*This article was written by Jeremy Justus and Ross Sbriscia, senior software engineers from UnitedHealth Group/Optum.**This blog post is part three of a three-part series on how they've scaled their API management with *[*Kong Gateway*](https://konghq.com/kong)*Kong Gateway**, the world's most popular open source API gateway. (Here's *[*part 1*](https://konghq.com/blog/unitedhealth-group-kong-gateway)*part 1** and *[*part 2*](https://konghq.com/blog/open-source-api-gateway-large-enterprise)*part 2**.)*
In 2019, our Kong-based API gateway platform hosted about 1,900 proxies and handled 375 million transactions per month. 2020 saw a tenfold increase in both metrics to more than 11,000 proxies and 4.5 billion transactions per month—about 150 million transactions per day.
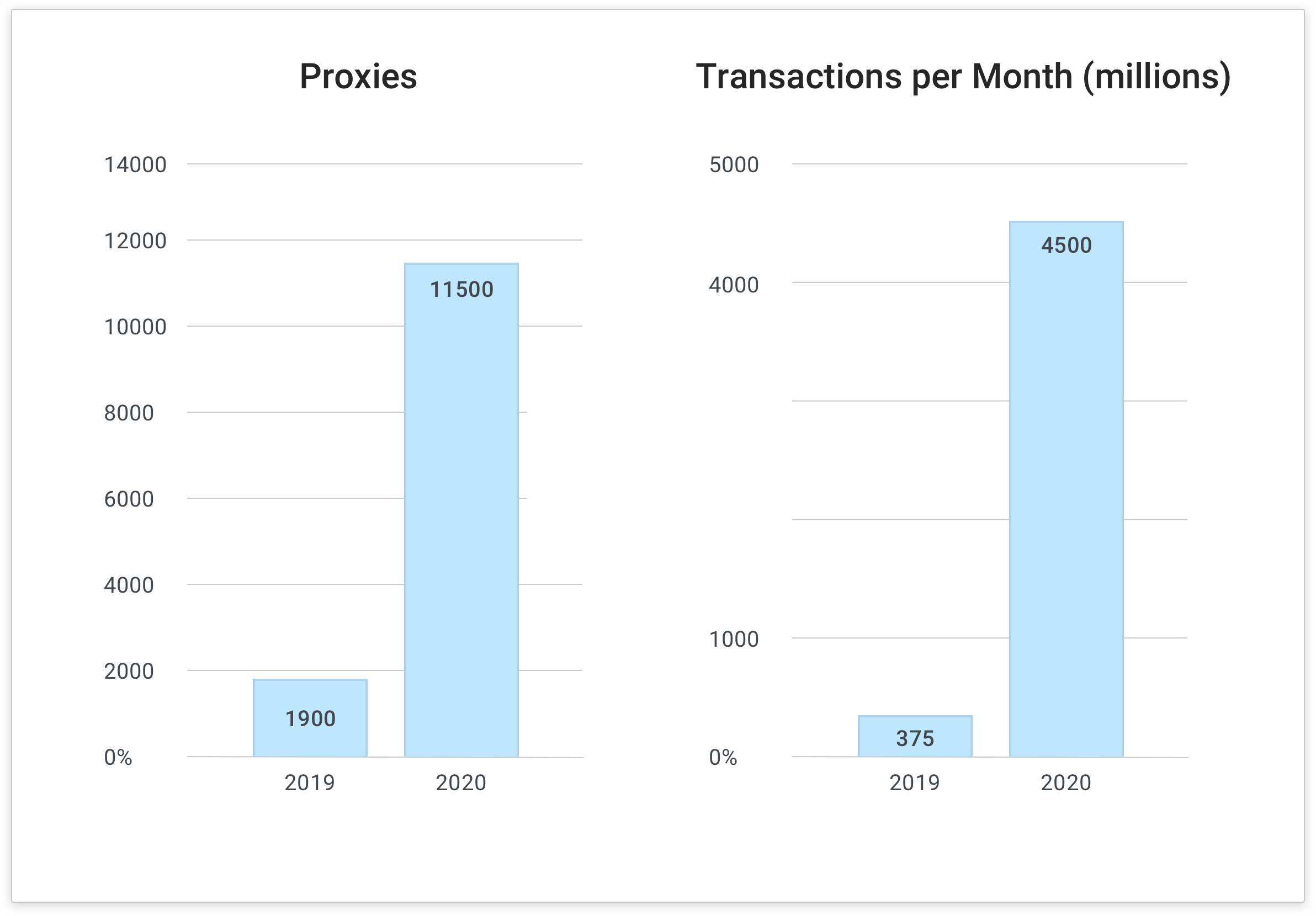
As a result of this incredible growth, capacity concerns grew. Luckily, all we had to do to accommodate the new load is add another pod in each environment. Thanks to the resource-efficient and container-friendly nature of Kong Gateway and the other components in our stack.
Here are the four best practices we discovered for building a thriving API ecosystem with Kong Gateway at its core.
## **1) Creating Advocates Through Expanded Functionality**
Advocates pay huge dividends towards the confidence and adoption of a new platform. You can create advocates by delivering requested features, even if they weren’t on the roadmap. The flexibility of Kong Gateway came in handy to meet those demands. Let's dive into a few of the requests we received.
### ***Centralized Log Sinks***
One of the first requests came from an extensive enterprise effort to add a new centralized log sink. The [API gateway](https://konghq.com/blog/learning-center/what-is-an-api-gateway)API gateway seemed like a useful application as a central point to capture security-related metadata for API transactions.
We asked each API provider and various application stacks to implement the log sinks themselves. In this case, I had the unique opportunity to write a Kong Gateway logging plugin. The plugin would add TLS support to the underlying resty client library I wanted and my Kong Gateway plugin to leverage. This effort exemplified Kong Gateway's strong foundations. NGINX is a well-known, highly performant modern web server. On top of that, you have OpenResty and an assortment of dependencies and underlying libraries at our disposal.
### ***New Client Auth Pattern: Mutual TLS***
We also faced a more formidable challenge. A vendor-client app had no flexibility and needed [API gateway authentication](https://konghq.com/blog/learning-center/api-gateway-authentication)API gateway authentication over mutual TLS (mTLS), but our existing ingress architecture could not support mTLS against the API gateway. That was because the mTLS handshake occurred in front of the API gateway. We had a web application firewall that performed security checks on inbound traffic. This task required adding a fresh rework of our ingress to enable the handshake to happen on the API gateway as well as security payload scanning.
Much like Kong Gateway, we wanted an open source solution to help with threat protection as well. The [ModSecurity Web Application Firewall](https://modsecurity.org)ModSecurity Web Application Firewall (WAF) V3 and [OWASP](https://konghq.com/blog/engineering/owasp-top-10-api-security-2023)OWASP core ruleset were the solution we selected. With these in place, we could manage a set of well-defined attack vector checks directly from our Kong nodes. Establishing these rulesets was a great experience. It opened our team to more of the application security side of engineering. There were some great community members from both the ruleset and WAF teams. The new ingress approach for mTLS also enabled direct visibility to threats and the blocks we faced on API transactions.
### ***Multiple Client Auth Patterns on a Single Proxy***
A long-time ask from customers was how to support multiple off patterns on a given proxy service. In the API gateway space, there are two kinds of authentication patterns we offer to customers:
- - **Programmatic implementations**: Server to server communication
- - **User-based authentication**: A transaction originates from a client in a web browser.
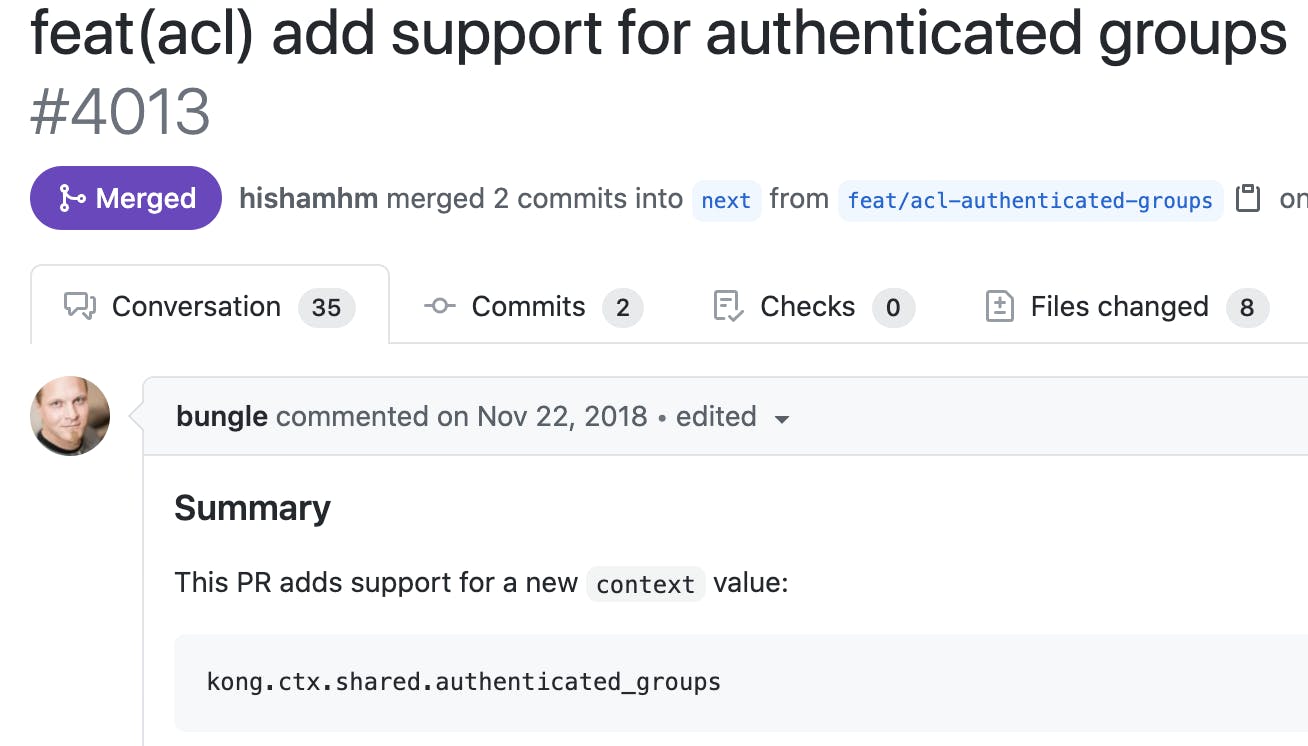
For a long time, Kong Gateway had offered an anonymous user pattern that enabled it to run multiple programmatic authentication patterns against a given proxy. One consequence was needing a Kong Gateway consumer resource in the context with the required ACL groupset. The need for a consumer resource caused problems for a use case many customers wanted, where they desired the proxy to support both programmatic implementations and user-based authentication. Since our user-based authentication came from third-party identity providers, there was no Kong Gateway consumer resource to be had in these interactions. Not long after this realization, [Aapo Talvensaari](https://github.com/bungle)Aapo Talvensaari of the Kong engineering team enabled a programmatic setting for the authenticated groups to the context of the transaction, bypassing the need for a Kong Gateway consumer resource at all. This elegant solution enabled great flexibility to the authentication plugins and patterns that we could support per proxy.
## **2) Pursuing Updates and Upgrades With Open Source**
An essential aspect of running a healthy, large-scale open source platform is constant community involvement, including:
- - Providing feedback to the core development team.
- - Prioritizing platform updates to ensure you're running the latest stable releases in your environments.
One of the critical reasons enterprises are uncomfortable leveraging open source technologies is due to the lack of a contractual vendor support lifeline throughout the upgrade process. So far, after three years and 22+ Kong Gateway upgrades on multiple environments, the process is not at all scary. Almost all of the upgrades went smoothly—all except one, which we’ll touch on shortly.
### ***Optum Kong Gateway 2.1.1 Upgrade***
The Kong Gateway upgrade process is simple and impact-free.
- - Start with the version of Kong Gateway that's currently taking traffic.
- - Fire up a new version of Kong Gateway that's not taking traffic initially, but execute kong migrations up command from this node. The command modifies the database to a state that supports both Kong Gateway versions at runtime.
- - Now you can begin supporting traffic on the newer version of the Kong Gateway node.
- - Once satisfied with the behavior seen on the newer version of your Kong Gateway node, you can execute a kong migrations finish to wrap up a few finalized database adjustments, specifically for full support on the more recent version of Kong Gateway. During this stage, you only want to send traffic to your newer versions of Kong Gateway, and be sure to take the older Kong Gateway conversion instance nodes out of the rotation.
### ***Lessons Learned from the Worst Case Scenario***
Now a situation did occur on the 2.1.0 series, which caused us a bit by surprise. We have three Kong Gateway environments:
- - Developer sandbox environment
- - Customer-facing staging
- - Production environments
The upgrade went off without a problem in our developer sandbox, so we had confidence that staging would face no issues. Once we upgraded staging and the kong migrations up had seemingly completed, we ran a kong migrations finish.
That’s when we got the error that no Lua Kong Gateway programmer likes to see stack traces of—an attempt to index a nil value. The issue was a precursor to the mistake that we started seeing an impact around 10 percent of our stage traffic. We would continue to see this almost until the next full day.
**Handling a Migration Error**
Let’s break down this real-world scenario so you don’t make the same mistake.
We tried to capture and ship logs and screenshots of some of the errors we saw to the [Kong Gateway repo](https://github.com/Kong/kong)Kong Gateway repo. We reached out to [Kong Nation](https://discuss.konghq.com)Kong Nation because it’s the fastest way to get code reviewed by those most familiar with the changes. Posting issues on Kong Nation also helps prevent the rest of the community from facing similar problems.
Step two was to have a robust recovery process. We made our biggest mistakes here. In situations like this, we rely on our database backup and restore process to bail us out. This process was very underutilized and, as it turns out, relatively immature. Our restoration process was incapable of restoring data to a cluster that had already gone through a schema change since the last backup snapshot. That’s precisely what happens during a Kong migration. We ended up fixing this by editing database records in keyspace schemas to complete the Kong migrations manually. Database backup and restoration should always be the go-to first option for faster mediation of a problematic upgrade.
### ***Staying Up to Date Is Important in OSS***
Staying up to date will not only help you leverage the latest features. The product itself also benefits from the use cases and functional testing that goes on from its community. The sooner the community updates, the sooner bugs are found and fixed.
### ***Even after using the Kong Gateway application for over three years, we still get critical enhancements that meet our needs and use cases. ***
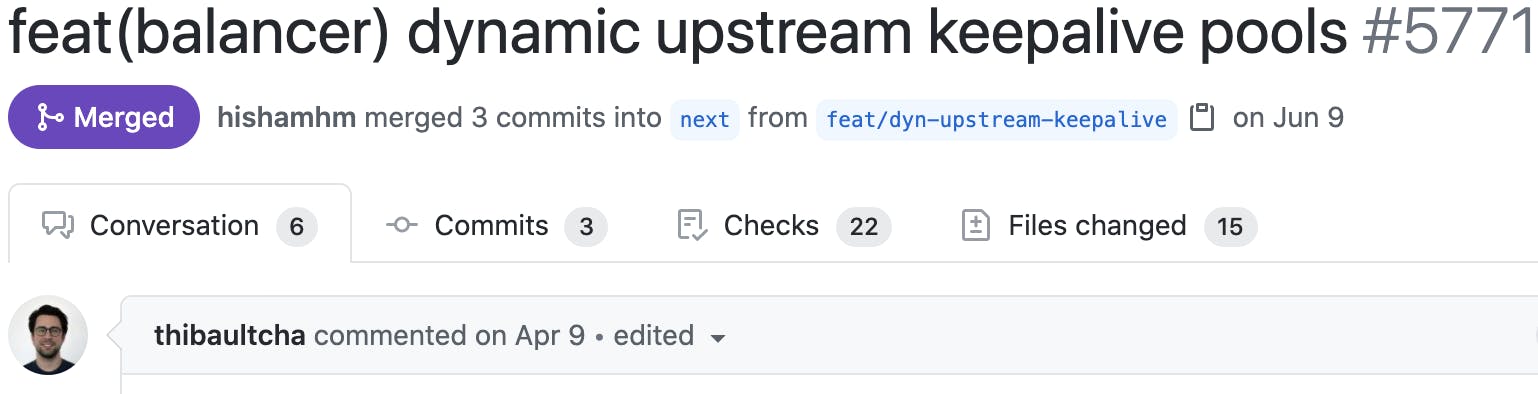
For example, [Thibault Charbonnier](https://github.com/thibaultCha)Thibault Charbonnier's contribution enabled dynamic upstream keepalive pools. His contribution helped us route to certain types of secure APIs that shared the same initial IP address and port for their ingress. We may have been unable to continue leveraging Kong Gateway efficiently without this feature.
Another excellent example was a code contribution by a community member named [Harish](https://github.com/vasuharish)Harish. Throughout 2019 on the 1.0 series, we were hit by an odd bug that constantly called Cassandra to return a null pointer exception when Kong Gateway resources were being rebuilt frequently due to configuration changes.
Neither our team nor the Kong team answered what was causing the problem for close to eight months. It seemed out of nowhere that Harish realized a low-level variable scope problem in the Kong Cassandra paging. Kong released the fix on Kong Gateway 2.0.2.
## **3) Supporting Operations to Empower Customer Success**
Another great way to contribute to customer confidence, promote adoption and create advocates for your platform is to empower customers through practical operational support.
### ***Why Do We Need Ops Support?***
We have a GitOps-based self-service model, detailed event logging and metrics, and mature documentation, covering everything from those topics to the security patterns we support and troubleshooting tips. Why do we need ops support? There are three reasons.
- - **Integration consultations**: Inquiries on topics we may not address in our docs, for example, a consultation on a custom flow or participation in a client security audit.
- - **Troubleshooting**: Sometimes, the customer is going to need help, no matter how many FAQs you write, tips you provide or how complete your logging was
- - **Non-standard proxy management**: Manual work orders to provision rare changes we don’t support through self-service
### ***How Can We Support Ops?***
Now that we’ve touched on why, let’s dive into how by looking at the support flows we manage.
**Integration Consultations**
We’ll start over here with nonstandard proxy management. We have a dedicated intake request for these in the form of a specific Git issue. Clients will submit their issues to make a modification request. Then, the system assigns an engineer from our team to fulfill the request and close the issue. We have three support flows for our integration consultation. We support these consultations through 1) email, 2) weekly office hours and 3) dedicated meetings.
**Troubleshooting**
As the most common reason for engaging support from the API gateway team, we handle these requests based on priority. In the low priority group, we have non-production issues and production build-out issues. We usually respond to troubleshooting requests through email, office hours and our internal chat app. In the high priority category, we have live production issues. We treat these very seriously and triage them in a moderated war room. We have 24/7 on-call paging support for this purpose.
### ***Ops Support Scaling***
So let’s see how our system has coped with the scale. The team's size responsible for providing operational support and API gateway engineering responsibilities has gone from seven to 10. That's an increase of about 40 percent, which is very reasonable considering our 1,000 percent growth in traffic.
## **4) Making a Big-Picture Difference With Governance**
Growing a platform takes more than capacity. We need to think big picture and recognize a unique opportunity for API governance that our growth affords us. Growing an environment takes more than a platform.
It’s the only component common to it all. And this gives us the reach to affect almost the whole API space. With the support of leadership, it gives us more. It provides us with the reach to govern the API space.
### ***Example: Company X***
Let's go through a quick example to show why it's so important to get this right. Company X is a large organization with multiple API development teams. The APIs produced by these teams:
- - Share no consistent design frameworks
- - Have no common quality standards
- - Often employ unorthodox or insufficient security models
- - Have no common means of discovery or documentation
For the unfortunate clients of Company X, this creates a confusing, frustrating, sometimes dangerous and often exhausting integration process. Nobody wants to do business with Company X. This is because Company X does not have an effective API governance process.
### ***Guidelines for Guidelines***
So let’s talk about how to do it right. Good governance starts with thoughtful guidelines. These are what's going to make or break your attempt at API governance.
- - Enforce governance on both the technical product and the design process.
- - Keep your rules current and useful. A great way to do that is to document them visibly and open them to contributions.
- - Give specific and detailed instructions.
- - Don't be afraid to have a lot of guidelines if they’re all valuable.
And a splendid example of a fully open source ruleset and one on which we based much of our process are the eCommerce company [Zalando](https://opensource.zalando.com/restful-api-guidelines)Zalando's rules. I recommend you check it out if you’re looking to design a ruleset for yourself.Optum has 131 rules within its API governance process. We divided the rules into 12 categories. I'm not going to list everything out here, but I would encourage you to watch our [2020 Kong Summit presentation](https://www.youtube.com/watch?v=O7tgbweOeG8)2020 Kong Summit presentation for more details.

### ***How to Enforce Governance***
You should make the process easy to follow and mandatory. We have an automated governance process. It's a GitOps-based, spec-driven model where the open API spec is the key to start governance on a particular API. It's linked with our provisioning for enforcement. If your API has not gone through governance, it hasn't been certified. That means we cannot allow you to create a production proxy on Kong and Optum. Our automated governance process also links with our documentation and discovery hubs. From start to finish, the system can certify APIs in minutes.
### ***Exceptions***
It might be tempting to say that we shouldn’t allow exceptions. But failing to support an exception process is counterproductive. It forces teams to circumnavigate the governance process to meet their business requirements.
Our exception process is simple but not automated. We don't want to get used to the idea of making exceptions. Plus, having that manual interaction could prove to be a teaching moment on why we need these exceptions in the first place.
For the exceptions to be valuable and to work long term, we need to have accountability baked into this process. All our exceptions are associated with a specific person by name. We have a particular remediation plan and date. And to give that little extra bit of administrative enforcement, we also loop in the VP of the API development team requesting the exception for their acknowledgment and approval.
Funny as it may be, we do have exceptions for our exceptions. These are for security. We will not compromise here for any reason. All APIs exposed through the company will have world-class, industry-level security. Any other deadline can take a backseat in exchange for this benefit.
## **API Gateway Scale Goes Beyond Capacity**
To recap, Kong Gateway made it easy to add another pod in each environment to accommodate our increasing traffic. But we couldn't stop there when scaling our API ecosystem. We also:
- - Remained flexible so we could deliver useful features that would delight our customers
- - Kept our Kong Gateway version up to date
- - Empowered our customers with adequate operational support
- - Established API governance from which our whole organization will benefit and thrive






