Distributed architectures have become an integral part of modern digital landscape. With the proliferation of cloud computing, big data, and highly available systems, traditional monolithic architectures have given way to more distributed, scalable, and resilient designs.
In this blog, we look at what makes an application distributed and how distributed applications work to bring about high availability, scalability, and resilience.
## What is a distributed application?
A distributed application is a collection of computer programs spread across multiple computational nodes. Each node is a separate physical device or software process but works towards a shared objective. This setup is also known as distributed computing systems.
An application running on one single computer represents a single point of failure — if that computer fails, the application becomes unavailable. Distributed applications are often contrasted with monolithic applications.
A monolithic app can be harder to scale as the various components can’t be scaled independently. They can also become a drag on developer velocity as they grow because more developers need to work on a shared codebase that doesn’t necessarily have well-defined boundaries. This leads to slower updates and more delicate upgrades.
When splitting an application into different pieces and running them in many places, the overall system can tolerate more failures. It also allows an application to take advantage of scaling features not available to a single application instance, namely the ability to scale horizontally. This does, however, come at a cost: increased complexity and operational overhead — you’re now running lots of application components instead of one big application.
### How do distributed apps work?
In distributed computing a single problem is divided up and each part is processed by a component. Distributed components running on all the machines in the computer network constitute the application.
For example, distributed computing can encrypt large volumes of data; solve physics and chemical equations with many variables; and render high-quality, three-dimensional video animation. Distributed systems, distributed programming, and distributed algorithms are some other terms that all refer to distributed computing.
Distributed computing works by computers passing messages to each other within the distributed systems architecture. Communication protocols or rules create a dependency between the components of the distributed system. This interdependence is called coupling, and there are two main types of coupling.
#### Loose coupling
In loose coupling, components are weakly connected so that changes to one component do not affect the other. For example, client and server computers can be loosely coupled by time. Messages from the client are added to a server queue, and the client can continue to perform other functions until the server responds to its message.
#### Tight coupling
High-performing distributed systems often use tight coupling. Fast local area networks typically connect several computers, which creates a cluster. In cluster computing, each computer is set to perform the same task. Central control systems, called clustering middleware, control and schedule the tasks and coordinate communication between the different computers.
## Different types of distributed application models
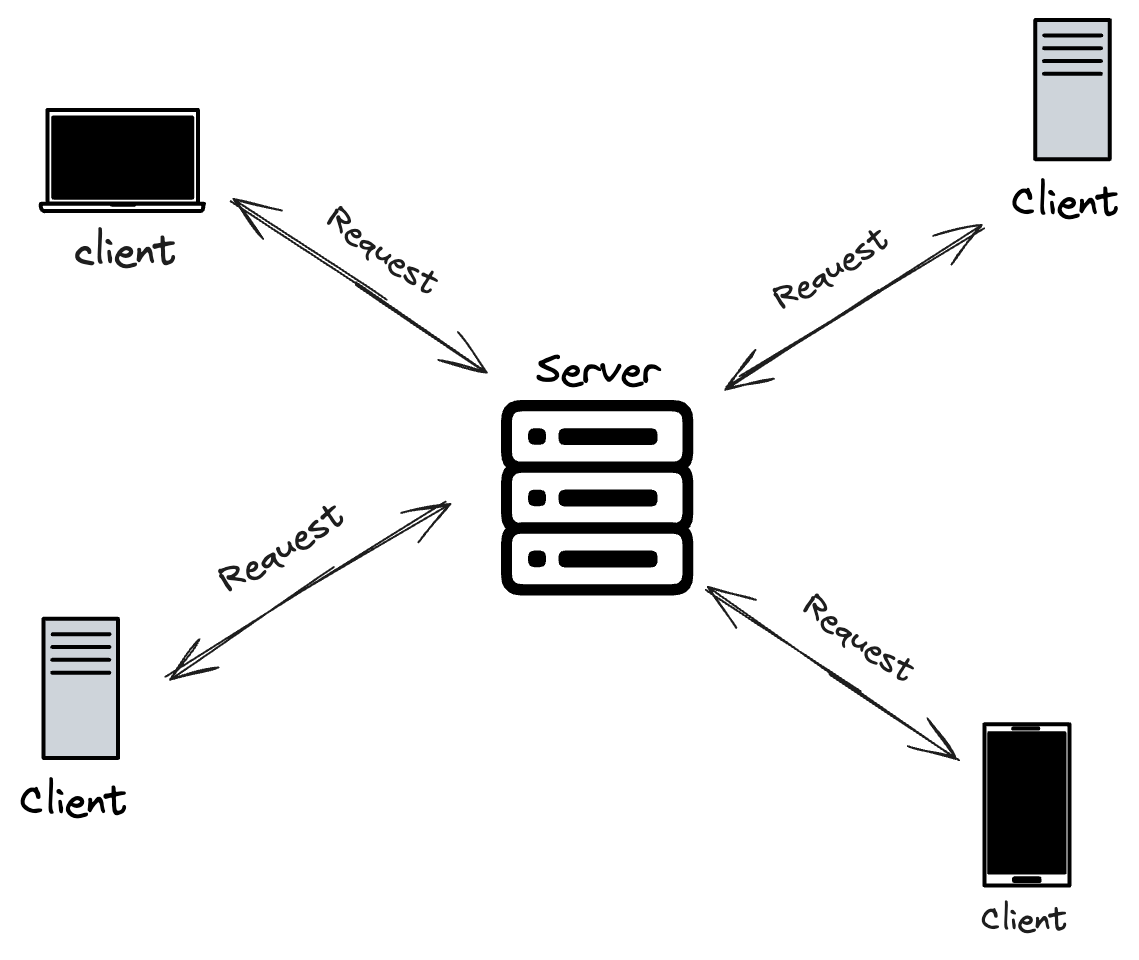
#### Client-server architecture
This model considers the existence of a server with large computational capabilities. This server, in turn, is the entity responsible for receiving requests and providing services for several users. The functions are separated into two categories: clients and servers.
Clients have limited information and processing ability. Instead, they make requests to the servers, which manage most of the data and other resources.
Server computers synchronize and manage access to resources. They respond to client requests with data or status information.
This type of architecture facilitates remote access to data sources and business logic and enables a thin-client architecture and shared access to resources.