# New Storage Engine for Kong Hybrid and DB-less Deployments
Datong Sun
We understand that our customers need to deploy Kong in a variety of environments and with different deployment mode needs. That is why two years ago, in Kong 1.1, we introduced DB-less mode, the ability to run Kong without the need of connecting to a database. We then demonstrated the Hybrid mode deployment of Kong for the first time during the 2019 Kong Summit and released the Hybrid mode officially in Kong 2.0, leveraging DB-less as the foundation to support Control Plane and Data Plane separations.
Since then, we have seen a growing number of the popularity of running Kong DB-less in various production environments. Our very own Kubernetes Ingress Controller (KIC) and Konnect platform also heavily relies on Hybrid/DB-less mode to deliver a centralized management and deployment experience.
Therefore, it only makes sense that we continue to invest heavily in DB-less mode to deliver a better experience for our customers. We have recently developed a new storage engine for DB-less that is based on the popular LMDB (Lightning Memory-Mapped Database) embedded storage engine. This blog post will talk about the "Why", "How" and "What's next" aspects of this change.
## Why
Let's first get the obvious question out of the way: Why are you re-implementing the storage engine for the DB-less mode?
The short answer is that as more users start to use DB-less, we are facing increasing difficulty in scaling the existing DB-less storage engine for larger deployments. The current storage engine is very complex, consumes double the amount of memory to store any configuration, and tends to scale poorly as the number of workers increases.
## How DB-less works today
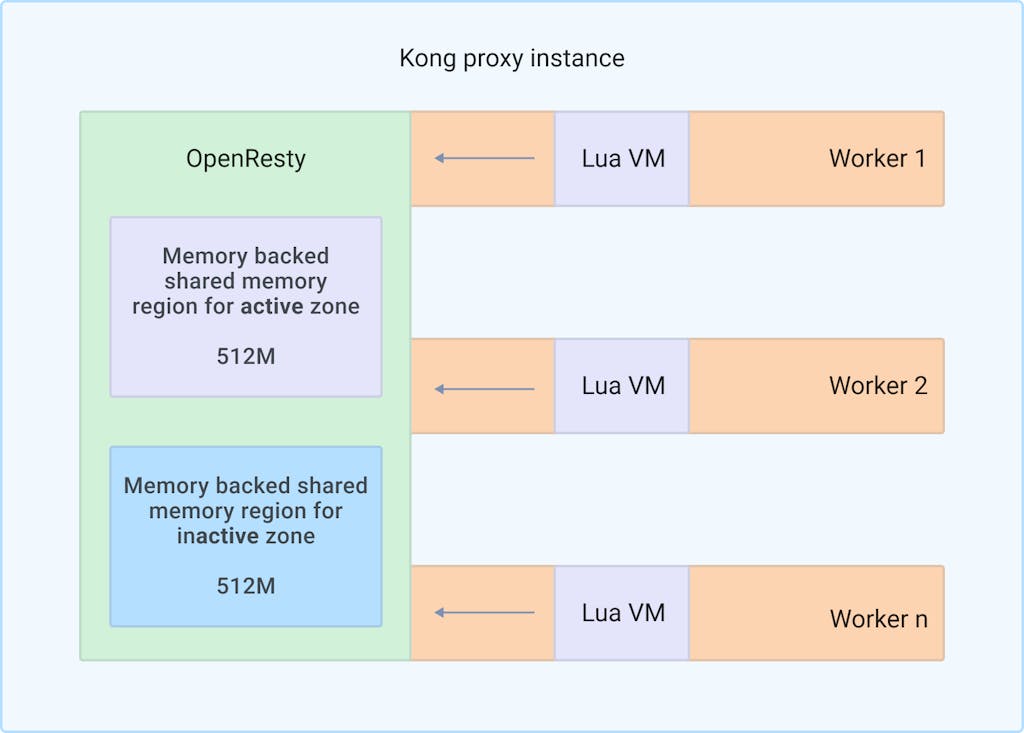
Conceptually, the DB-less mode in Kong is very simple. Instead of storing the configuration for Kong inside a database (such as Postgres) and read from it while proxying, DB-less loads the full config of Kong from a .yaml or .json file and stores the entire config content inside the shared dictionary facility ([shdict](https://github.com/openresty/lua-nginx-module#ngxshareddict)shdict) pre-allocated by Nginx/OpenResty. Later on all workers simply read the pre-loaded config data directly from shdict and treat it as if it is the database backend.
## Where DB-less falls short
Overtime we have identified a few issues with the shdict based DB-less implementation. Here are some of them:
- Reading from shdict is a global blocking event. That means there can only be one Nginx worker reading from a shdict zone at once. This shows up as less than ideal scalability as the number of Kong workers increases.
- Shdict has no native support for transactions. That means we have to maintain two shdict zones – one active and one standby to facilitate atomic switching of database contents. This not only adds a lot of complexity to reload configs, but also means Kong will always require two times the actual amount of config storage even though most of the time the other zone is not being used.
- Due to lack of atomic transactions, partial update of the memory zone is not safe. This affects our ability to incrementally update DB-less configuration for Hybrid mode usage.
- LMDB is fully embeddable and extremely small, which means we can easily statically link it into the Nginx binary that we ship and avoid introducing another dependency for Kong installations. As a matter of fact, the compiled object code of LMDB is typically less than 100KB making it almost unnoticeable inside the Nginx binary we ship.
- LMDB has native multi-process support and can handle concurrent read/write transactions safely. This is critical considering the multi worker scalability model Nginx uses. Most notably, reads in LMDB are never blocked, even in the case of a concurrent write transaction. Making it ideal for mostly read workflow like Kong in proxy mode.
- LMDB is persistent which means we can use it to replace the current JSON based Hybrid mode config cache. This can help with the restart time of Kong and reduce the complexity of the Kong Data Plane (DP) maintaining its own cache for Hybrid mode resilience.
- LMDB has full ACID (atomicity, consistency, isolation, and durability) transaction support. Which allows us to build incremental config updates in the future. This also completely removes the need of having two memory regions simultaneously for config storage as updates can be executed inside a single transaction and temporary dirty pages are automatically reclaimed after the transaction commits. As a result, the memory usage of DB-less with LMDB will be a lot less than the shdict based storage currently.
## Integrating LMDB into Nginx/OpenResty
In order to use LMDB in OpenResty and LuaJIT, the simplest solution would be to compile `liblmdb.so` as a shared library and use LuaJIT FFI to invoke the C API directly. However, there are a few reasons why it may not be the best idea.
- Lua execution can be interrupted for a variety of reasons, such as LuaJIT VM running out of memory or debug hook being triggered. When these exceptions happen, normal execution is interrupted. Since we are manipulating the LMDB C API directly, we may be in the middle of a transaction and have no way to recover properly. Resulting in resource leaks or even worse, locking up other Nginx workers in terms of an unclean write transaction abort.
- LMDB has a lot of custom struct that the fields are platform dependent. Using LuaJIT FFI requires us to precisely replicate all the involved data structures inside Lua, creating opportunities for error or incompatibilities on different architectures.
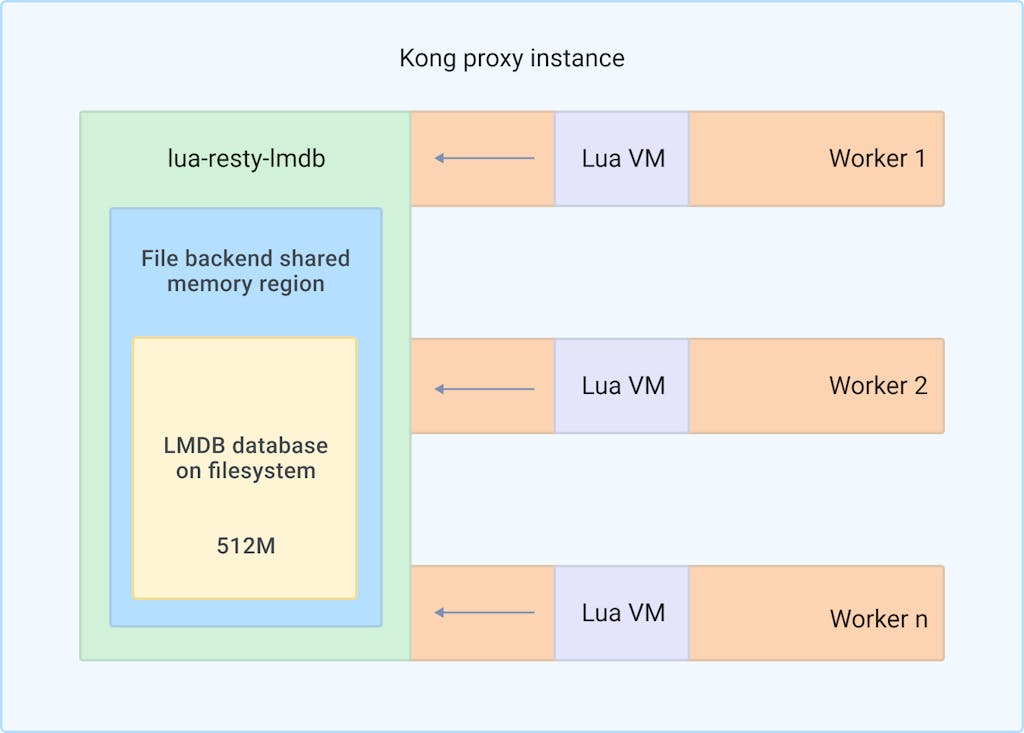
Instead of using LuaJIT FFI to directly interact with the LMDB library functions, we choose to implement and open source a Nginx C module [lua-resty-lmdb](https://github.com/Kong/lua-resty-lmdb)lua-resty-lmdb to properly encapsulate the operations we need to perform on LMDB and expose a safe C API that we can then call using LuaJIT FFI.
lua-resty-lmdb has two portions. One is a Nginx C module that manages the LMDB resource and acts as the abstraction layer for accessing the data stored inside the LMDB database. This module also exposes the safe C API which the Lua library calls through LuaJIT's FFI facility.
The other portion of lua-resty-lmdb is a Lua library that provides the actual API interface for Lua code to call. Under the hood it uses the C API provided by the lua-resty-lmdb C module to safely interact with the LMDB library.
By using this approach, we avoid most of the issues associated with using Lua code to directly manage C resources provided by LMDB. We also ensured good cross-platform compatibility as the ABI for the C API exposed by the lua-resty-lmdb module is relatively stable.
At Kong, every performance based optimization must be backed by measurable performance improvements with tests. In order to prove that LMDB indeed improved the performance of the Kong proxy, we have set up a test environment to generate synthetic loads on the Kong proxy server.
### Test setup
For this benchmark, we set up two [c3.medium.x86](https://metal.equinix.com/product/servers/c3-medium)c3.medium.x86 physical servers on Equinix Metal. These servers both have 1 x AMD EPYC 7402P 24-Core Processor with 48 threads. Therefore, by default Kong will start up 48 workers which creates a lot of potential for shdict mutex contensions.
For the DB-less config, we generated a JSON file with 10000 Routes, 10000 Consumers and assigned key-auth credentials to each one of these consumers. We then enabled the request termination plugin and key-auth plugin on all these 10000 routes. The resulting JSON config file is roughly 5MB in size and contains roughly 50000 objects in total.
For the load generation, we used the `wrk` benchmarking tool with a Lua script that randomizes the Route and Consumers used for each benchmarking request. The wrk tool is running on the separate c3.medium.x86 instance from the one running Kong proxy to minimize the disturbance, and has 20Gbps LAN link to the Kong proxy which ensures network I/O won't be the bottleneck for our tests here.
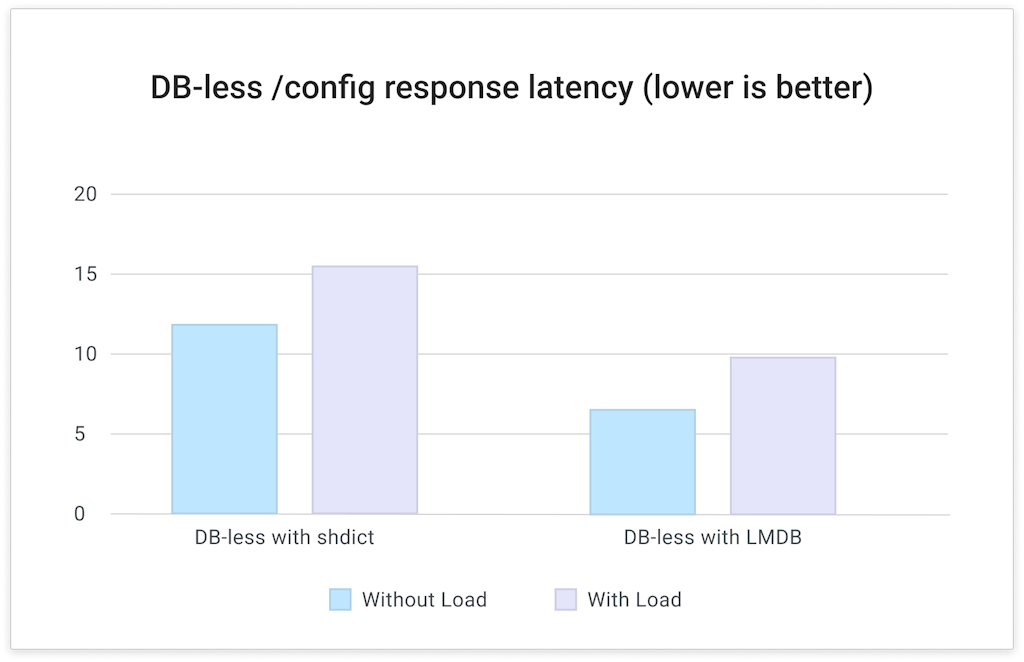
### Test case 1: /config endpoint latency
First test is a simple test that POSTs the JSON file onto the DB-less `/config` endpoint. We are observing the `X-Kong-Admin-Latency` response header which tells us how long it took the DB-less config to finish loading.
**Analysis: **Due to the fact that LMDB is fully transactional, there is no need for complex locking between workers. Which means the Admin API can return sooner and not create any potential for races. This allows for more frequent config reload operations even without any incremental support. Overall the Admin API response latency dropped by 34% – 44% according to our test results.
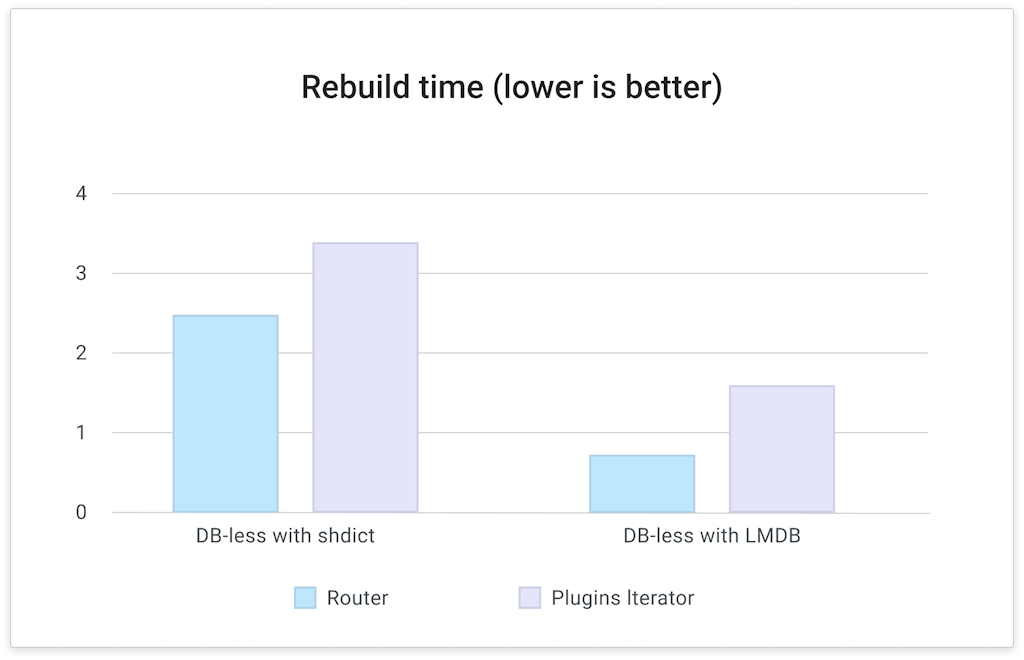
### Test case 2: Router and Plugins Iterator rebuild time
The second test case is a measurement of actual elapsed time for rebuilding the Router and Plugins Iterator after a config push. Due to the nature of Kong's Router and Plugins Iterator design, these operations are CPU intensive and will require each worker to enumerate all available Routes and Plugins objects at the same time. While a worker is rebuilding the Router and Plugins Iterator, proxy requests will be temporarily halted for that worker, creating the potential for dropped RPS and higher latency.
In this test, we collected the actual elapsed time from each worker for their Router and Plugins Iterator rebuild time. Here are the graphs:
**Analysis: **As indicated on the graph, the time it takes for workers to rebuild the Router and Plugins Iterator is 50% – 70% lower with the LMDB storage engine. This will help with the long tail latency of Kong proxy path, especially in environments with a lot of config and high traffic volumes.
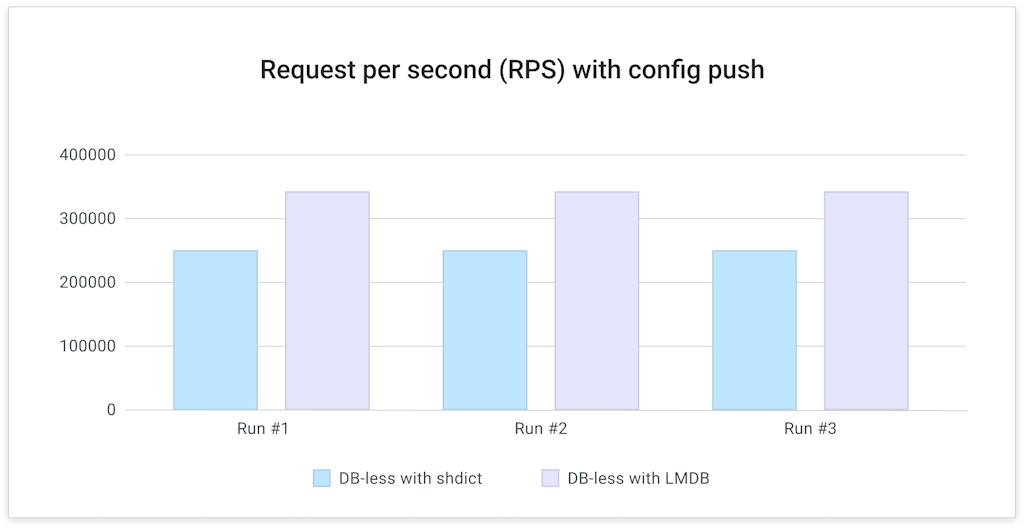
### Test case 3: Request per second (RPS) with background config updates
The final test is a test that measures the impact of config reload to Kong's proxy RPS. To conduct this test, we used `wrk` to generate synthetic load for 20 seconds and while the load is happening, post the above JSON config to the `/config` endpoint.
**Analysis:** It is clear that LMDB's nature of non-blocking reads helps lower the impact to proxy RPS by config pushes. Overall we have observed between 25%-32% of RPS increase with LMDB with the same amount of load and config size.
## Try DB-less with LMDB
We have released a special technical preview build that is based on the latest 2.8 stable release of Kong Gateway. To test it out, you can use the following command to spin up a Docker container with Kong and LMDB support:
Note to ARM64 or Apple Silicon users: change the `kong/kong:lmdb-preview02` tag in the command above to `kong/kong:lmdb-preview02-arm64` instead.
Then you may use the newly started Kong instance just as you would with a normal Kong instance in DB-less mode:
http :8001/config config=@kong.yml
You can also use the above container as a Hybrid mode DP by following the exact same steps as you normally would. In fact, the LMDB technical preview build should be able to work as DP for existing Hybrid mode deployments even if the CP does not contain the LMDB feature.
## What's next
LMDB is the new foundation where new DB-less and Hybrid mode features and Hybrid mode improvements will be based upon. Not only does it allow Kong to run faster with less memory usage, handle very large config with ease, but we will be able to bring more advanced features such as incremental sync for Hybrid mode in the future leveraging LMDB's transactions support. It is truly the foundation that will support our vision of making Hybrid mode the preferred method of Kong deployments.
There will be a blog post with a deeper dive into the technical aspect of LMDB coming out soon. In the post we will be discussing the design of LMDB, shdict and DB-less in more detail. We will also give a more technical analysis of the performance aspect of the change. Please stay tuned!
In the rapidly evolving world of microservices and cloud-native applications , service mesh has emerged as a critical tool for managing complex, distributed systems. As organizations increasingly adopt microservices architectures, they face new c
Kong
# Troubleshooting an Intermittent Failure in CI Tests on ARM64
The Kong Gateway CI was failing intermittently (about once every 100 runs) on the ARM64 platform with a strange error: “attempt to perform arithmetic on local 'i' (a function value)”. The variable i in the context is an integer but at runtime, it w
Zhongwei Yao
# Using Kong Gateway to Adapt SOAP Services to the JSON World
While JSON-based APIs are ubiquitous in the API-centric world of today, many industries adapted internet-based protocols for automated information exchange way before REST and JSON became popular. One attempt to establish a standardized protocol sui
Hans Hübner
# Scaling Kong Deployments with and without Databases
As the world's most popular API Gateway , Kong Gateway is flexible and can be adapted to various environments and deployment configurations. This flexibility means some time should be taken to make good architectural decisions for the use cases i
Ahmed Koshok
# Migration Options for IBM Cloud API Gateway Customers
IBM recently announced the deprecation of its Cloud API Gateway, a service used to create and manage APIs by placing a gateway in front of existing IBM Cloud endpoints. With this move, IBM Cloud Functions and IBM Cloud Foundry are no longer able to
Syed Mahmood
# Optimize Your API Gateway with Chaos Engineering
As engineers and architects, we automatically build resilience into platforms as far as possible. But what about the unknown failures? What about the unknown behavior of your platform? The philosopher, Socrates, once said "You don’t know what you do
Andrew Kew
# How to Deploy an API Gateway Within a CI/CD Pipeline
Continuous integration and continuous deployment—known colloquially as CI/CD—are essential strategies for building modern software applications. The goal of these processes is to foster a culture of continuous updates. CI is the process by which an
Garen Torikian
# A Guide to Service Mesh Adoption and Implementation
In the rapidly evolving world of microservices and cloud-native applications , service mesh has emerged as a critical tool for managing complex, distributed systems. As organizations increasingly adopt microservices architectures, they face new c
Kong
# Troubleshooting an Intermittent Failure in CI Tests on ARM64
The Kong Gateway CI was failing intermittently (about once every 100 runs) on the ARM64 platform with a strange error: “attempt to perform arithmetic on local 'i' (a function value)”. The variable i in the context is an integer but at runtime, it w
Zhongwei Yao
# Using Kong Gateway to Adapt SOAP Services to the JSON World
While JSON-based APIs are ubiquitous in the API-centric world of today, many industries adapted internet-based protocols for automated information exchange way before REST and JSON became popular. One attempt to establish a standardized protocol sui
Hans Hübner
# Scaling Kong Deployments with and without Databases
As the world's most popular API Gateway , Kong Gateway is flexible and can be adapted to various environments and deployment configurations. This flexibility means some time should be taken to make good architectural decisions for the use cases i
Ahmed Koshok
# Migration Options for IBM Cloud API Gateway Customers
IBM recently announced the deprecation of its Cloud API Gateway, a service used to create and manage APIs by placing a gateway in front of existing IBM Cloud endpoints. With this move, IBM Cloud Functions and IBM Cloud Foundry are no longer able to
Syed Mahmood
# Optimize Your API Gateway with Chaos Engineering
As engineers and architects, we automatically build resilience into platforms as far as possible. But what about the unknown failures? What about the unknown behavior of your platform? The philosopher, Socrates, once said "You don’t know what you do
Andrew Kew
# How to Deploy an API Gateway Within a CI/CD Pipeline
Continuous integration and continuous deployment—known colloquially as CI/CD—are essential strategies for building modern software applications. The goal of these processes is to foster a culture of continuous updates. CI is the process by which an
Garen Torikian
# A Guide to Service Mesh Adoption and Implementation
In the rapidly evolving world of microservices and cloud-native applications , service mesh has emerged as a critical tool for managing complex, distributed systems. As organizations increasingly adopt microservices architectures, they face new c
Kong
# Troubleshooting an Intermittent Failure in CI Tests on ARM64
The Kong Gateway CI was failing intermittently (about once every 100 runs) on the ARM64 platform with a strange error: “attempt to perform arithmetic on local 'i' (a function value)”. The variable i in the context is an integer but at runtime, it w
Zhongwei Yao
# Using Kong Gateway to Adapt SOAP Services to the JSON World
While JSON-based APIs are ubiquitous in the API-centric world of today, many industries adapted internet-based protocols for automated information exchange way before REST and JSON became popular. One attempt to establish a standardized protocol sui
Hans Hübner
# Scaling Kong Deployments with and without Databases
As the world's most popular API Gateway , Kong Gateway is flexible and can be adapted to various environments and deployment configurations. This flexibility means some time should be taken to make good architectural decisions for the use cases i
Ahmed Koshok
# Migration Options for IBM Cloud API Gateway Customers
IBM recently announced the deprecation of its Cloud API Gateway, a service used to create and manage APIs by placing a gateway in front of existing IBM Cloud endpoints. With this move, IBM Cloud Functions and IBM Cloud Foundry are no longer able to
Syed Mahmood
# Optimize Your API Gateway with Chaos Engineering
As engineers and architects, we automatically build resilience into platforms as far as possible. But what about the unknown failures? What about the unknown behavior of your platform? The philosopher, Socrates, once said "You don’t know what you do
Andrew Kew
# How to Deploy an API Gateway Within a CI/CD Pipeline
Continuous integration and continuous deployment—known colloquially as CI/CD—are essential strategies for building modern software applications. The goal of these processes is to foster a culture of continuous updates. CI is the process by which an
Garen Torikian
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.