Effectively, we have halved the token count; you can control the level of compression or target token count. Our testing has shown that this approach can achieve up to 5x cost reduction, while keeping 80% of the intended semantic meaning of the original prompt.
Take a look at the [docs for more examples](https://developer.konghq.com/how-to/compress-llm-prompts)docs for more examples.
In real-world usage, prompts are much larger and are made even more so by automatic context injection — whether that be system prompts or i[njecting Retrieval Augmented Generation (RAG) context](https://konghq.com/blog/engineering/build-your-own-internal-rag-agent)njecting Retrieval Augmented Generation (RAG) context. This additional context can also be compressed. In fact, our testing has shown that compressing the context while retaining the original prompt fidelity can provide an optimal balance between cost reduction and intent retention.
This complements other cost-saving measures already available in Kong, such as Semantic Caching, which avoids hitting the LLM service when a similar request has already been answered, and AI Rate Limiting, which can set time-based token or cost limits per application, team, or user.
## Introducing AWS Bedrock Guardrails support
It is well understood that generative AI applications can sometimes produce unpredictable outputs – confidence in applications can quickly be eroded by a few missteps. You need to be able to keep your AI-driven applications “on topic”, block profanity or other undesirable language, redact personally identifiable information, and reduce hallucinations. You need guardrails.
Today, with Kong AI Gateway, you can already implement policies that can redact PII data with our built-in [PII Sanitizer](https://docs.konghq.com/hub/kong-inc/ai-sanitizer/)PII Sanitizer and [Semantic Prompt Guard](https://docs.konghq.com/hub/kong-inc/ai-semantic-prompt-guard/)Semantic Prompt Guard plugins. We also support policies that enable you to use [Azure AI Content Safety](https://docs.konghq.com/hub/kong-inc/ai-azure-content-safety/)Azure AI Content Safety to reach out to Azure’s managed guardrails service.
Today, we're announcing support for[ AWS Bedrock Guardrails](https://developer.konghq.com/plugins/ai-aws-guardrails/) AWS Bedrock Guardrails to help safeguard your AI applications from a wide range of both malicious and unintended consequences. You can find [more examples in the docs](https://developer.konghq.com/how-to/use-ai-aws-guardrails-plugin)more examples in the docs.
As a product owner with Kong AI Gateway, you can continue to monitor applications and provide incremental improvements in quality, and react immediately by adjusting policies without any changes to your application code. Kong AI Gateway helps you keep risks in check and increase confidence in the rollout of AI-driven applications and innovation.
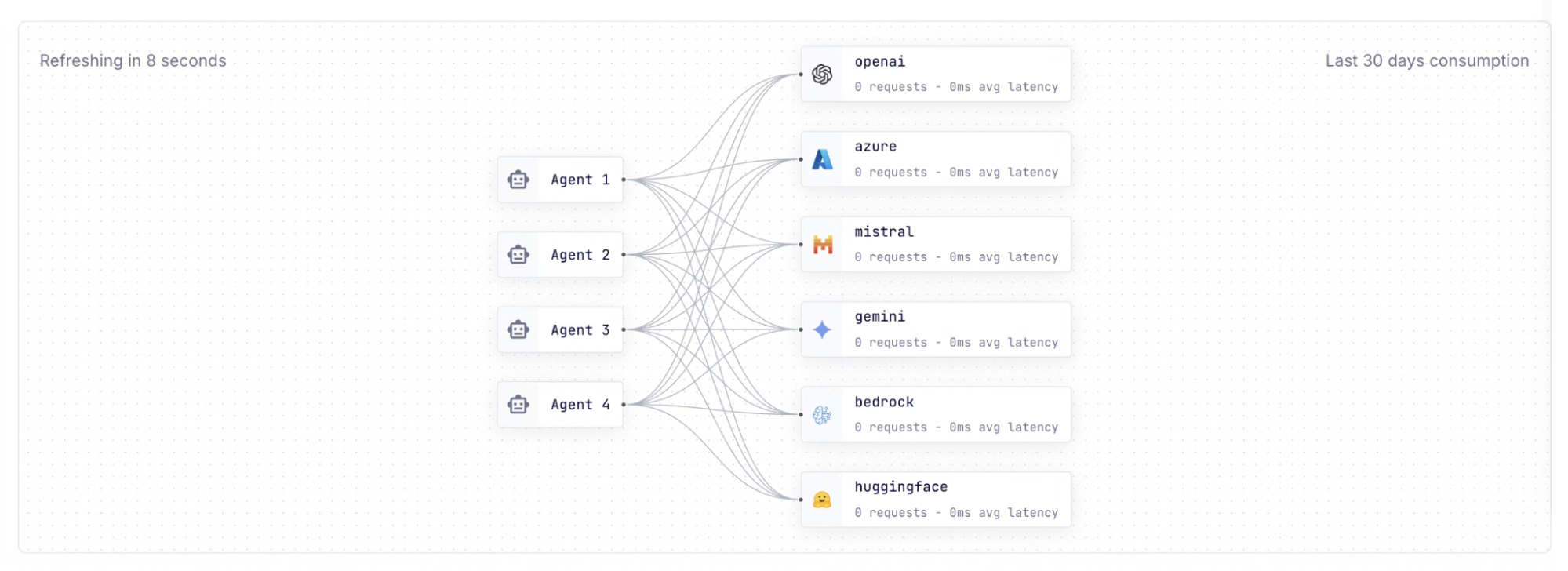
## Visualize your AI traffic with the new AI Manager
We also recently introduced a new AI Manager in Konnect, enabling you to easily expose LLMs for consumption by your AI agents, and additionally govern, secure, and observe LLM traffic using a brand-new user interface straight from your browser.
With AI Manager you can:
- - **Manage AI policies via Konnect**: Govern, secure, accelerate, and observe AI traffic in a self-managed — or fully managed — AI infrastructure that's easy to deploy.
- - **Curate your LLM catalog**: See what LLMs are available for consumption by AI agents and applications, with custom tiers of access and governance controls.
- - **Visualize the agentic map**: Observe at any given time what agents are consuming the LLMs you've decided to expose to the organization.
- - **Observe LLM analytics**: Measure token, cost, and request consumption with custom dashboards and insights for fine-grained understanding of your AI traffic.