# Deploying With Confidence Using Kong Gateway and Spinnaker
Ashwin Sadeep
Change is the primary cause of service reliability issues for agile engineering teams. In this post, I’ll cover how you can limit the impact of a buggy change, making it past your quality gates with Kong Gateway and Spinnaker for canary deployment.
### *"What is the primary cause of service reliability issues that we see in Azure, other than small but common hardware failures? ****Change****." *
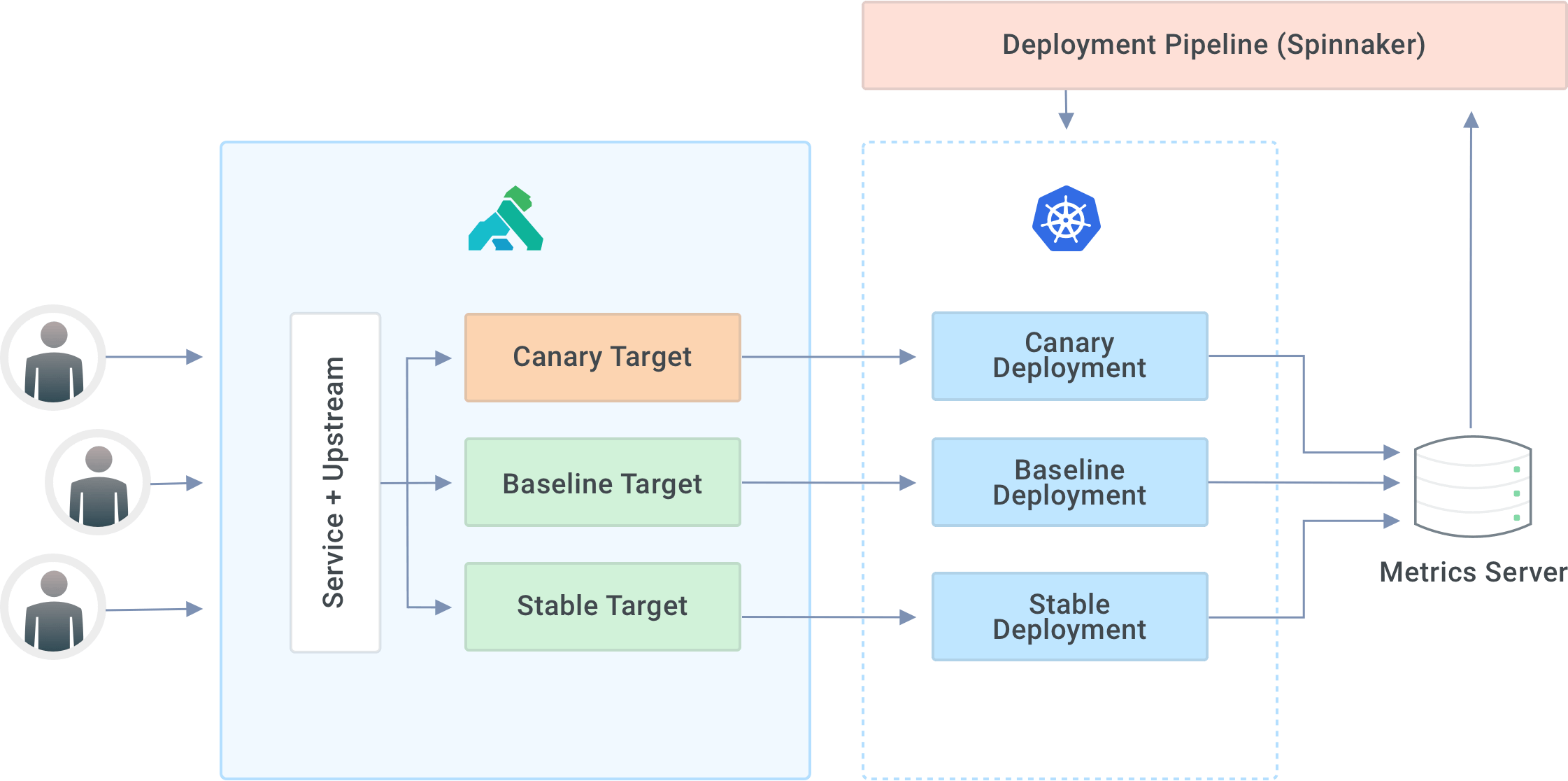
Canary deployment is a technique by which a new version of your software is only visible to a small subset of users—a canary cohort. It deploys the latest version of the software alongside the current stable version. It also splits traffic across these deployments. During a deployment, the key performance indicators—a combination of business and engineering metrics—are monitored across the system on both the canary and stable deployments.
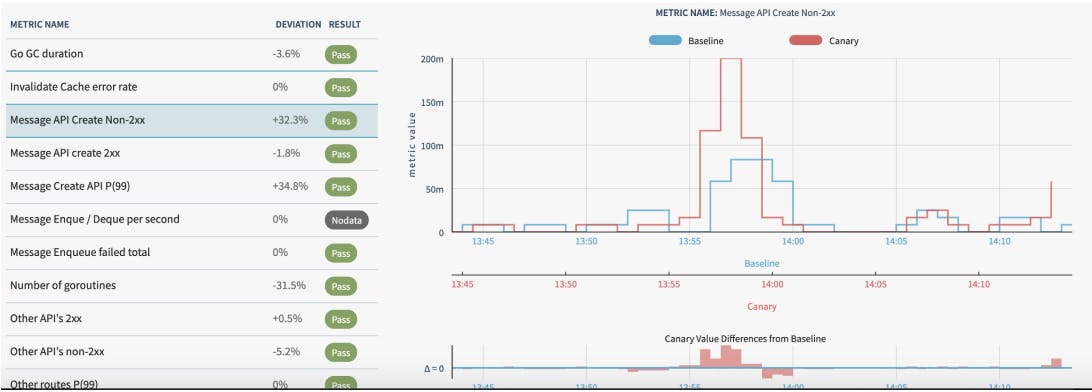
Proceed once you’ve aligned on the metrics, and the deployment is safe. If you see any anomalies between canary and stable, then roll back the canary traffic so that the service can recover.
When we deploy the v2 version of an upstream service, the pipeline will deploy the v2 version to canary and the v1 version to baseline. The short-lived baseline deployment ensures that your metrics will be free of any effects caused by a long-running process - for example, a memory leak that skews memory usage metrics.
For example, we can configure it to deploy the canary stage. Then, the Kayenta configuration can define the analysis of error-rate and latency metrics. If the analysis fails, we can configure the pipeline to terminate traffic to canary targets and raise an alert.
With the [Kong Admin API](https://docs.konghq.com/gateway-oss/2.4.x/admin-api)Kong Admin API, terminating traffic to canary is as simple as a DELETE request to remove the corresponding target. Once you DELETE a target, traffic will stop getting routed there. Instead, traffic will be distributed among the other available targets—baseline and stable in our case.
Kayenta dashboard of a passing canary stage
## **Progressive Deployments Using Kong Gateway**
In practice, deployment pipelines tend to be a bit more nuanced. For instance, we use Kong’s Admin API extensively to do progressive deployments—traffic on canary will start at 2.5%. It will gradually ramp up to 10% over time while concurrently performing canary analysis. With Kong’s Admin API, we can identify functional issues and performance regressions.
- Static: You can specify the canary split in percentage, and Kong will route the traffic based on this percentage. You can do this by setting conf.percentage.
- Progressive: You can specify a duration during which traffic will be gradually ramped up on the new deployment. You can do this by setting conf.duration.
The plugin can also schedule a canary release at a specific time and control traffic split based on the ACL groups. For example, you might want to ensure that a particular customer’s traffic never goes to the canary deployment. You can do this by configuring conf.groups and setting conf.hash as deny.
## **Granular Control Over Traffic Split **
Our choice of using Kong as the API gateway has paid off here. As mentioned previously, Kong Gateway allows us to specify traffic split to a high degree of precision. More importantly, it also handles the reload of the underlying OpenResty workers behind the scenes. It acts as a REST API call from our Spinnaker pipeline to re-route traffic between stable and canary deployments.
## **Intelligent Load Balancing **
Kong Gateway also gives us flexibility with routing based on the authenticated user since we handle authentication at the API gateway itself. This allows us to specify our routing rules such that the traffic from a particular user will always go to a deterministic target. It uses consistent-hashing to distribute your traffic across upstreams based on the hashing field supplied in config. As a result, this comes with the usual [caveats](https://docs.konghq.com/gateway-oss/2.3.x/loadbalancing/#balancing-caveats)caveats, and you need to ensure that the choice of hash key should have sufficient cardinality to avoid hotspots.
We can configure the upstream to hash_on different attributes of the request - headers, cookie, IP or consumer. In the context of Kong Gateway, a consumer has a one-to-one mapping to users. As long as we have an authentication plugin configured, Kong Gateway will resolve the consumer for every request based on the Authorization header and route traffic based on the authenticated user.
## **Kong Gateway's Prometheus Plugin for Additional Instrumentation **
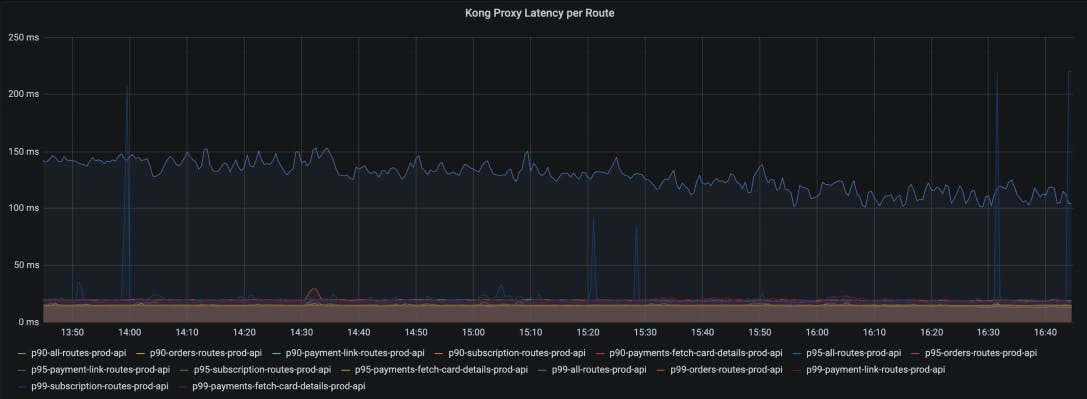
Kong Gateway comes bundled with a robust [Prometheus plugin](https://docs.konghq.com/hub/kong-inc/prometheus)Prometheus plugin implementation which exposes metrics on status codes and latency histograms at a service and route level. This allows us to configure our canary analysis stage to look at P99 latencies and the rate of HTTP 5XX at the gateway level.
Since the plugin exposes metrics labeled by service and route, we can have more granular canary stages to evaluate metrics for specific routes over and above the analysis at a service level.
curl -X POST http://<admin-hostname>:8001/plugins/ --data "name=prometheus"
Infrastructure as code is a core component of all modern SRE team's day-to-day work. There are plenty of options available, but the one that I'm most excited about is Pulumi . Instead of writing a domain-specific language (DSL) to configure your in
Michael Heap
# Beyond Static Routing: Modernizing API Logic with Conditional Policy Execution
Imagine you have a single Service, order-api . You want to apply a strict rate limit to most traffic, but you want to bypass that limit—or apply a different one—if the request contains a specific X-App-Priority: High header. Previously, you had t
How OAuth 2.0 Token Exchange Reshapes Trust Between Services — and Why the API Gateway Is Exactly the Right Place to Enforce It
Modern applications don’t run as a single monolithic. They are composed of services — frontend APIs, backend microservi
Veena Rajarathna
# Practical Strategies to Monetize AI APIs in Production
Traditional APIs are, in a word, predictable. You know what you're getting: Compute costs that don't surprise you Traffic patterns that behave themselves Clean, well-defined request and response cycles AI APIs, especially anything that runs on LLMs
Deepanshu Pandey
# Kong Konnect EKS Marketplace Add-on for Kong Gateway Data Planes
Today, we’re excited to release the Kong Konnect EKS Marketplace add-on as a means to deploy your Kong Gateway dataplanes in AWS. The add-ons are a step forward in providing fully managed Kubernetes clusters. It is here to simplify the post-procurem
In the Kubernetes world, the Ingress API has been the longstanding staple for getting access to your Services from outside your cluster network. Ingress has served us well over the years and can be found present in several dozen different implementa
Modern software design relies heavily on distributed systems architecture, requiring all APIs to be robust and secure. GraphQL is no exception and is commonly served over HTTP, subjecting it to the same management concerns as any REST-based API. In
Infrastructure as code is a core component of all modern SRE team's day-to-day work. There are plenty of options available, but the one that I'm most excited about is Pulumi . Instead of writing a domain-specific language (DSL) to configure your in
Michael Heap
# Beyond Static Routing: Modernizing API Logic with Conditional Policy Execution
Imagine you have a single Service, order-api . You want to apply a strict rate limit to most traffic, but you want to bypass that limit—or apply a different one—if the request contains a specific X-App-Priority: High header. Previously, you had t
How OAuth 2.0 Token Exchange Reshapes Trust Between Services — and Why the API Gateway Is Exactly the Right Place to Enforce It
Modern applications don’t run as a single monolithic. They are composed of services — frontend APIs, backend microservi
Veena Rajarathna
# Practical Strategies to Monetize AI APIs in Production
Traditional APIs are, in a word, predictable. You know what you're getting: Compute costs that don't surprise you Traffic patterns that behave themselves Clean, well-defined request and response cycles AI APIs, especially anything that runs on LLMs
Deepanshu Pandey
# Kong Konnect EKS Marketplace Add-on for Kong Gateway Data Planes
Today, we’re excited to release the Kong Konnect EKS Marketplace add-on as a means to deploy your Kong Gateway dataplanes in AWS. The add-ons are a step forward in providing fully managed Kubernetes clusters. It is here to simplify the post-procurem
In the Kubernetes world, the Ingress API has been the longstanding staple for getting access to your Services from outside your cluster network. Ingress has served us well over the years and can be found present in several dozen different implementa
Modern software design relies heavily on distributed systems architecture, requiring all APIs to be robust and secure. GraphQL is no exception and is commonly served over HTTP, subjecting it to the same management concerns as any REST-based API. In
Infrastructure as code is a core component of all modern SRE team's day-to-day work. There are plenty of options available, but the one that I'm most excited about is Pulumi . Instead of writing a domain-specific language (DSL) to configure your in
Michael Heap
# Beyond Static Routing: Modernizing API Logic with Conditional Policy Execution
Imagine you have a single Service, order-api . You want to apply a strict rate limit to most traffic, but you want to bypass that limit—or apply a different one—if the request contains a specific X-App-Priority: High header. Previously, you had t
How OAuth 2.0 Token Exchange Reshapes Trust Between Services — and Why the API Gateway Is Exactly the Right Place to Enforce It
Modern applications don’t run as a single monolithic. They are composed of services — frontend APIs, backend microservi
Veena Rajarathna
# Practical Strategies to Monetize AI APIs in Production
Traditional APIs are, in a word, predictable. You know what you're getting: Compute costs that don't surprise you Traffic patterns that behave themselves Clean, well-defined request and response cycles AI APIs, especially anything that runs on LLMs
Deepanshu Pandey
# Kong Konnect EKS Marketplace Add-on for Kong Gateway Data Planes
Today, we’re excited to release the Kong Konnect EKS Marketplace add-on as a means to deploy your Kong Gateway dataplanes in AWS. The add-ons are a step forward in providing fully managed Kubernetes clusters. It is here to simplify the post-procurem
In the Kubernetes world, the Ingress API has been the longstanding staple for getting access to your Services from outside your cluster network. Ingress has served us well over the years and can be found present in several dozen different implementa
Modern software design relies heavily on distributed systems architecture, requiring all APIs to be robust and secure. GraphQL is no exception and is commonly served over HTTP, subjecting it to the same management concerns as any REST-based API. In
Rick Spurgeon
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.