As the world's [most popular API Gateway](https://konghq.com/blog/why-kong-is-the-best-api-gateway)most popular API Gateway, [Kong Gateway](https://docs.konghq.com/gateway/latest/)Kong Gateway is flexible and can be adapted to various environments and deployment configurations. This flexibility means some time should be taken to make good architectural decisions for the use cases in mind.
For example, the best configuration for a developer's workstation isn't the ideal one for a high SLA deployment. Fitness for purpose is therefore the objective.
### Considering requirements for your Kong configuration
When determining which deployment topology to use, it's prudent to consider the requirements that need to be met. This may cover things such as:
- - Configuration management
- - Reliability
- - Security
- - Latency
- - Scalability
- - Complexity
Generally speaking, the best deployment architecture is the one that meets its intended purpose with the minimum complexity possible. In this article, we explore some deployment examples and cover their suitability for various use cases.
## Single instance — DB-less (aka declarative configuration)
A single instance, DB-less (aka declarative configuration) deployment is arguably the [simplest deployment](https://docs.konghq.com/gateway/latest/reference/db-less-and-declarative-config/)simplest deployment possible of Kong.
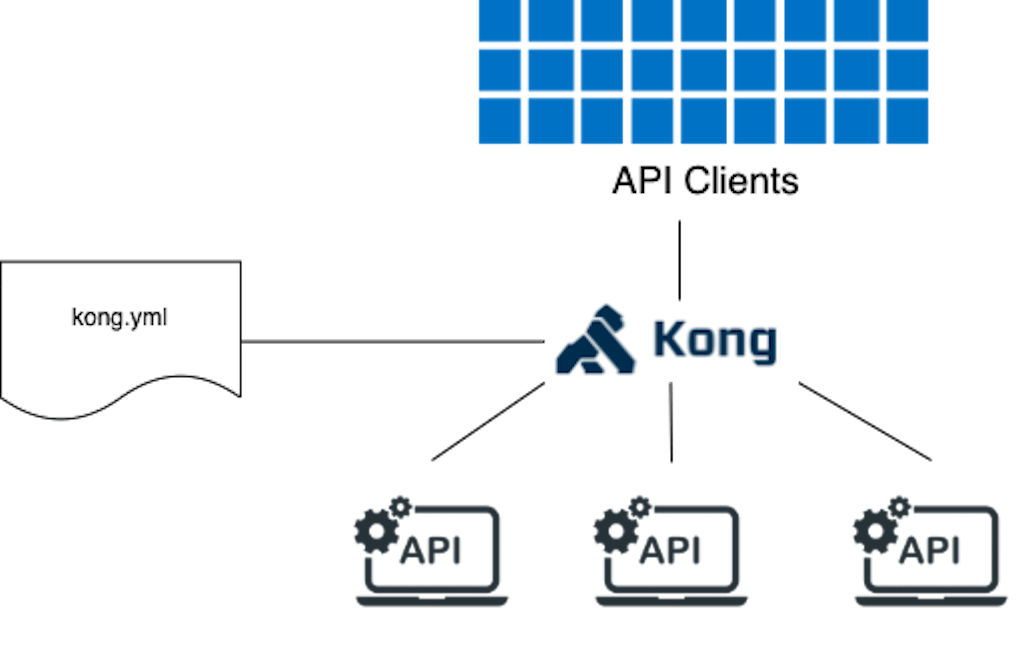
DB-less mode is good for local testing, as Kong can be quickly configured from a single declarative configuration file. The entities in the file (routes, services, plugins, clients, etc.) are loaded by Kong into memory, and no database is required.
The source of truth is the declarative configuration file, making it in effect the ‘control plane'. Kong accepts YAML or JSON declarative files when running in DB-less mode.
There are some limitations in this configuration. Plugins that [require a database](https://docs.konghq.com/konnect-platform/compatibility/plugins/)require a database are naturally not compatible. Secondly, the [admin API](https://docs.konghq.com/gateway/latest/admin-api/)admin API is for largely [read-only](https://docs.konghq.com/gateway/latest/production/deployment-topologies/db-less-and-declarative-config/#read-only-admin-api)read-only purposes. The /config endpoint is the exception that may be used to reload a configuration file with a new state.
This configuration can work for testing purposes, perhaps in a pipeline. It may also work in a development environment where the configuration is driven declaratively.
It can be used for production purposes. We'll forgo talking about reliability and scalability details for now.
## Single instance with database — traditional deployment
In a single instance with database — traditional deployment, Kong uses a database to maintain state. The database stores information about teams and permissions for role-based access control. It makes it possible to use Kong Manager UI, Vitals, and the Dev Portal — if using [Kong Enterprise](https://konghq.com/products/api-gateway-platform)Kong Enterprise.
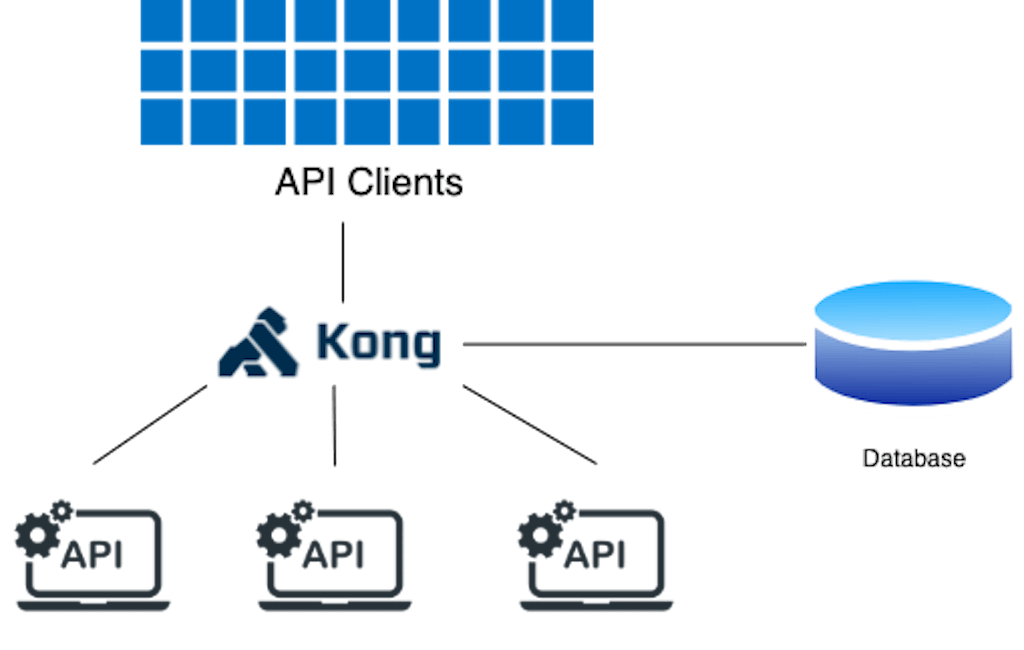
Plugins that require a database are also available for use. The single Kong instance is both the control and data plane. The Kong admin API is usable to alter Kong's state by creating entities (services, routes, plugins, etc.) as necessary. The Kong Manager UI may also be used for this purpose.
This is a classic, or embedded deployment, illustrated in this diagram. Readers may try this at will and for [various operating systems](https://docs.konghq.com/gateway/latest/install-and-run/)various operating systems.
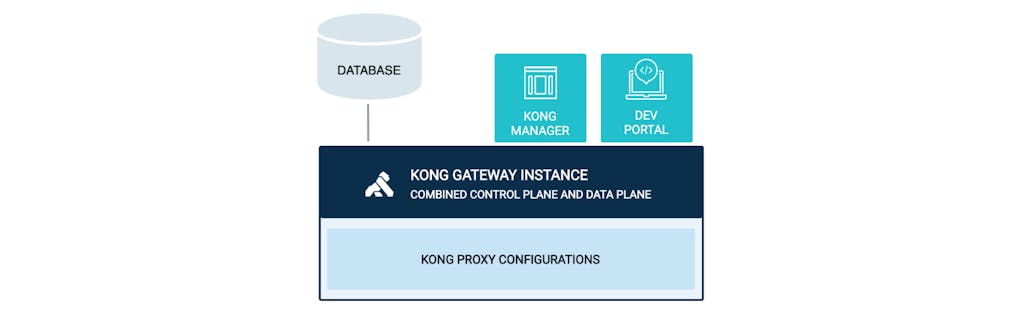
This is the deployment we usually run for doing demonstrations and development. It can be adapted for other scenarios. For example, we can only expose the portal if we wish to have the deployment serve API documentation only. Or we can only expose the Manager UI for visibility, or only the proxy port for traffic processing, and so on.
## Single instance with database and declarative configuration
Next, let's talk about a single instance with database and declarative configuration.
It may be argued that by enabling the Kong Admin API (as in the previous deployment) that it's an imperative configuration. While this is true, Kong may still be configured declaratively, using [decK](https://docs.konghq.com/deck/latest/)decK, illustrated in this diagram.
decK, or declarative Kong, is a tool that allows configuring Kong in a [declarative](https://blog.nelhage.com/post/declarative-configuration-management/)declarative manner. We still have access to all the features we get when using the database, and access to the [Admin API](https://docs.konghq.com/gateway/latest/admin-api/)Admin API.
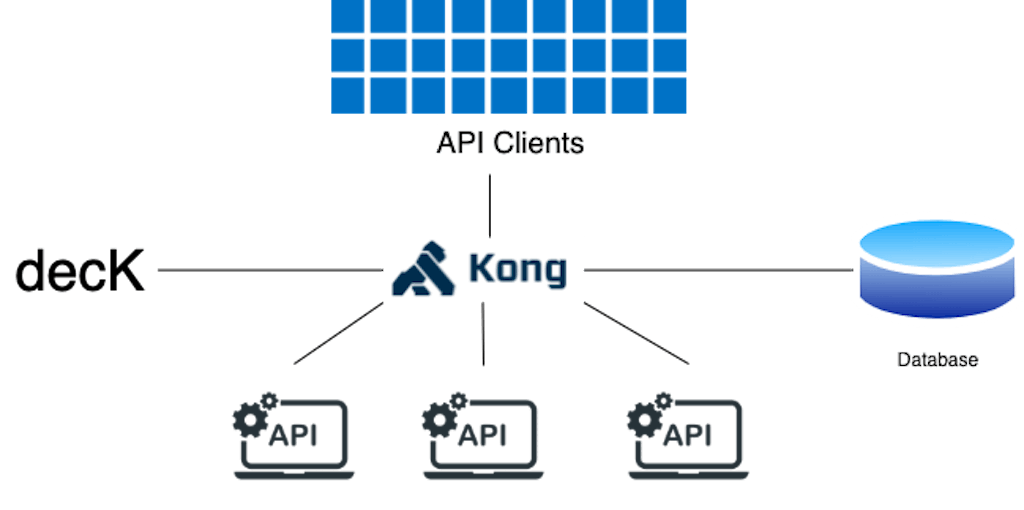
Given that decK is the "source of truth" of the gateway configuration, making changes via the Manager UI or Admin API is discouraged for production purposes. This is because mixing decK with Admin API could lead to states that are unpredictable or not easily replicable. Therefore, the "control plane" in this deployment is decK.
Kong Manager allows visibility on the configurations and metrics. It may alter administrative permissions, but it shouldn't alter the state of the proxy configurations unless there's a good reason to do so. (For example, an emergency update to a plugin, or configuration change while the pipeline is broken.)
This is the configuration I run most of the time on my laptop. I have access to the Kong Manager UI, all plugins and features are enabled, and I can configure Kong declaratively as well as imperatively if I must.
## Multiple Instances with database — distributed deployment
The previous deployments showed a single instance of Kong. These are useful for development, testing, and demonstration purposes, and in some rare occasions in a production environment. In most production deployments there are usually requirements for fault tolerance, scalability on demand, rolling upgrades, and so on. As the demands for SLAs increase, redundancy must increase as well. As failures are inevitable, some failure planning helps mitigate risk.
We now look at deployment models that are suitable for multiple instances of Kong in increasing resilience and ability to handle load.
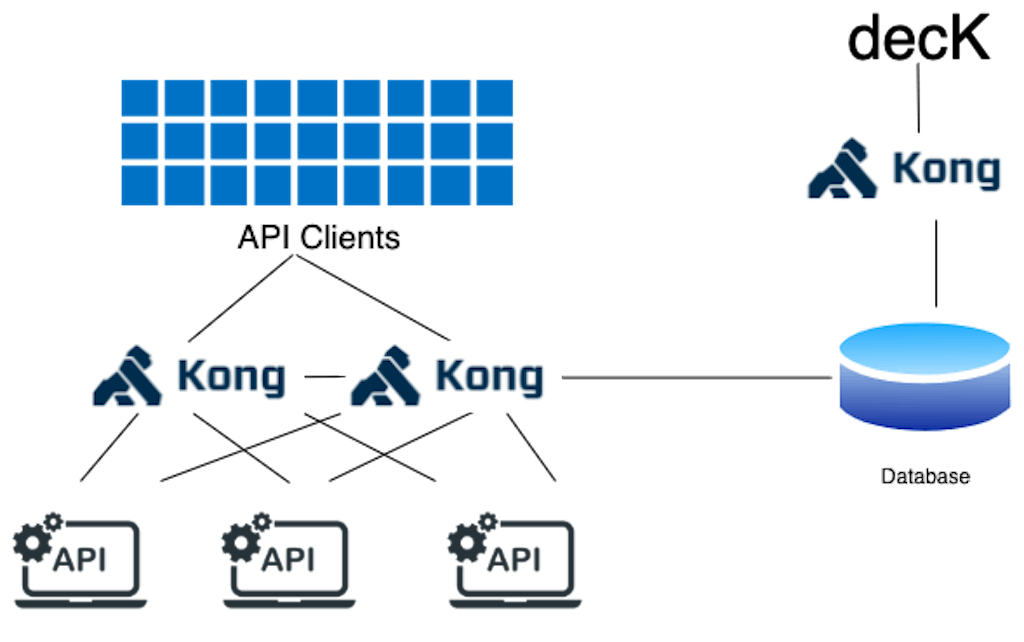
In the diagram above, there are three Kong instances. One of the instances, on the right, will enable/expose the Kong Admin API and/or UI, and the other two will not. In this way, one instance is the "control plane" and the other two instances are "data planes." The CP will store configurations into the database, which are then picked up by the data planes at a configurable interval as events.
Visualized another way:
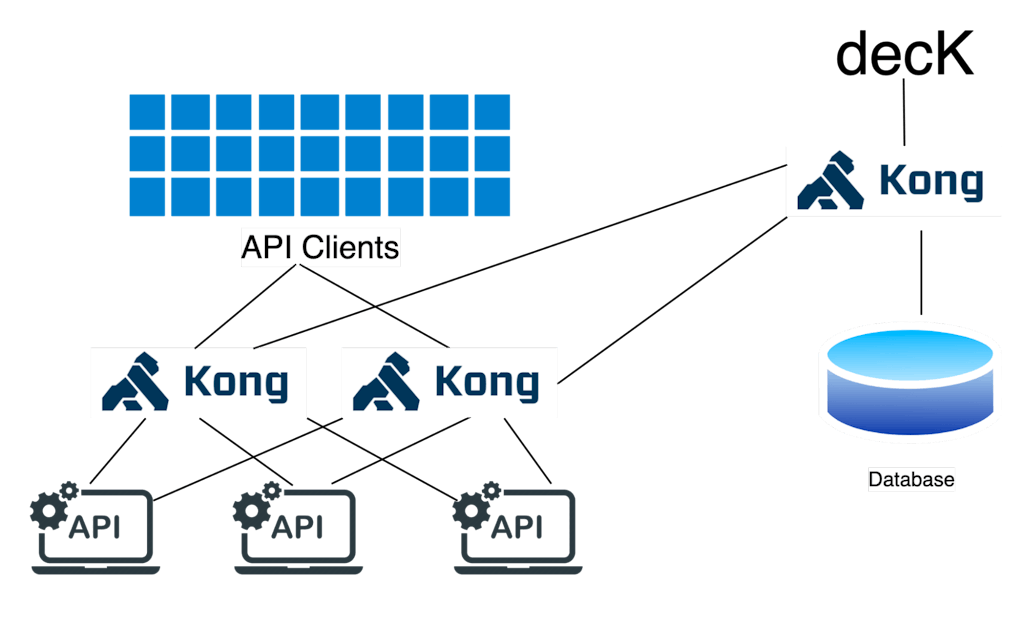
Much like in our previous deployment, using decK is possible when a declarative configuration approach is needed. We may introduce new instances of the data planes to handle increased load and offer higher resilience.
This distributed deployment inherently adds resilience through horizontal scalability. It may be further hardened through redundancy at every level, DB, network, redundancy at the control plane, etc. — and naturally to multiple regions, if necessary.
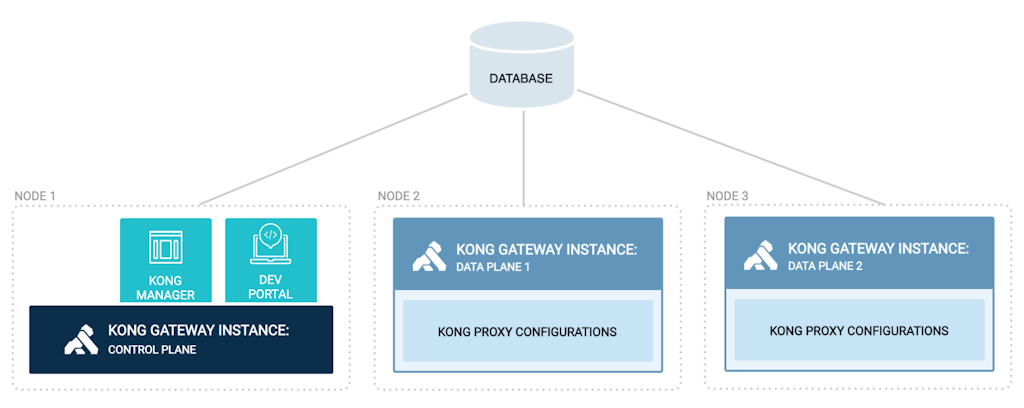
## Multiple instances with a database — hybrid deployment
In situations where data planes may not reach a database — perhaps due to security policy — the Kong control plane can propagate the configuration to the data planes via a persistent connection. It further collects telemetry data for tracking traffic and health metrics of the data planes.
Should the control plane be unavailable or the connection to it interrupted, the data planes will continue to operate with cached configurations in memory. Once the connection is reestablished, any new configurations are updated. Naturally, this change introduces a few [limitations](https://docs.konghq.com/gateway/latest/plan-and-deploy/hybrid-mode/#limitations)limitations. It otherwise is an alternative to the classic distributed deployment.
### Summary
We had a look at five deployment architectures in this article. We started with the simplest declarative deployment, then covered using a database, using decK, and running distributed, and finally hybrid deployments. This illustrates how Kong is flexible to meet various scenarios for deployments from a developer workstation, to production, and everything in between.
These deployments are not exhaustive; Kong is flexible well beyond this. The purpose is to illustrate possibilities and concepts.
In [my next post](https://konghq.com/blog/engineering/scaling-kubernetes-deployments-of-kong)my next post, we'll look at how we can run Kong on Kubernetes — with and without an Ingress Controller. Some interesting deployment architectures will follow. Until then, wishing you fun with deployments.
**Continued Learning & Related Content**








