# Semantic Processing and Vector Similarity Search with Kong and Redis
Claudio Acquaviva
Principal Architect, Kong
Kong has supported Redis since its early versions. In fact, the integration between Kong Gateway and Redis is a powerful combination to enhance API management. We can summarize the integration points and use cases of Kong and Redis into three main groups:
- **Kong Gateway:** Kong integrates with Redis via plugins that enable it to leverage Redis’ capabilities for enhanced API functionality including Caching, Rate Limiting and Session Management.
- **Kong AI Gateway**: Starting with Kong Gateway 3.6, several new AI-based plugins leverage Redis Vector Databases to implement AI use cases, like Rate Limiting policies based on LLM tokens, Semantic Caching, Semantic Prompt Guards, and Semantic Routing.
- **RAG and Agent Applications**: Kong AI Gateway and Redis can collaborate for AI-based applications using frameworks like LangChain and LangGraph.
This blog post focuses on how Kong and Redis can be used to address Semantic Processing use cases like Similarity Search and Semantic Routing across multiple LLM environments.
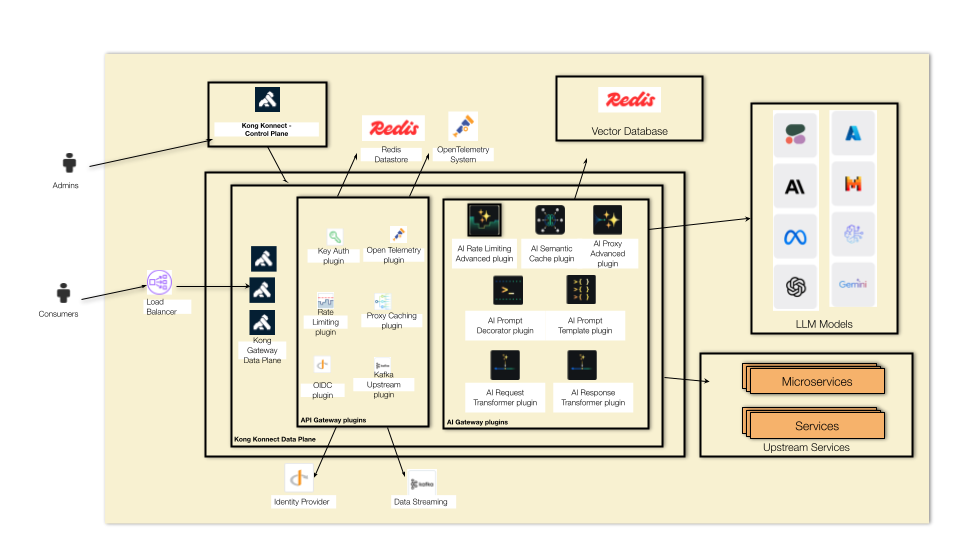
## Kong AI Gateway Reference Architecture
To get started let's take a look at a high-level reference architecture of the Kong AI Gateway. As you can see, the Kong Gateway Data Plane, responsible for handling the incoming traffic, can be configured with two types of Kong Plugins:
### Kong Gateway plugins
One of the main capabilities provided by Kong Gateway is extensibility. An extensive list of plugins allows you to implement specific policies to protect and control the APIs deployed in the Gateway. The plugins offload critical and complex processing usually implemented by backend services and applications. With the Gateway and its plugins in place, the backend services can focus on business logic only, leading to a faster application development process. Each plugin is responsible for specific functionality, including:
- Authentication/authorization: to implement security mechanisms such as Basic Authentication, LDAP, Mutual TLS (mTLS), API Key, OPA (Open Policy Agent) based access control policies, etc.
- Integration with Kafka-based Data/Event Streaming infrastructures.
- Log processing: to externalize all requests processed by the Gateway to third-party infrastructures.
- Analytics and monitoring: to provide metrics to external systems, including OpenTelemetry-based systems and Prometheus.
- Traffic control: to implement canary releases, mocking endpoints, routing policies based on request headers, etc.
- Transformations: to transform requests before routing them to the upstreams and to transform responses before returning to the consumers.
- For IoT projects, where MQTT over WebSockets connections are extensively used, Kong provides WebSockets Size Limit and WebSockets Validator plugins to control the events sent by the devices.
Also, Kong Gateway provides plugins that implement several integration points with Redis:
On the other hand, Kong AI Gateway leverages the existing Kong API Gateway extensibility model to provide specific AI-based plugins, more precisely to protect LLM infrastructures:
By leveraging the same underlying core of Kong Gateway, and combining both categories of plugins, we can implement powerful policies and reduce complexity in deploying the AI Gateway capabilities as well.
The first use case we are going to focus on is Semantic Cache where the AI Gateway plugin integrates with Redis to perform Similarity Search. Then, we are going to explore how the AI Proxy Advanced Plugin can take advantage of Redis to implement Semantic Routing across multiple LLMs models.
As a remark, AI Rate Limiting Advanced and AI Semantic Prompt Guard Plugins are two other examples where AI Gateway and Redis work together.
Before diving into the first use case, let's highlight and summarize the main concepts Kong AI Gateway and Redis rely on.
### Embeddings
Embeddings (aka Vectors or even Vector Embeddings) are a representation of unstructured data like text, images, etc. In a LLM context, the dimensionality of the Embeddings refers to the number of characteristics captured in the vector representation of a given sentence: the more dimensions an Embedding has, the better and more effective it is.
There are multiple ML-based embedding methods used in NLP like:
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import truncate_embeddings
model = SentenceTransformer('all-mpnet-base-v2', cache_folder="./")
embeddings = model.encode("Who is Joseph Conrad?")
embeddings = truncate_embeddings(embeddings,3)
print(embeddings.size)
print(embeddings)
The “all-mpnet-base-v2” Embedding Model encodes sentences to a 768-dimensional Vector. As an experiment, we have truncated the vector to 3 dimensions only.
The output should be like:
3[0.06030013-0.007825230.01018228]
### Vector Database
A Vector Database stores and searches Vector Embeddings. They are essential for AI-based applications supporting images, texts, etc., providing Vector Stores, Vector Indexes, and more importantly, algorithms to implement Vector Similarity Searches.
In addition, Redis can be deployed as as enterprise software and/or as a cloud service, thereby adding several enterprise capabilities including:
- **Scalability**: Redis can easily scale horizontally and effortlessly handle dynamic workloads and ability to manage massive datasets across distributed architectures.
- **High availability and persistence**: Redis supports high availability with built-in support for multi-AZ deployments, seamless failover, data persistence through backups and active-active architecture, enabling robust disaster recovery and consistent application performance.
- **Flexibility**: Redis natively supports multiple data structures such as JSON, Hash, Strings, Streams, and more to suit diverse application needs.
With similarity search we can find, in a typically unstructured dataset, items similar (or dissimilar) to a certain presented item. For example, given a picture of a cell phone, try to find similar ones considering its shape, color, etc. Or, given two pictures, check the similarity score between them.
In our NLP context, we are interested in similar responses returned by the LLM when applications send prompts to it. For example, these two following sentences “Who is Joseph Conrad?” and “Tell me more about Joseph Conrad”, semantically speaking, should have a high similarity score.
We can extend our Python script to try that out:
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-mpnet-base-v2', cache_folder="./")
sentences = ["Who is Joseph Conrad?","Tell me more about Joseph Conrad.","Living is easy with eyes closed.",]
embeddings = model.encode(sentences)
print(embeddings.shape)
similarities = model.similarity(embeddings, embeddings)
print(similarities)
The output should be like this. The embeddings are
The “shape” is composed of 3 embeddings of 768 dimensions each. The code asks to cross-check the similarity of all embeddings. The more similar they are, the higher the score. Notice that the “1.0000” score is returned, as expected, when self-checking a given embedding.
To get a better understanding of how RedisVSS works, consider this Python script implementing a basic similarity search. Make sure you have set the “OPENAI_API_TYPE” environment variable as “openai" before running the script.
import redis
from redis.commands.search.field import TextField, VectorField
from redis.commands.search.indexDefinition import IndexDefinition, IndexType
from redis.commands.search.query import Query
import numpy as np
import openai
import os
### Get environment variables
openai.api_key = os.getenv("OPENAI_API_KEY")
host = os.getenv("REDIS_LB")
### Create a Redis Index for the Vector Embeddings
client = redis.Redis(host=host, port=6379)
try: client.ft('index1').dropindex(delete_documents=True)
except: print("index does not exist")
schema = (
TextField("name"), TextField("description"), VectorField(
"vector","FLAT",{"TYPE":"FLOAT32","DIM":1536,"DISTANCE_METRIC":"COSINE",} ),)
definition = IndexDefinition(prefix=["vectors:"], index_type=IndexType.HASH)
res = client.ft("index1").create_index(fields=schema, definition=definition)
### Step 1: call OpenAI to generate Embeddings for the reference text and stores it in Redis
name = "vector1"content = "Who is Joseph Conrad?"redis_key = f"vectors:{name}"res = openai.embeddings.create(input=content, model="text-embedding-3-small").data[0].embedding
embeddings = np.array(res, dtype=np.float32).tobytes()
pipe = client.pipeline()
pipe.hset(redis_key, mapping = {"name": name,"description": content,"vector": embeddings
})
res = pipe.execute()
### Step 2: perform Vector Range queries with 2 new texts and get the distance (similarity) score
query = (
Query("@vector:[VECTOR_RANGE $radius $vec]=>{$yield_distance_as: distance_score}")
.return_fields("id","distance_score")
.dialect(2)
)
# Text #1content = "Tell me more about Joseph Conrad"res = openai.embeddings.create(input=content, model="text-embedding-3-small").data[0].embedding
new_embeddings = np.array(res, dtype=np.float32).tobytes()
query_params = {"radius":1,"vec": new_embeddings
}res = client.ft("index1").search(query, query_params).docs
print(res)
# Text #2content = "Living is easy with eyes closed"res = openai.embeddings.create(input=content, model="text-embedding-3-small").data[0].embedding
new_embeddings = np.array(res, dtype=np.float32).tobytes()
query_params = {"radius":1,"vec": new_embeddings
}res = client.ft("index1").search(query, query_params).docs
print(res)
Initially, the script creates an index to receive the embeddings returned by OpenAI. We are using the “text-embedding-3-small” OpenAI model, which has 1536 dimensions, so the index has a VectorField defined to support those dimensions.
Next, the script has two steps:
- Stores the embeddings of a reference text, generated by OpenAI Embedding Model.
- Performs Vector Range queries passing two new texts to check their similarity with the original one.
Our script's intent is to examine the distance between the two vectors and not implement any filter. That’s the reason why it has set the Vector Range Query with `"radius": 1`.
After running the script, its output should be like:
That means that, as expected, the stored embedding, related to the reference text "Who is Joseph Conrad?", is closer to the first new text, “Tell me more about Joseph Conrad”, than to the second one “Living is easy with eyes closed”.
Now that we have an introductory perspective of how we can implement Vector Similarity Searches with Redis, let’s examine the Kong AI Gateway Semantic Cache Plugin which is responsible for implementing semantic caching. We'll see it performs similar searches to what we have done with the Python script.
## Kong AI Semantic Cache Plugin
To get started, logically speaking, we can analyze the Caching flow from two different perspectives:
- Request #1: We don't have any data cached.
- Request #2: Kong AI Gateway has stored some data in the Redis Vector Database.
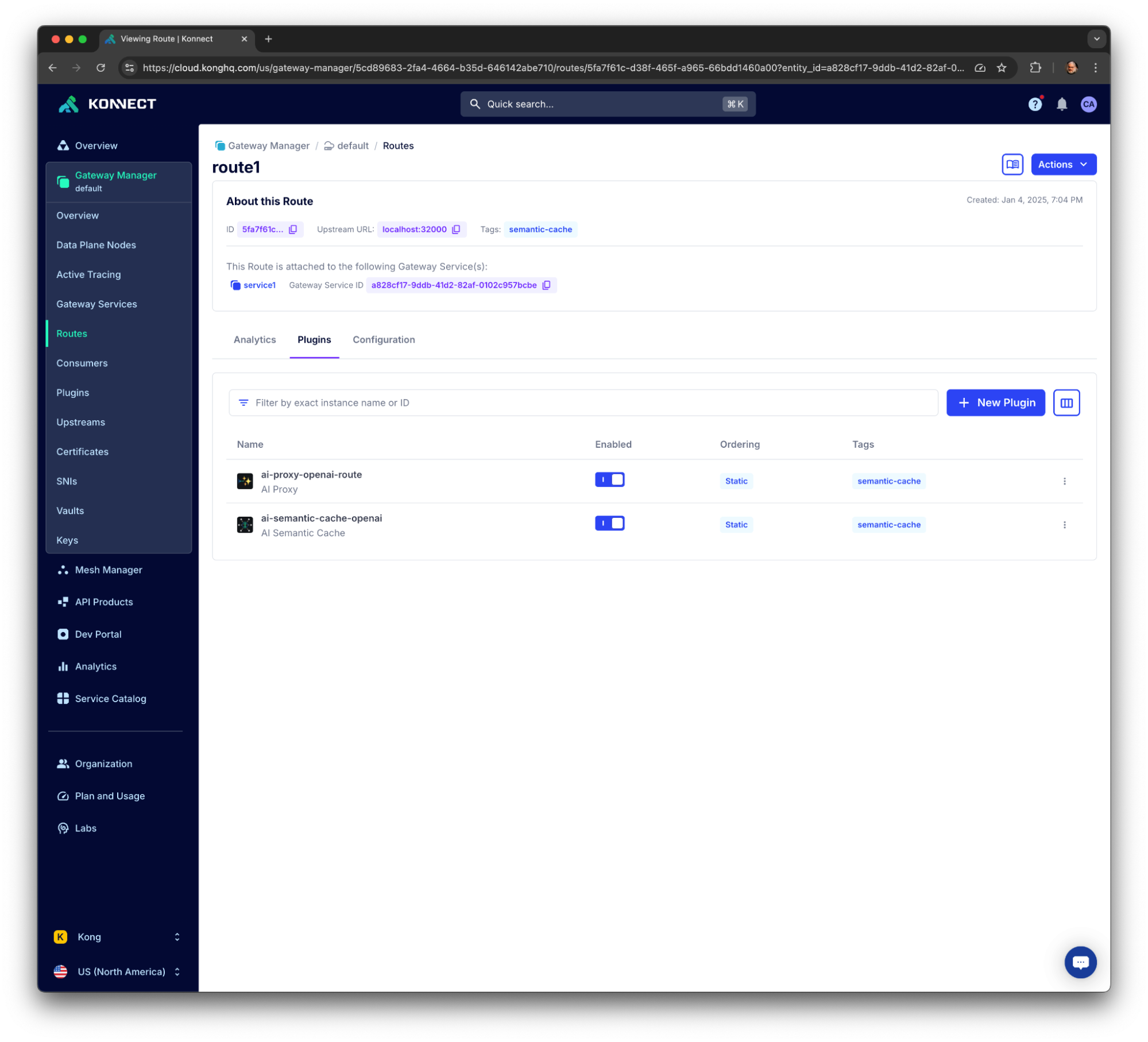
The declaration creates the following Kong Objects in the “default” Konnect Control Plane::
- Kong Gateway Service “service1”. It's a fake service. In fact, the Kong AI Proxy plugin created next will determine the actual upstream destination.
- Kong Route “route1” with the path “/openai-route”. That's the route which exposes the LLM model.
- AI Proxy Plugin. It's configured to consume OpenAI's “gpt-4” model. The “route_type” parameter, set as “llm/v1/chat”, refers to OpenAI's “https://api.openai.com/v1/chat/completions” endpoint. Kong recommends storing the API Keys as secrets in a Secret Manager like AWS Secrets Manager or HashiCorp Vault. The current configuration, including the OpenAI API Key in the declaration, is for lab environments only, not recommended for production. Please refer to the official [AI Proxy Plugin documentation page](https://docs.konghq.com/hub/kong-inc/ai-proxy/)AI Proxy Plugin documentation page to learn more about its configuration.
-
AI Semantic Cache Plugin. It has two settings. Please check the
- `embeddings`: consumed the “text-embedding-3-small” Embedding Model, the same model we used in our Python script.
- `vectordb`: refers to an existing Redis infrastructure to store the embeddings and process the VSS requests. Again, it's configured with the same dimensions and distance metric as we used before. The threshold is going to be translated as the “radius” parameter in the VSS queries sent by the Kong Gateway Data Plane.
After submitting the decK declaration to Konnect, you should see the new Objects using the Konnect UI:
### Request #1
With the new Kong Objects in place, the Kong Data Plane is refreshed with them, and we are ready to start sending requests to it. Here's the first one with the same content we used in the Python script:
curl -i -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{"messages":[{"role":"user","content":"Who is Joseph Conrad?"}]}'
You should get a response like this, meaning the Gateway successfully routed the request to OpenAI which returned an actual message to us. From Semantic Caching and Similarity perspective, the most important headers are:
- `X-Cache-Status: Miss`, telling us the Gateway wasn't able to find any data in the cache to satisfy the request.
- `X-Kong-Upstream-Latency` and `X-Kong-Proxy-Latency`, showing the latency times.
HTTP/1.1200 OK
Content-Type: application/json
Connection: keep-alive
X-Cache-Status: Miss
x-ratelimit-limit-requests:10000CF-RAY: 8fce86cde915eae2-ORD
x-ratelimit-limit-tokens:10000x-ratelimit-remaining-requests:9999x-ratelimit-remaining-tokens:9481x-ratelimit-reset-requests:8.64s
x-ratelimit-reset-tokens:3.114s
access-control-expose-headers: X-Request-ID
x-request-id: req_29afd8838136a2f7793d6c129430b341
X-Content-Type-Options: nosniff
openai-organization: user-4qzstwunaw6d1dhwnga5bc5q
Date: Sat,04 Jan 202522:05:00 GMT
alt-svc: h3=":443"; ma=86400openai-processing-ms:10002openai-version:2020-10-01CF-Cache-Status: DYNAMIC
strict-transport-security: max-age=31536000; includeSubDomains; preload
Server: cloudflare
Content-Length:1456X-Kong-LLM-Model: openai/gpt-4X-Kong-Upstream-Latency:10097X-Kong-Proxy-Latency:471Via:1.1 kong/3.9.0.0-enterprise-edition
X-Kong-Request-Id: 36f6b41df3b74f78f586ae327af27075
{"id":"chatcmpl-Am6YEtvUquPHdHdcI59eZC3UfOUVz","object":"chat.completion","created":1736028290,"model":"gpt-4-0613","choices":[{"index":0,"message":{"role":"assistant","content":"Joseph Conrad was a Polish-British writer regarded as one of the greatest novelists to write in the English language. He was born on December 3, 1857, and died on August 3, 1924. Though he did not speak English fluently until his twenties, he was a master prose stylist who brought a non-English sensibility into English literature.\n\nConrad wrote stories and novels, many with a nautical setting, that depict trials of the human spirit in the midst of what he saw as an impassive, inscrutable universe. His notable works include \"Heart of Darkness\", \"Lord Jim\", and \"Nostromo\". Conrad's writing often presents a deep, pessimistic view of the world and deals with the theme of the clash of cultures and moral ambiguity.","refusal":null},"logprobs":null,"finish_reason":"stop"}],"usage":{"prompt_tokens":12,"completion_tokens":163,"total_tokens":175,"prompt_tokens_details":{"cached_tokens":0,"audio_tokens":0},"completion_tokens_details":{"reasoning_tokens":0,"audio_tokens":0,"accepted_prediction_tokens":0,"rejected_prediction_tokens":0}},"system_fingerprint":null}
#### Redis Introspection
Kong Gateway creates a new index. You can check it with `redis-cli ft._list`. The index should be named like: `idx:vss_kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4`
And `redis-cli ft.search idx:vss_kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4 "*" return 1 -` should return the ID of OpenAI's response. Something like:
3. Run a VSS to check if there's a key which satisfies the request. The command looks like this. Again, notice the command is the same we used in our Python script. The “range” parameter reflects the “threshold” configuration used in the decK declaration.
4. Since the index has just been created, the VSS couldn't find any key so the plugin sends a `"JSON.SET"` command to add a new index key with the embeddings received from OpenAI.
5. `"expire"` command to set the expiration time of the key as, by default, 300 seconds.
You can check the new index key using the Redis dashboard:
### Request #2
If we send another request with similar content, the Gateway should return the same response, since it's going to take from the Cache, as noticed in the `X-Cache-Status: Hit` header. Besides, the response has specific header related to the cache: `X-Cache-Key` and `X-Cache-Ttl`.
The response should be returned faster, since the Gateway didn't have to route the request to OpenAI.
curl -i -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{"messages":[{"role":"user","content":"Tell me more about Joseph Conrad"}]}'
HTTP/1.1200 OK
Date: Sun,05 Jan 202514:28:59 GMT
Content-Type: application/json; charset=utf-8Connection: keep-alive
X-Cache-Status: Hit
Age:0X-Cache-Key: kong_semantic_cache:511efd84-117b-4c89-87cb-f92f9b74a6c0:openai-gpt-4:fcdf7d8995a227392f839b4530f8d8c3055748b96275fa9558523619172fd2a8
X-Cache-Ttl:288Content-Length:1020X-Kong-Response-Latency:221Server: kong/3.9.0.0-enterprise-edition
X-Kong-Request-Id: eef1373a3a688a68f088a52f72318315
{"object":"chat.completion","system_fingerprint":null,"id":"fcdf7d8995a22…….
If you send another request with non-similar content, the plugin creates a new index key. For example:
curl -i -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{"messages":[{"role":"user","content":"Living is easy with eyes closed"}]}'
## Kong AI Proxy Advanced Plugin and Semantic Routing
Kong AI Gateway provides several semantic based capabilities besides caching. A powerful one is Semantic Routing. With such a feature, we can let the Gateway decide the best model to handle a given request. For example, you might have models trained in specific topics, like Mathematics or Classical Music, so it'd be interesting to route the requests depending on the presented content. By analyzing the content of the request, the plugin can match it to the most appropriate model that is known to perform better in similar contexts. This feature enhances the flexibility and efficiency of model selection, especially when dealing with a diverse range of AI providers and models.
For the purpose of this blog post we are going to explore the Semantic Routing algorithm.
The diagram below shows how the AI Proxy Advanced Plugin works:
- At the configuration time, the plugin sends requests to an Embeddings Model based on descriptions defined. The embeddings returned are stored in Redis Vector Database.
- During request processing time, the plugin gets the request content and sends a VSS query to Redis Vector Database. Depending on the similarity score, the plugin routes the request to the best targeted LLM model sitting behind the Gateway.
- `balancer` with `algorithm`: `semantic`, telling the load balancer will be based on Semantic Routing.
- `embeddings` with the necessary setting to reach out the Embedding Model. The same observations made previously regarding the API Key remains here.
- `vectordb` with the Redis host and Index configurations as well as the threshold to drive the VSS query.
- `targets`: each one of them represents a LLM model. Note the description parameter is used to configure the load balancing algorithm according to the topic the model has been trained for.
As you can see, for convenience's sake, the configuration uses OpenAI's model for embeddings and targets. Also, just for this exploration, we are also using the `gpt-4` and `gpt-4o-mini` OpenAI's models for the targets.
After submitting the decK declaration to Konnect Control Plane, the Redis Vector Database should have a new index defined and a key for each target created. We can then start sending requests to the Gateway. The first two requests have contents related to Classical Musical, so the response should come from the related model, `gpt-4o-mini-2024-07-18`.
% curl -s -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{"messages":[{"role":"user","content":"Who wrote the Hungarian Rhapsodies piano pieces?"}]}' | jq '.model'
"gpt-4o-mini-2024-07-18"
% curl -s -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{"messages":[{"role":"user","content":"Tell me a contemporary pianist of Chopin"}]}' | jq '.model'
"gpt-4o-mini-2024-07-18"
Now, the next request is related to Mathematics, therefore the response comes from the other model, `gpt-4-0613`.
% curl -s -X POST \
--url $DATA_PLANE_LB/openai-route \
--header 'Content-Type: application/json' \
--data '{"messages":[{"role":"user","content":"Tell me about Fermat''s last theorem"}]}' | jq '.model'
"gpt-4-0613"
## Conclusion
Kong has historically supported Redis to implement a variety of critical policies and use cases. The most recent collaborations, implemented by the Kong AI Gateway, focus on Semantic Processing where Redis Vector Similarity Search capabilities play an important role.
This blog post explored two main semantic-based use cases: Semantic Caching and Semantic Routing. Check Kong's and Redis’ documentation pages to learn more about the extensive list of API and AI Gateway use cases you can implement using both technologies.
AI governance is the set of principles, roles, processes, and controls an organization uses to deploy AI safely, ethically, and in compliance with the law. It defines who is accountable for AI decisions, how risk is managed, and how systems stay tra
Kong
# Insights from eBay: How API Ecosystems Are Ushering In the Agentic Era
APIs have quietly powered the global shift to an interconnected economy. They’ve served as the data exchange highways behind the seamless experiences we now take for granted — booking a ride, paying a vendor, sending a message, syncing financial rec
Amit Dey
# Kong AI/MCP Gateway and Kong MCP Server Technical Breakdown
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
# AI Voice Agents with Kong AI Gateway and Cerebras
Kong Gateway is an API gateway and a core component of the Kong Konnect platform . Built on a plugin-based extensibility model, it centralizes essential functions such as proxying, routing, load balancing, and health checking, efficiently manag
Claudio Acquaviva
# AI Guardrails: Ensure Safe, Responsible, Cost-Effective AI Integration
Why AI guardrails matter It's natural to consider the necessity of guardrails for your sophisticated AI implementations. The truth is, much like any powerful technology, AI requires a set of protective measures to ensure its reliability and integrit
Jason Matis
# Securing Enterprise AI: OWASP Top 10 LLM Vulnerabilities Guide
Introduction to OWASP Top 10 for LLM Applications 2025 The OWASP Top 10 for LLM Applications 2025 represents a significant evolution in AI security guidance, reflecting the rapid maturation of enterprise AI deployments over the past year. The key up
Michael Field
# How to Build a Single LLM AI Agent with Kong AI Gateway and LangGraph
In my previous post, we discussed how we can implement a basic AI Agent with Kong AI Gateway. In part two of this series, we're going to review LangGraph fundamentals, rewrite the AI Agent and explore how Kong AI Gateway can be used to protect an LLM
AI governance is the set of principles, roles, processes, and controls an organization uses to deploy AI safely, ethically, and in compliance with the law. It defines who is accountable for AI decisions, how risk is managed, and how systems stay tra
Kong
# Insights from eBay: How API Ecosystems Are Ushering In the Agentic Era
APIs have quietly powered the global shift to an interconnected economy. They’ve served as the data exchange highways behind the seamless experiences we now take for granted — booking a ride, paying a vendor, sending a message, syncing financial rec
Amit Dey
# Kong AI/MCP Gateway and Kong MCP Server Technical Breakdown
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
# AI Voice Agents with Kong AI Gateway and Cerebras
Kong Gateway is an API gateway and a core component of the Kong Konnect platform . Built on a plugin-based extensibility model, it centralizes essential functions such as proxying, routing, load balancing, and health checking, efficiently manag
Claudio Acquaviva
# AI Guardrails: Ensure Safe, Responsible, Cost-Effective AI Integration
Why AI guardrails matter It's natural to consider the necessity of guardrails for your sophisticated AI implementations. The truth is, much like any powerful technology, AI requires a set of protective measures to ensure its reliability and integrit
Jason Matis
# Securing Enterprise AI: OWASP Top 10 LLM Vulnerabilities Guide
Introduction to OWASP Top 10 for LLM Applications 2025 The OWASP Top 10 for LLM Applications 2025 represents a significant evolution in AI security guidance, reflecting the rapid maturation of enterprise AI deployments over the past year. The key up
Michael Field
# How to Build a Single LLM AI Agent with Kong AI Gateway and LangGraph
In my previous post, we discussed how we can implement a basic AI Agent with Kong AI Gateway. In part two of this series, we're going to review LangGraph fundamentals, rewrite the AI Agent and explore how Kong AI Gateway can be used to protect an LLM
AI governance is the set of principles, roles, processes, and controls an organization uses to deploy AI safely, ethically, and in compliance with the law. It defines who is accountable for AI decisions, how risk is managed, and how systems stay tra
Kong
# Insights from eBay: How API Ecosystems Are Ushering In the Agentic Era
APIs have quietly powered the global shift to an interconnected economy. They’ve served as the data exchange highways behind the seamless experiences we now take for granted — booking a ride, paying a vendor, sending a message, syncing financial rec
Amit Dey
# Kong AI/MCP Gateway and Kong MCP Server Technical Breakdown
In the latest Kong Gateway 3.12 release , announced October 2025, specific MCP capabilities have been released: AI MCP Proxy plugin: it works as a protocol bridge, translating between MCP and HTTP so that MCP-compatible clients can either call exi
Jason Matis
# AI Voice Agents with Kong AI Gateway and Cerebras
Kong Gateway is an API gateway and a core component of the Kong Konnect platform . Built on a plugin-based extensibility model, it centralizes essential functions such as proxying, routing, load balancing, and health checking, efficiently manag
Claudio Acquaviva
# AI Guardrails: Ensure Safe, Responsible, Cost-Effective AI Integration
Why AI guardrails matter It's natural to consider the necessity of guardrails for your sophisticated AI implementations. The truth is, much like any powerful technology, AI requires a set of protective measures to ensure its reliability and integrit
Jason Matis
# Securing Enterprise AI: OWASP Top 10 LLM Vulnerabilities Guide
Introduction to OWASP Top 10 for LLM Applications 2025 The OWASP Top 10 for LLM Applications 2025 represents a significant evolution in AI security guidance, reflecting the rapid maturation of enterprise AI deployments over the past year. The key up
Michael Field
# How to Build a Single LLM AI Agent with Kong AI Gateway and LangGraph
In my previous post, we discussed how we can implement a basic AI Agent with Kong AI Gateway. In part two of this series, we're going to review LangGraph fundamentals, rewrite the AI Agent and explore how Kong AI Gateway can be used to protect an LLM
Claudio Acquaviva
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.