In my previous post on [scaling Kong deployments with and without a database](https://konghq.com/blog/engineering/scaling-kong-deployments-with-and-without-databases)scaling Kong deployments with and without a database, we covered the concepts of deploying Kong with and without a database, as well as using decK, distributed, and hybrid deployments. In this article, we take a tour of some of the possible Kubernetes deployments of Kong.
Kubernetes (K8s) is the container orchestration war winner. While there are still deployments using other engines, we see K8s far more. K8s developers and operators appreciate how exposing the service of a K8s cluster can [get complex](https://itnext.io/kubernetes-clusterip-vs-nodeport-vs-loadbalancer-services-and-ingress-an-overview-with-722a07f3cfe1)get complex, and potentially expensive if using the cloud engines such as GKE, EKS, and AKS.
Kong runs **on **Kubernetes. It's a straightforward deployment that takes advantage of the usual K8s benefits. It may channel workloads running on K8s or non-K8s.
Kong may also play the role of an [Ingress Controller](https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/)Ingress Controller and simplify exposing API workloads on Kubernetes for consumption from distributed clients. Our own Viktor Gamov puts out awesome content and has a good intro on [KIC](https://www.youtube.com/watch?v=S-JNi5A_9-Q)KIC.
Let's examine some of these deployments.
## Kong on Kubernetes with database
Any of the configurations in my previous article may be translated to run on Kubernetes. The deployment simply lets Kong run and scale on Kubernetes. We may use a database or not. The database may be in the same cluster or remote. Kong can proxy traffic to Kubernetes Services, as well as services outside of a Kubernetes cluster.
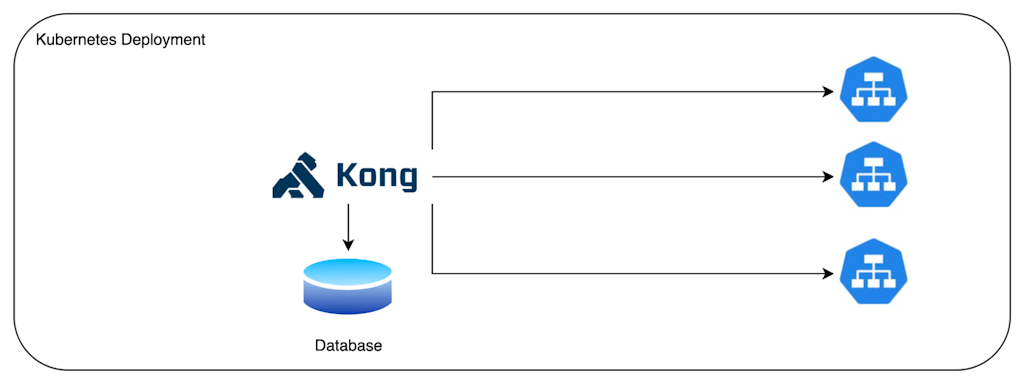
Options for configuring Kong remain available as before. We may use the Admin API, Manager, and decK. We may also deploy a distributed deployment on a cluster.
Naturally, when running on K8s, it would be beneficial to configure Kong in a manner similar to K8s entities. This is where the Kong Ingress Controller is useful. Let's go over how it works.
## Kong Ingress Controller — single Kong instance — DB-less
The Kong Kubernetes Ingress Controller allows configurations to the Kong Gateway to be accomplished using Kubernetes Resources.

In this deployment, Kong is running in DB-less mode. The configurations are represented as Kubernetes resources, which when translated, create Kong entities in the proxy. This simplifies configurations on Kubernetes as developers don't need to maintain two repositories. Without an ingress controller, developers will need to keep a repository for Kong Configuration with decK, for example, and another for their K8s applications. Exposing K8s services other than Kong is straightforward since this is done with K8s objects/configurations, such as [**Ingress**](https://kubernetes.io/docs/concepts/services-networking/ingress/)**Ingress**. Kong introduces some [resources](https://docs.konghq.com/kubernetes-ingress-controller/latest/#custom-resources)resources for applying policies and the like.
This therefore is a K8s native way to run Kong. Similar to the deployments we covered in the first article, we can increase the scalability and resilience at will.
## Kong Ingress Controller — multiple Kong instances — DB-less
So how can we scale a Kong deployment on K8s? One way to do so is to run multiple instances of Kong as Kubernetes supports horizontal scaling. Each instance is configurable from the controller in its pod. These instances are exposed as a K8s Service, typically of type **LoadBlanacer** when running on common K8s cloud flavors.
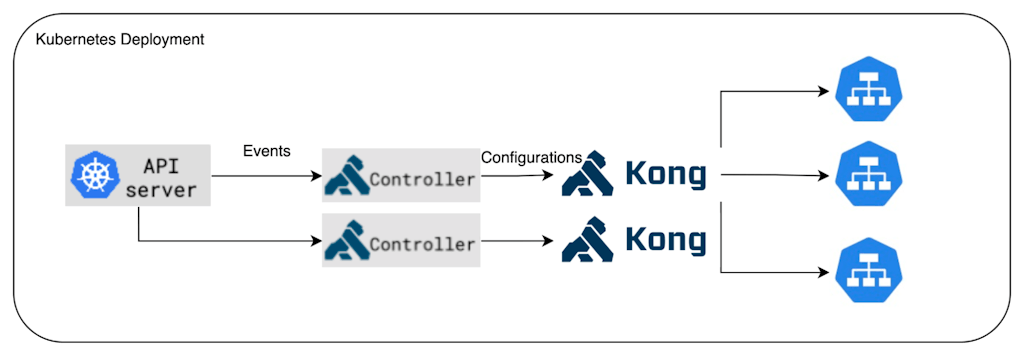
All instances have identical configurations and are updated with new configurations as they arrive via K8s resources.
## Kong Ingress Controller — with a database
As in the previous article, if we want to take advantage of features that work with a database, we can introduce control plane and data plane separation. The data plane instance(s) are able to pick up configuration changes from the database and can be scaled horizontally at will. In this diagram we have a single instance, however, we can scale them as needed.
The control plane — also scalable horizontally — is composed of the ingress controller and a Kong control plane instance. When multiple control planes are running, a [leader election process](https://docs.konghq.com/kubernetes-ingress-controller/latest/concepts/deployment/#database)leader election process takes place to ensure that only one of the controllers is updating the database.
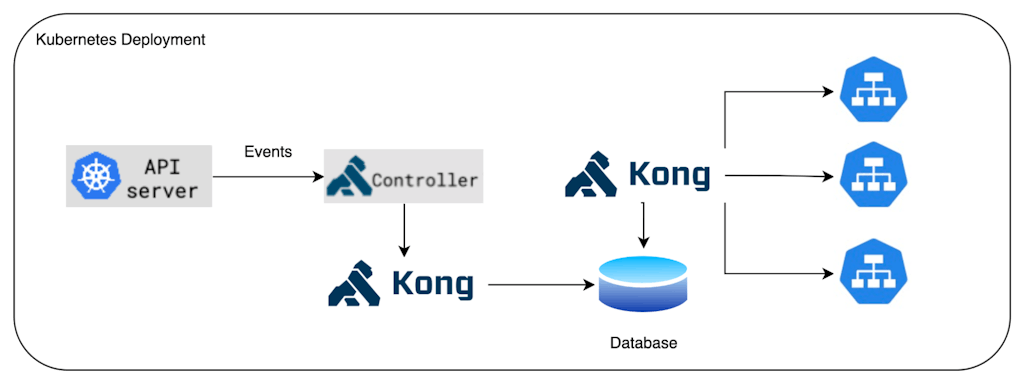
You may notice that we're largely replicating the deployments we saw in the previous article. The key difference is that we let K8s do some of the work for us.
## Multiple Kong Ingress Controllers — without a database
So far our Kong deployments consumed all K8s resources in the cluster that are intended for Kong. If it's necessary to isolate a controller on a Kubernetes namespace basis (such that different teams are segregated within a Kubernetes cluster), then running multiple controllers is a possible approach.
In this deployment, each ingress controller is watching a namespace for objects, and once detected, it translates them into configurations into a Kong instance. We have two Ingress Controllers and two gateways.
## Multiple Kong Ingress Controllers — with a database
Taking the previous example further again, we introduce control plane and data plane separation. Multiple ingress controllers are monitoring a K8s namespace each. These controllers translate the K8s resources into Kong entities that are persisted in the database by the control plane. Each ingress controller may name a specific namespace on the control plane such that there is a one-to-one correspondence between K8s namespaces and Kong workspaces. The data planes services synchronize the entities from the database as configurations, which are also segregated as Kong workspaces.

In this diagram, the control plane has a single instance, which naturally may be scaled horizontally for increased reliability.
### Conclusion
The main ingredients we work with are few. They are the database, Kong, and the controller. Yet, depending on what we want or want to do, we arrange them in a way that fits our needs — be that to scale and handle more load, isolate projects, or have more reliability.
Speaking of reliability, we're now ready to look into how we can put together an architecture that has a good bit of resilience. I'll cover this in my next article on a highly scalable distributed deployment that may span multiple regions.
**Continued Learning & Related Content**








