routing, enforced your security policies, and gave your organization a single source of truth for every API in your estate. That work is done, and it is working. So
Haley Giuliano
# Kong Gateway Performance Benchmarks and Open Source Test Suites
In the rapidly evolving landscape of API management, understanding the raw performance and reliability of your API gateway is not just an expectation — it's a necessity. At Kong, we're dedicated to ensuring our users have access to concrete, action
Kong
# Kong Konnect DP Node Autoscaling with Cluster Autoscaler on AWS EKS 1.29
After getting our Konnect Data Planes vertically and horizontally scaled, with VPA and HPA , it's time to explore the Kubernete Node Autoscaler options. In this post, we start with the Cluster Autoscaler mechanism. (Part 4 in this series is dedic
Claudio Acquaviva
# Kong Konnect Data Plane Elasticity on Amazon EKS 1.29: Pod Autoscaling with VPA
In this series of posts, we will look closely at how Kong Konnect Data Planes can take advantage of Autoscalers running on Amazon Elastic Kubernetes Services (EKS) 1.29 to support the throughput the demands API consumers impose on it at the lowest c
Claudio Acquaviva
# Kafka in a DMZ: Protecting AWS MSK with Kong Event Gateway
The MSK exposure problem
Amazon MSK brokers live in private subnets by default. That's the right default. Kafka's protocol wasn't designed for untrusted networks — it has no concept of rate limiting, no built-in field-level encryption, and its ACL
Hugo Guerrero
# How to Test Gateway APIs Directly from Kong Konnect with Insomnia
What You'll Build
To explore the new integration, I'll build a realistic API platform workflow using Konnect, Kong Gateway, and Insomnia.
By the end of this tutorial, I'll have:
A Konnect Control Plane (KongAir Dev)
A local Kong Gateway Data Pl
Juhi Singh
# Migrating Your Collections and Requests from Postman to Insomnia
Local-first: your data stays with you: Insomnia stores everything on your machine by default. No forced cloud sync, no account needed just to send a request. This is helpful if privacy or working in a regulated environment is a priority for you Fre
Juhi Singh
# Why Your API Gateway Should Be Your Testing Environment
You invested in Kong Konnect. You centralized your API governance, locked down your routing, enforced your security policies, and gave your organization a single source of truth for every API in your estate. That work is done, and it is working. So
Haley Giuliano
# Kong Gateway Performance Benchmarks and Open Source Test Suites
In the rapidly evolving landscape of API management, understanding the raw performance and reliability of your API gateway is not just an expectation — it's a necessity. At Kong, we're dedicated to ensuring our users have access to concrete, action
Kong
# Kong Konnect DP Node Autoscaling with Cluster Autoscaler on AWS EKS 1.29
After getting our Konnect Data Planes vertically and horizontally scaled, with VPA and HPA , it's time to explore the Kubernete Node Autoscaler options. In this post, we start with the Cluster Autoscaler mechanism. (Part 4 in this series is dedic
Claudio Acquaviva
# Kong Konnect Data Plane Elasticity on Amazon EKS 1.29: Pod Autoscaling with VPA
In this series of posts, we will look closely at how Kong Konnect Data Planes can take advantage of Autoscalers running on Amazon Elastic Kubernetes Services (EKS) 1.29 to support the throughput the demands API consumers impose on it at the lowest c
Claudio Acquaviva
# Kafka in a DMZ: Protecting AWS MSK with Kong Event Gateway
The MSK exposure problem
Amazon MSK brokers live in private subnets by default. That's the right default. Kafka's protocol wasn't designed for untrusted networks — it has no concept of rate limiting, no built-in field-level encryption, and its ACL
Hugo Guerrero
# How to Test Gateway APIs Directly from Kong Konnect with Insomnia
What You'll Build
To explore the new integration, I'll build a realistic API platform workflow using Konnect, Kong Gateway, and Insomnia.
By the end of this tutorial, I'll have:
A Konnect Control Plane (KongAir Dev)
A local Kong Gateway Data Pl
Juhi Singh
# Migrating Your Collections and Requests from Postman to Insomnia
Local-first: your data stays with you: Insomnia stores everything on your machine by default. No forced cloud sync, no account needed just to send a request. This is helpful if privacy or working in a regulated environment is a priority for you Fre
Juhi Singh
# Why Your API Gateway Should Be Your Testing Environment
You invested in Kong Konnect. You centralized your API governance, locked down your routing, enforced your security policies, and gave your organization a single source of truth for every API in your estate. That work is done, and it is working. So
Haley Giuliano
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.