**The Shifting Economic Landscape:** The AI token economy in 2026 is evolving, and enterprise leaders must distinguish between low-cost input tokens and high-premium output tokens to maintain profitability.
**Agentic AI Financial Risks:** The transition to agentic AI and multi-step reasoning models creates new financial risks through often invisible looping and recursive token generation that can lead to rapid cost overruns.
**AI Cost Management Solutions:** Kong can help minimize cost exposure and introduce new revenue across your AI connectivity path with:
- - **Kong AI Gateway** for AI cost control — provides a necessary control plane to enforce directional guardrails such as semantic prompt guarding and token-aware rate limiting.
- - **Kong Konnect Metering & Billing **— empowers organizations to monetize AI usage with flexible rate cards that can properly attribute costs for input and output tokens consumption tracked through integrated meters.
In the rapidly expanding Intelligence economy, AI tokens have become a metered utility, much like electricity and oil were the metered tokens of the last century. Unlike traditional software or SaaS, where a machine or user seat typically has a well-understood cost profile and only modest variation in usage, AI-driven systems introduce a fundamentally different cost model. The expense across the AI connectivity path can vary dramatically based on model choice, prompt size, response length, and whether agents are looping or chaining calls together. Compounding the complexity, the direction of the token, meaning input tokens (the prompt you send) and output tokens (the completions the model generates), carries very different economic weights. For enterprise leaders, token generation, usually in the form of output tokens, represents the majority of compute cost and economic risk.
Failure to establish the correct infrastructure for managing, metering, and acting on the directional flow of AI tokens puts organizations at risk of hidden cost overruns. This is because token consumption services often lead to escalating bills that quickly outpace the expected year-over-year decline in token pricing.
From 2020 to 2026, AI token pricing followed a largely downward trajectory, driven by rapid gains in model efficiency, intensifying competition among providers, and economies of scale in cloud infrastructure. Early transformer-based models were expensive to run and priced conservatively, but successive generations steadily reduced per-token costs as inference became more optimized and hardware utilization improved. For early AI adopters, the prevailing assumption was straightforward: operational costs would continue to plummet even as utilization scaled up.
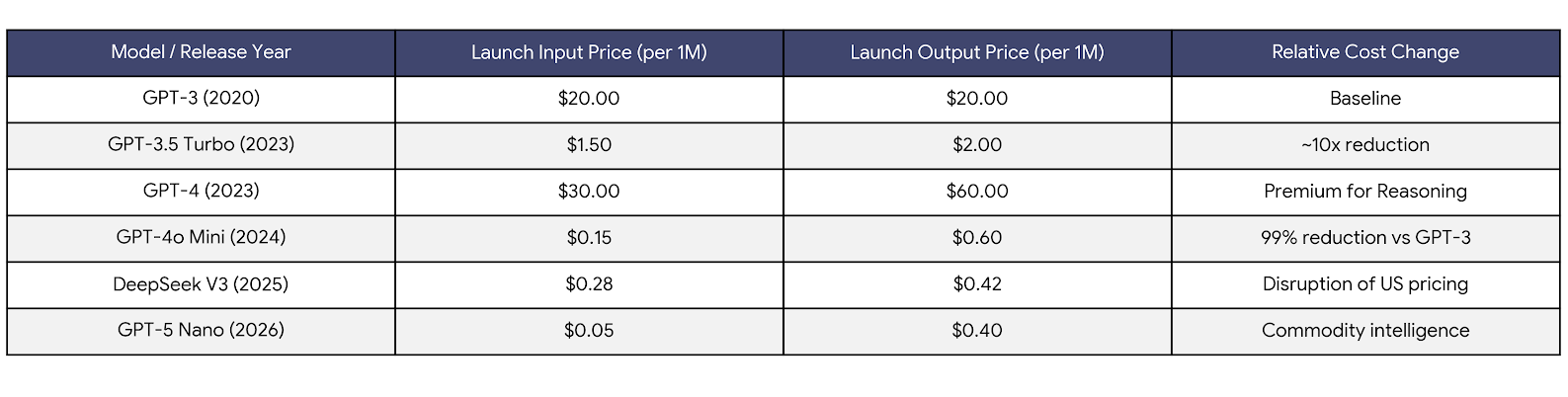
Historical Trajectory of Token Pricing (2020-2026) in Flagship Hosted Models
However, this historical pattern of declining prices isn't a law of nature. In 2026, the market shows clear signs of reversal pressure. Infrastructure costs have spiked due to sustained demand for high-end GPUs and expanded memory requirements, further strained by constrained supply chains, power and cooling demands, and import/export duties. Next-generation models increasingly trade efficiency for capability, providing larger context windows, multimodality, and deeper reasoning — all carry real compute costs. As a result, new state-of-the-art models often launch at premium token prices, reflecting both higher underlying infrastructure expenses and the market's willingness to pay for differentiated performance.
The last six years made one thing crystal clear: while AI costs tend to decline over time, access to new capabilities almost always comes at a premium. Early adopters pay higher prices to use next-generation models and features before efficiencies, optimization, and broader competition bring costs down.
The shift from standard large language models(LLMs) to agentic AI represents the latest and most significant driver of token consumption in the modern enterprise. While a standard non-chat LLM interaction is a single request followed by a response, an agentic workflow is iterative, involving multi-step reasoning, tool execution, and self-correction. This autonomy comes with the ability to rapidly burn through tokens, which comes with real financial impacts.








