# Built-in Health Checks for High Availability Microservices
Hisham Muhammad
Software Engineer & Product Manager (WebAssembly), Kong
Developers are turning to [microservices](https://konghq.com/blog/learning-center/what-are-microservices)microservices in greater numbers to help break through the inflexibility of old monolithic applications. Microservices offer many benefits, including separation of concerns, team autonomy, fault tolerance, and scaling across multiple regions for high availability.
However, microservices also present challenges, including more infrastructure complexity to manage. You have more services to monitor for availability and performance. It's also a challenge to balance load and route around failures to maintain high availability. If your services are stateful, you need to maintain persistent connections between clients and instances. Most API developers would prefer to have a system manage these infrastructure complexities so they can focus on the business logic.
In this article, we'll describe how algorithms for load balancing help you deliver highly available services. Then, we'll also show an example of how Kong makes it easier to deliver high availability with built-in health checks and circuit breakers. Kong is the world’s most popular open source API management platform for microservices. With Kong, you get more control and richer health checks than a typical load balancer.
## Intro to load balancing
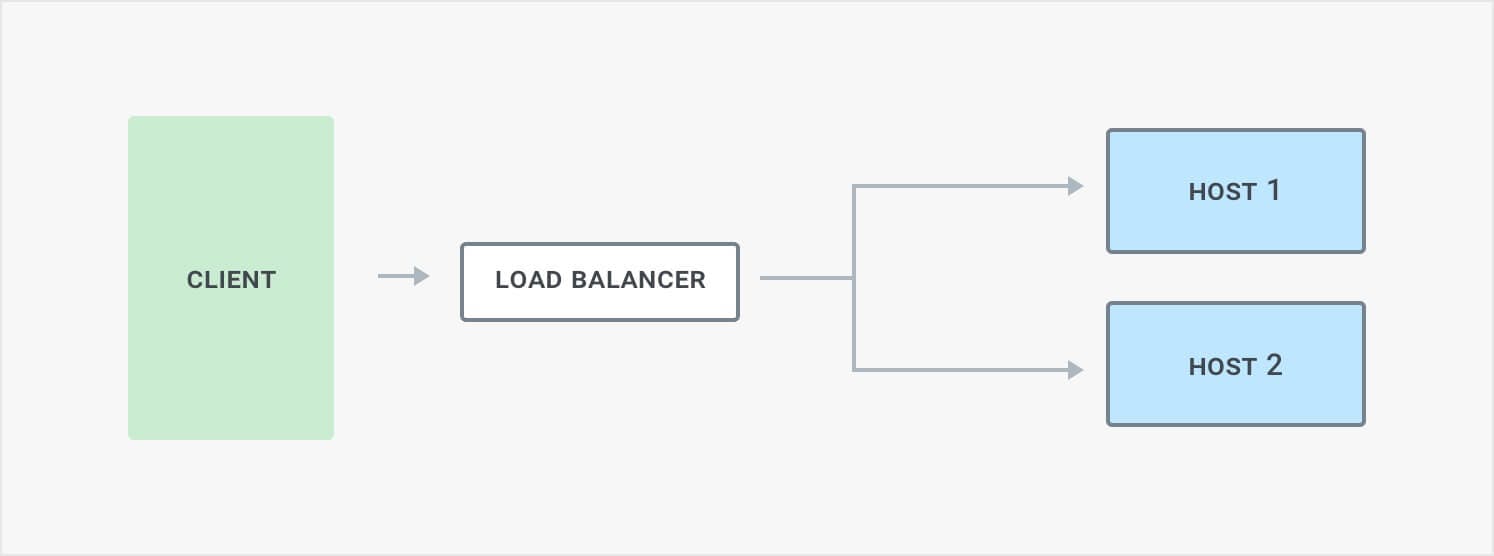
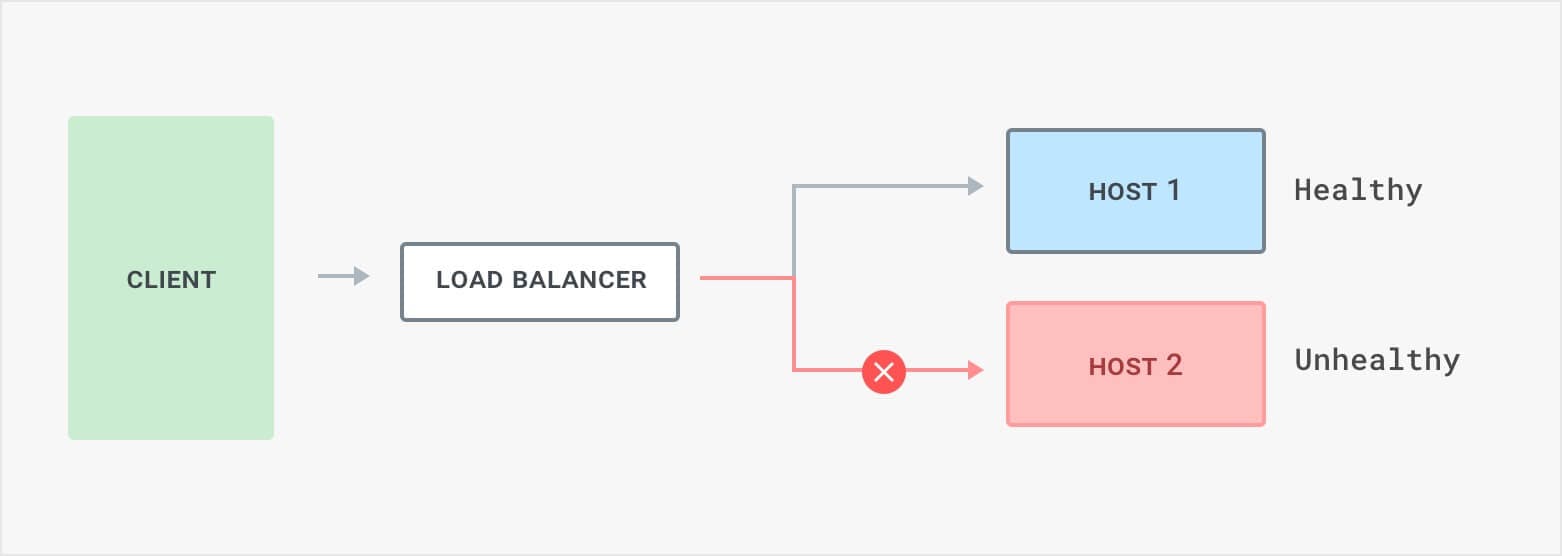
Load balancing is the practice of distributing client request load across multiple application instances for improved performance. Load balancing distributes requests among healthy hosts so no single host gets overloaded.
A typical load balancing architecture showing that clients make requests to a load balancer, which then passes (or proxies) requests to the upstream hosts. Clients can be a real person or a service calling another service, and they can be external or internal to your company.
The primary advantages of load balancing are higher availability, highly performing application services, and improved customer experience. Load-balancing also lets us scale applications up and down independently and provides an ability to self-heal without app down time. It also lets us significantly improve speed to market by enabling a rolling or "canary" deployment process, so we can see how deployments are performing on a small set of hosts before rolling out across the entire cluster.
### Important load balancer types
There are several algorithms or processes by which load can be balanced across servers: DNS, round robin, and ring balancer.
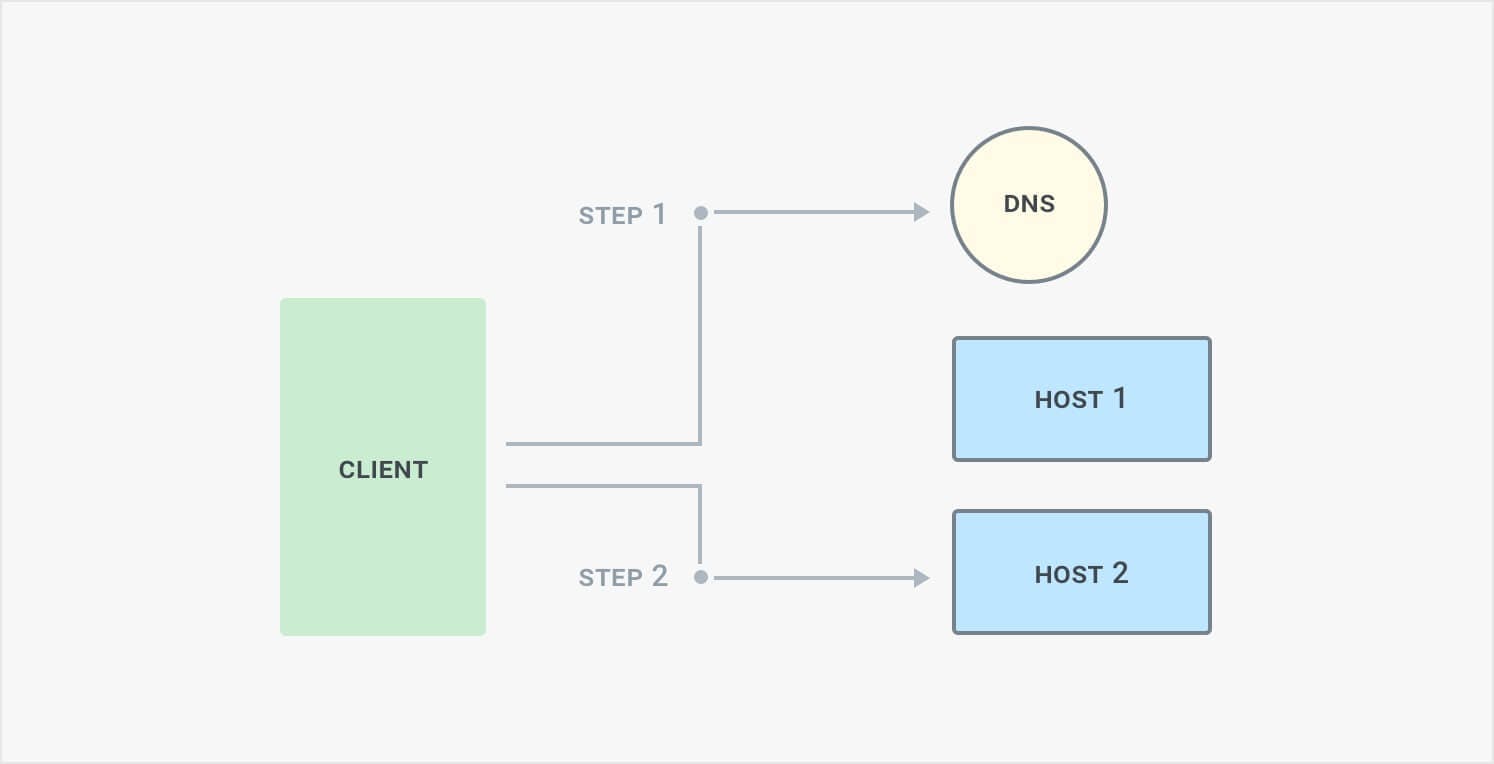
#### Domain Name Server (DNS) load balancing
The DNS load balancing process starts by configuring a domain in the DNS server with multiple-host IP addresses such that clients requests to the domain are distributed across multiple hosts.
In most Linux distributions, DNS by default sends the list of host IP addresses in a different order each time it responds to a new application client. As a result, different clients direct their requests to different servers, effectively distributing the load across the server group.
The disadvantage is that clients often cache the IP address for a period of time, known as time to live (TTL). If the TTL is minutes or hours, it can be impractical to remove unhealthy hosts or to rebalance load. If it's set to seconds, you can recover faster but it also creates extra DNS traffic and latency. It's better to use this approach with hosts that are highly performant and can recover quickly, or on internal networks where you can closely control DNS.
####
#### Round robin
In the round robin model, clients send requests to a centralized server which acts as a proxy to the upstream hosts. The simplest algorithm is called "round robin." It distributes load to hosts evenly and in order. The advantage over DNS is that your team can very quickly add hosts during times of increased load, and remove hosts that are unhealthy or are not needed. The disadvantage is that each client request can get distributed to a different host, so it's not a good algorithm when you need consistent sessions.
####
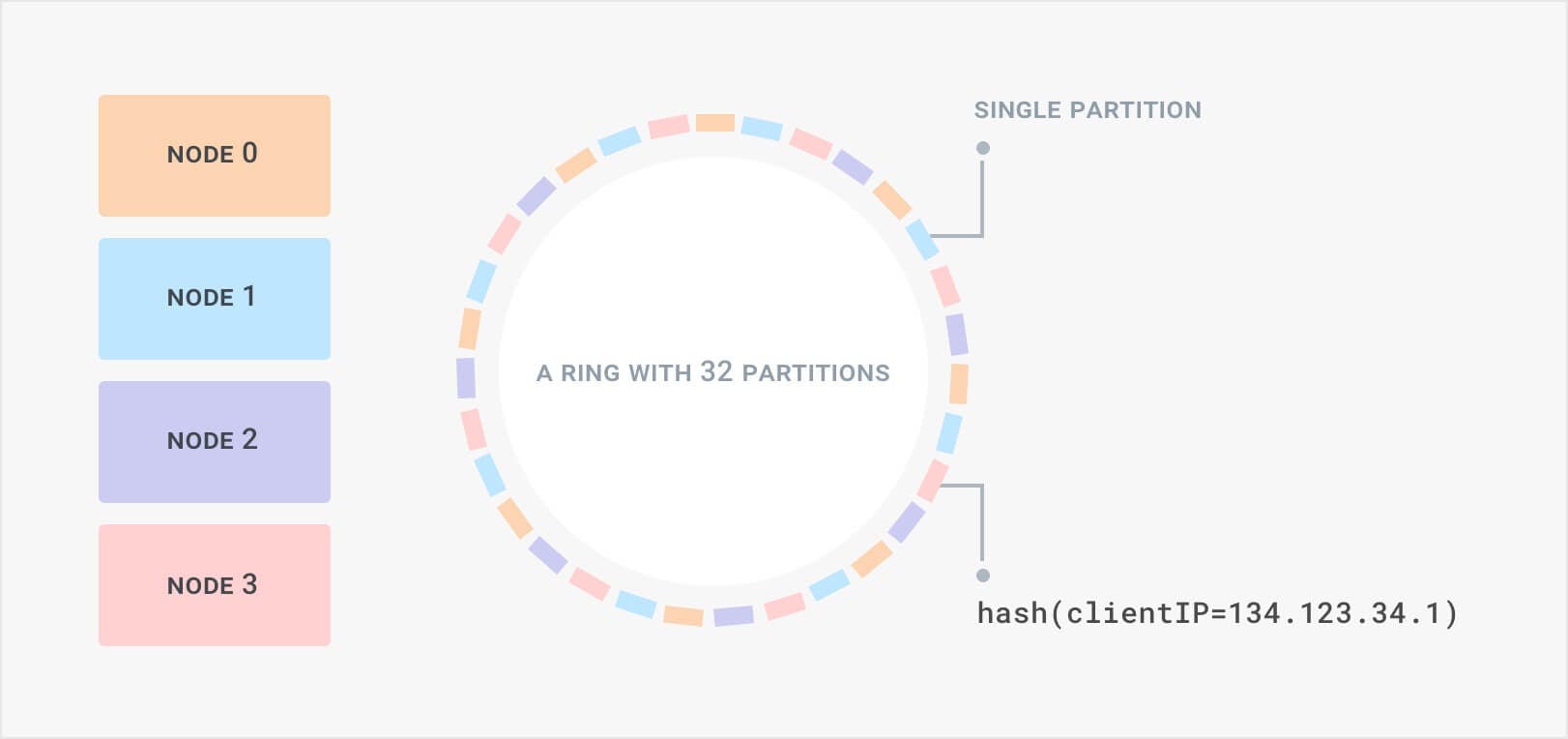
#### Ring balancer
A ring balancer allows you to maintain consistent or "sticky" sessions between clients and hosts. This can be important for web socket connections or where the server maintains a session state.
It works similarly to the round robin model because the load balancer acts as a proxy to the upstream hosts. However, it uses a consistent hash that maps the client to the upstream host. The protocol must use a client key in the hash, such as their IP address. When a host is removed, it affects only 1/N requests, where N is the number of hosts. Your system may be able to recover the session by transferring data to the new hosts, or the client may restart the session.
In the graphic below, we have 4 nodes that balance load across 32 partitions. Each client key is hashed and is mapped to one of the partitions. When a single node goes down, a quarter of partitions need to be reassigned to healthy nodes. The mapping from client to partition stays consistent even when nodes are added or removed.
## Health checks and circuit breakers improve availability
Microservice health checks can help us detect failed hosts so the load balancer can stop requests to them. A host can fail for many reasons, such as simply being overloaded, the server process may have stopped running, it might have a failed deployment, or broken code to list a few reasons. This can result in connection timeouts or HTTP error codes. Whatever the reason, we want to route traffic around it so that customers are not affected.
### Active health checks
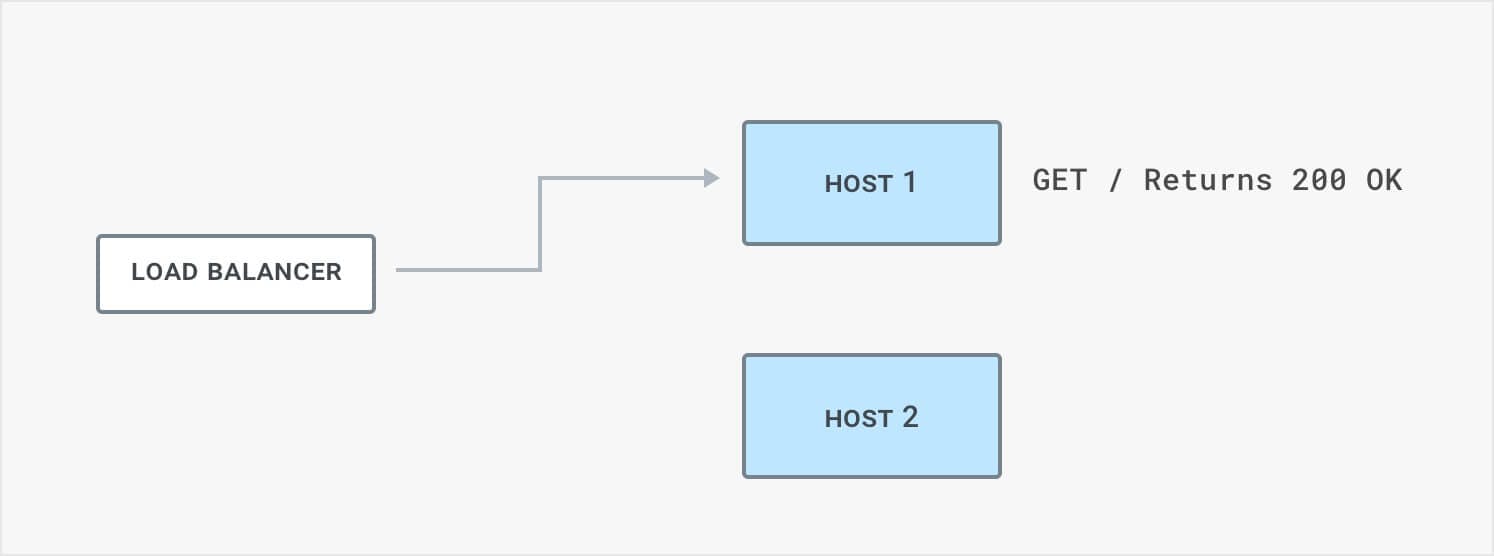
In active health checks, the load balancer periodically "probes" upstream servers by sending a special health check request. If the load balancer fails to get a response back from the upstream server, or if the response is not as expected, it disables traffic to the server. For example, it's common to require the response from the server includes the 200 OK HTTP code. If the server times out or responds with a 500 Server Error, then it is not healthy.
The disadvantage is that active health checks only use the specific rule they are configured for, so they may not replicate the full set of user behavior. For example, if your probe checks only the index page, it could be missing errors on a purchase page. These probes also create extra traffic and load on your hosts as well as your load balancer. In order to quickly identify unhealthy hosts, you need to increase the frequency of health checks which creates more load.
### Passive health checks
In passive health checks, the load balancer monitors real requests as they pass through. If the number of failed requests exceeds a threshold, it marks the host as unhealthy.
The advantage of passive health checks are that they observe real requests, which better reflects the breadth and variety of user behavior. They also don't generate additional traffic on the hosts or load balancer. The disadvantages are that users are affected before the problem is recognized, and you still need active probes to determine if hosts with unknown states are healthy.
We recommend you get the best of both worlds by using both passive and active health checks. This minimizes extra load on your servers while allowing you to quickly respond to unexpected behavior.
### Circuit breakers
When you know that a given host is unhealthy, its best to "break the circuit" so that traffic flows to healthy hosts instead. This provides a better experience for end-users because they will encounter fewer errors and timeouts. It's also better for your host because diverting traffic will prevent it from being overloaded, and give it a chance to recover. It may have too many requests to handle, the process or container may need to be restarted, or your team may need to investigate.
Circuit breakers are essential to enable automatic fault tolerance in production systems. There are also critical if you are doing blue-green or canary deployments. These allow you to test a new build in production on a fraction of your hosts. If the service becomes unhealthy, it can be removed automatically. Your team can then investigate the failed deployment.
Kong allows load balancing using the DNS method, and it's ring-balancer offers both round robin and hash-based balancing. It also provides both passive and active health checks.
A unique advantage of Kong is that both active and passive health checks are offered for free in the Community Edition (CE). Nginx offers passive health checks in the community edition, but active health checks are included only in the paid edition, Nginx Plus. Amazon Elastic Load Balancers (ELB) don't offer passive checks. Also, depending on your use, it may cost more than running your own instance of Kong. [Kubernetes](https://konghq.com/solutions/kubernetes-ingress)Kubernetes liveness probes offer only active checks.
The [Kong Enterprise](https://konghq.com/products/kong-enterprise)Kong Enterprise edition also offers dedicated support, monitoring, and easier management. The Admin GUI makes it easy to add and remove services, plugins, and more. Its analytics feature can take the place of more expensive monitoring systems.
## See it in action
Let's do a demo to see how easy it is to configure health checks in Kong. Since they are familiar to many developers, we'll use two Nginx servers as our upstream hosts. Another container running Kong will perform health checks and load balancing. When one of the hosts goes down, Kong will recognize that it is unhealthy and route traffic to the healthy container.
In this example, we're going to use Docker to set up our test environment. This will allow you to follow along on your own developer desktop. If you are new to Docker, a great way to learn are the [Katacoda tutorials](https://www.katacoda.com/courses/docker)Katacoda tutorials. You don't need to install anything and can learn the basics in about an hour.
First let’s create our healthy container. It will respond with "Hello World!" We'll set this up using a static file and mount it in our container's html directory.
Verify Kong is running on the port 8001 and gives a 200 ‘OK' response. That means it's working.
$ curl -i localhost:8001/apis
HTTP/1.1200 OK
### Step 3: Configure Kong to use our test hosts
Now we want to connect Kong to our test hosts. The first step is configuring an API in Kong. "API" is just a historic term since Kong can load balance any HTTP traffic, including web server requests. I'm going to call our API "mytest" since it’s easy to remember. I'm also setting the connection timeout to 5 seconds because I'm too impatient to wait the default 60 seconds. If you want to learn more about creating APIs, see [Kong`s documentation](https://getkong.org/docs/latest/getting-started/adding-your-api)Kong`s documentation.
Now we can add targets to the upstream we just created. These will point to the Nginx servers we just created in Step 1. Use the actual IP of your machine, not just the loopback address.
$ curl -i -X POST http://localhost:8001/upstreams/mytest/targets --data 'target=192.168.0.8:9090'$ curl -i -X POST http://localhost:8001/upstreams/mytest/targets --data 'target=192.168.0.8:9091'
Kong should be fully configured now. We can test that it's working correctly by making a GET request to Kong's proxy port, which is 8000 by default. We will pass in a header identifying the host which is tied to our API. We should get back a response from our Nginx server saying "Hello"!
You'll notice that Kong is not returning a 500 error, no matter how many times you call it. So what happened to host2? You can check the kong logs to see the status of the health check.
Kong is automatically detecting the failed host by incrementing its unhealthy counter. When it reaches the threshold of 2, it breaks the circuit and routes requests to the healthy host. Next, let's revert the Nginx config back so it returns a 200 OK code. We should see that Kong recognized it as healthy and it now returns the default Nginx page. You might need to run it a few times to see host2 since Kong doesn't switch every other request.
Kong is a scalable, fast, and distributed API gateway layer. Kong's load balancing and health check capabilities can make your services highly available, redundant, and fault-tolerant. These algorithms can help avoid imbalance among servers, improve system utilization, and increase system throughput. To learn more about health checks in Kong, see [our recorded webinar](https://register.gotowebinar.com/register/1720163240257736706)our recorded webinar with a live demonstration of health checks in action. It also includes a presentation on these features and live Q&A from the audience.
We're seeing a massive shift in how companies build their software. More and more, companies are building—or are rapidly transitioning—their applications to a microservice architecture. The monolithic application is giving way to the rise of micro
Alvin Lee
# Observability For Your Microservices Using Kong and Kubernetes
Read the latest version: APM With Prometheus and Grafana on Kubernetes Ingress Archived post below. In the modern SaaS world, observability is key to running software reliability, managing risks and deriving business value out of the code that you'
Harry Bagdi
# Beyond Static Routing: Modernizing API Logic with Conditional Policy Execution
Imagine you have a single Service, order-api . You want to apply a strict rate limit to most traffic, but you want to bypass that limit—or apply a different one—if the request contains a specific X-App-Priority: High header. Previously, you had t
Hugo Guerrero
# 5 Best Practices for Securing AI Microservices at Scale in 2026
The Stakes Keep Rising
The security implications are severe. OWASP's 2025 Top 10 for LLM Applications ranks prompt injection as the number one critical vulnerability. Attackers manipulate LLM inputs to override instructions, extract sensitive data,
Kong
# Connecting Kong and Solace: Building Smarter Event-Driven APIs
Running Kong in front of your Solace Broker adds real benefits: Authentication & Access Control – protect your broker from unauthorized publishers. Validation & Transformation – enforce schemas, sanitize data, and map REST calls into event topics.
Hugo Guerrero
# Microservices Monitoring and Distributed Tracing Tools
Monitoring and distributed tracing enable observability of your production system and contribute to the feedback loop for a more efficient and effective development process. Monitoring Microservices Monitoring the health of your production system in
Kong
# Kong Mesh 2.14: Finer Zone Proxy Control and Tighter Security
Kong Mesh 2.14 also introduces improvements to the mesh-scoped zone proxy deployment model. This makes it easier to configure and operate zone proxies for specific meshes, including Helm support for mesh zone proxy configuration. For customers runni
Justin Davies
# 2 Approaches to Microservices Monitoring and Logging
We're seeing a massive shift in how companies build their software. More and more, companies are building—or are rapidly transitioning—their applications to a microservice architecture. The monolithic application is giving way to the rise of micro
Alvin Lee
# Observability For Your Microservices Using Kong and Kubernetes
Read the latest version: APM With Prometheus and Grafana on Kubernetes Ingress Archived post below. In the modern SaaS world, observability is key to running software reliability, managing risks and deriving business value out of the code that you'
Harry Bagdi
# Beyond Static Routing: Modernizing API Logic with Conditional Policy Execution
Imagine you have a single Service, order-api . You want to apply a strict rate limit to most traffic, but you want to bypass that limit—or apply a different one—if the request contains a specific X-App-Priority: High header. Previously, you had t
Hugo Guerrero
# 5 Best Practices for Securing AI Microservices at Scale in 2026
The Stakes Keep Rising
The security implications are severe. OWASP's 2025 Top 10 for LLM Applications ranks prompt injection as the number one critical vulnerability. Attackers manipulate LLM inputs to override instructions, extract sensitive data,
Kong
# Connecting Kong and Solace: Building Smarter Event-Driven APIs
Running Kong in front of your Solace Broker adds real benefits: Authentication & Access Control – protect your broker from unauthorized publishers. Validation & Transformation – enforce schemas, sanitize data, and map REST calls into event topics.
Hugo Guerrero
# Microservices Monitoring and Distributed Tracing Tools
Monitoring and distributed tracing enable observability of your production system and contribute to the feedback loop for a more efficient and effective development process. Monitoring Microservices Monitoring the health of your production system in
Kong
# Kong Mesh 2.14: Finer Zone Proxy Control and Tighter Security
Kong Mesh 2.14 also introduces improvements to the mesh-scoped zone proxy deployment model. This makes it easier to configure and operate zone proxies for specific meshes, including Helm support for mesh zone proxy configuration. For customers runni
Justin Davies
# 2 Approaches to Microservices Monitoring and Logging
We're seeing a massive shift in how companies build their software. More and more, companies are building—or are rapidly transitioning—their applications to a microservice architecture. The monolithic application is giving way to the rise of micro
Alvin Lee
# Observability For Your Microservices Using Kong and Kubernetes
Read the latest version: APM With Prometheus and Grafana on Kubernetes Ingress Archived post below. In the modern SaaS world, observability is key to running software reliability, managing risks and deriving business value out of the code that you'
Harry Bagdi
# Beyond Static Routing: Modernizing API Logic with Conditional Policy Execution
Imagine you have a single Service, order-api . You want to apply a strict rate limit to most traffic, but you want to bypass that limit—or apply a different one—if the request contains a specific X-App-Priority: High header. Previously, you had t
Hugo Guerrero
# 5 Best Practices for Securing AI Microservices at Scale in 2026
The Stakes Keep Rising
The security implications are severe. OWASP's 2025 Top 10 for LLM Applications ranks prompt injection as the number one critical vulnerability. Attackers manipulate LLM inputs to override instructions, extract sensitive data,
Kong
# Connecting Kong and Solace: Building Smarter Event-Driven APIs
Running Kong in front of your Solace Broker adds real benefits: Authentication & Access Control – protect your broker from unauthorized publishers. Validation & Transformation – enforce schemas, sanitize data, and map REST calls into event topics.
Hugo Guerrero
# Microservices Monitoring and Distributed Tracing Tools
Monitoring and distributed tracing enable observability of your production system and contribute to the feedback loop for a more efficient and effective development process. Monitoring Microservices Monitoring the health of your production system in
Kong
# Kong Mesh 2.14: Finer Zone Proxy Control and Tighter Security
Kong Mesh 2.14 also introduces improvements to the mesh-scoped zone proxy deployment model. This makes it easier to configure and operate zone proxies for specific meshes, including Helm support for mesh zone proxy configuration. For customers runni
Justin Davies
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.