[Domain-driven designs](https://martinfowler.com/bliki/DomainDrivenDesign.html)Domain-driven designs are popular in organizations that have complex domain models and wish to organize engineering around them. [REST-based](https://konghq.com/blog/learning-center/what-is-restful-api)REST-based architectures are a common choice for implementing the API entry point into these domains. REST-based solutions are straightforward for the API builder and for API consumers concerned with data from a single API. But what about developers tasked with aggregating information across domains? Developers building end-user websites, mobile apps, and internal dashboards are faced with the difficult task of orchestrating data across these domain APIs.
These developers need access to a wide range of data to build a consistent experience for the end-user. Often these developers resort to anti-patterns, like building hand-crafted "back-end for front-end" (BFF) APIs that do complex domain aggregation. These custom BFF APIs are maintenance burdens as they multiply when clients require different aggregate views of the domain information. BFF APIs are often authored in REST and directly expose clients to custom static specifications which are vulnerable to upstream API changes. What these developers need is a dynamic aggregate API to build their applications on top of.
[GraphQL](https://graphql.org/)GraphQL offers a solution to this problem by providing a flexible query design along with a layer of decoupling between clients and the domains that service their data needs.
In this post, we're going to use a fictitious airline named *KongAir* as our example business use case.
KongAir is a domain-driven technology organization where individual development teams build services and applications focused on their business domains. Teams are free to work in their own languages and technology stacks. APIs are delivered using the REST model, and each service contains an OpenAPI Specification detailing the API behavior. All the source code discussed in this post is available in the public [KongAir](https://github.com/Kong/KongAir)KongAir GitHub repository.
The KongAir *flight-data* team builds APIs that serve public, unsecured data for the airline’s flight routing and schedule. This team builds services in GoLang for its straightforward syntax and high-performance runtime characteristics. The team provides the following services:
The airline's *sales* development team builds services that serve customer-specific needs including personal information and flight booking systems. The sales development team uses NodeJS for its rapid development capabilities and extensive library ecosystem. The team provides these services:
As we learned in the [first part of this series](https://konghq.com/blog/engineering/graphql-from-the-ground-up)first part of this series, GraphQL services start with a schema that defines the queries and types available to clients. The KongAir experience API is coded from the perspective of the end user, with a single query named `me` that returns an object of type `Me`. The `Me` object defines all of the information that can be provided about a user including their personal information and current bookings. When making a query to the GraphQL service, applications will provide a bearer token in the `Authorization` header. This token contains a `username` claim in the token body which will be used to identify the user throughout the KongAir system.
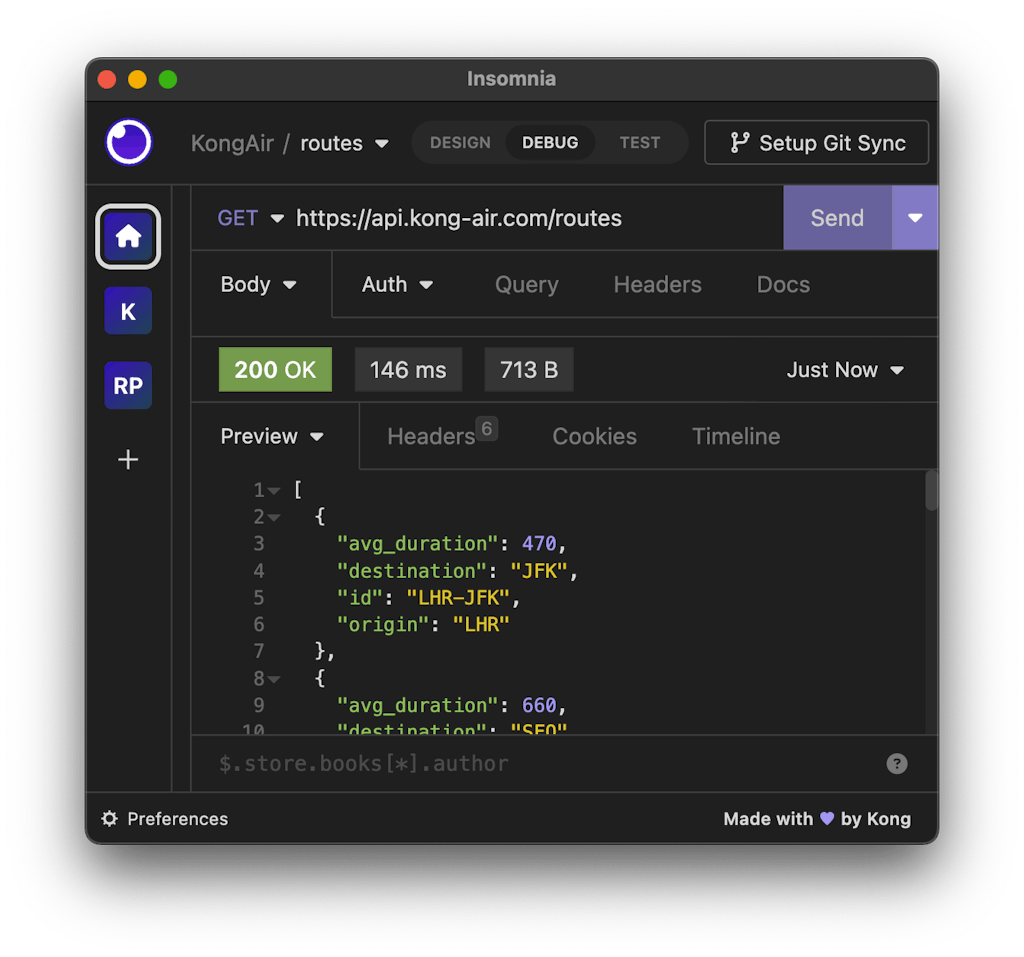
The JavaScript class extends the `RESTDataSource` and includes a configurable `baseURL` value as well as implementation functions for each resource and HTTP verb combination. At runtime the `baseURL` is paired with the path provided in each implementation function argument to construct the full request URL. You can see how the `RoutesAPI` class aligns with the routes service REST paths from the OpenAPI snippet below ([openapi.yaml](https://github.com/Kong/KongAir/blob/main/flight-data/routes/openapi.yaml)openapi.yaml):
Apollo Server needs to know how to populate data for every field in your schema so that it can respond to requests for that data. To accomplish this, it uses resolvers.
A resolver is a function that’s responsible for populating the data for a single field in your schema. It can populate that data in any way you define, such as by fetching data from a back-end database or a third-party API.
A resolver is implemented as a JavaScript object with properties that correspond to the GraphQL schema *types*. The property values are functions that retrieve the relevant data, and as the Apollo SDK fulfills a query request, it traverses the schema and invokes the resolver function for each field. When using data sources as described above, we define a resolver that maps the schema type to the corresponding data sources. Here is what the resolver code looks like for the KongAir `Me` experience API:
The magic in the Apollo resolver SDK is that for any field that does not have a resolver definition, the SDK defines a default resolver for it. In cases where the data source returns an object with property names that matches the schema property names, the server can map these fields automatically.
For example, in the `Me` schema, a field is defined as `username`, which matches the returned field from the Customer Information API exactly allowing the field to be mapped automatically. Resolving data for more complex objects and relationships between them requires additional logic. For example, let's look at how a user’s `Bookings` are returned from the GraphQL service.
A `Booking` contains a `Flight`, but the Bookings API only returns some of the flight information, not the full flight details. `FlightDetails` are provided by the Flights API, and the `Flight` and `FlightDetails` are related using the `Flight.number` field. Similarly, a `Flight` contains a `Route`, but the `Route` information is provided by the Routes API. A `Flight` and a `Route` are linked by the `Flight.route_id` field.
When a request comes into the GraphQL service, the Apollo SDK traverses the resolvers' structure to populate the data, this is called the *resolver chain*. Initially, the SDK will invoke the resolver defined for the specific Query that was invoked, `me` in our example above. From that resolver's return value, the SDK will traverse each field and either invoke a defined resolver function or attempt to use the default resolver as explained earlier. The resolver functions accept [arguments](https://www.apollographql.com/docs/apollo-server/data/resolvers/#resolver-arguments)arguments, the first of which is `parent`, which contains the previous result in resolver in the chain. The `parent` instance is analogous to a parent in an object-oriented data model. This allows us to obtain related information from different APIs using parent / child relationships in the data. In our example, the flight details are returned from the Flights API using the `parent.number` field, which is defined as the `Booking.flight.number` field in the GraphQL schema.
The entry point of the GraphQL service is defined in the [index.js](https://github.com/Kong/KongAir/blob/main/experience/index.js)index.js file. We bring together the schema and the resolvers to configure the Apollo Server. Additionally, the resolvers need access to instances of the data sources. This is accomplished using the Apollo server *context function*, which is provided as an argument to the `startStandaloneServer` function.
...const typeDefs =require('./schema');const resolvers =require('./resolvers');...asyncfunctionstartApolloServer(){const server =newApolloServer({ typeDefs, resolvers });const{ url }=awaitstartStandaloneServer(server,{context:async({ req })=>{const{ cache }= server;return{dataSources:{customerAPI:newCustomerAPI( req,{ cache }),bookingsAPI:newBookingsAPI( req,{ cache }),routesAPI:newRoutesAPI({ cache }),flightsAPI:newFlightsAPI({ cache }),},};},});console.log(` 🚀 Server is running
📭 Query at ${url}`);}startApolloServer();
The context function is executed for every incoming GraphQL request, and within this function we define new data source instances. In the cases of the CustomerAPI and BookingsAPI, we also pass in the incoming request object which allows the data sources to forward authorization headers to the upstream API calls.
### Run and query the experience API
We've covered the basics of the experience API design. Let's run the GraphQL service and see it in action.
The server is a NodeJS application and requires `node` and `npm` to be installed and available in the path prior to running. The service has been tested with Node version `17.9.1` and npm version `8.11.0`. You will also require `git` to obtain the source code in the instructions below.
From the terminal, clone the KongAir repository and change into the `experience` directory:
git clone https://github.com/Kong/KongAir.git && \ cd KongAir/experience
The running server reports it's listening endpoint:
> kong-air-experience@0.1.0 start
> node index.js
🚀 Server is running
📭 Query at http://localhost:4000/
Before running GraphQL queries against the server, we have to understand the method the KongAir system uses to verify user identity.
JWTs provide an easy way to transfer identity between services. The domain REST APIs require a JWT with a payload that contains a `username` field which is used to identify API users.
You may wonder why the GraphQL query is sent as a `POST` request. GraphQL query expressions can be complicated nested JSON objects, and it may be simplest to pass them to the server as a JSON formatted body in an HTTP request. Idiomatically, GET requests do not support a request body, so POST is commonly used. However, GraphQL servers should also support accepting a query in a GET request via the query parameter. Here is the same example via GET:
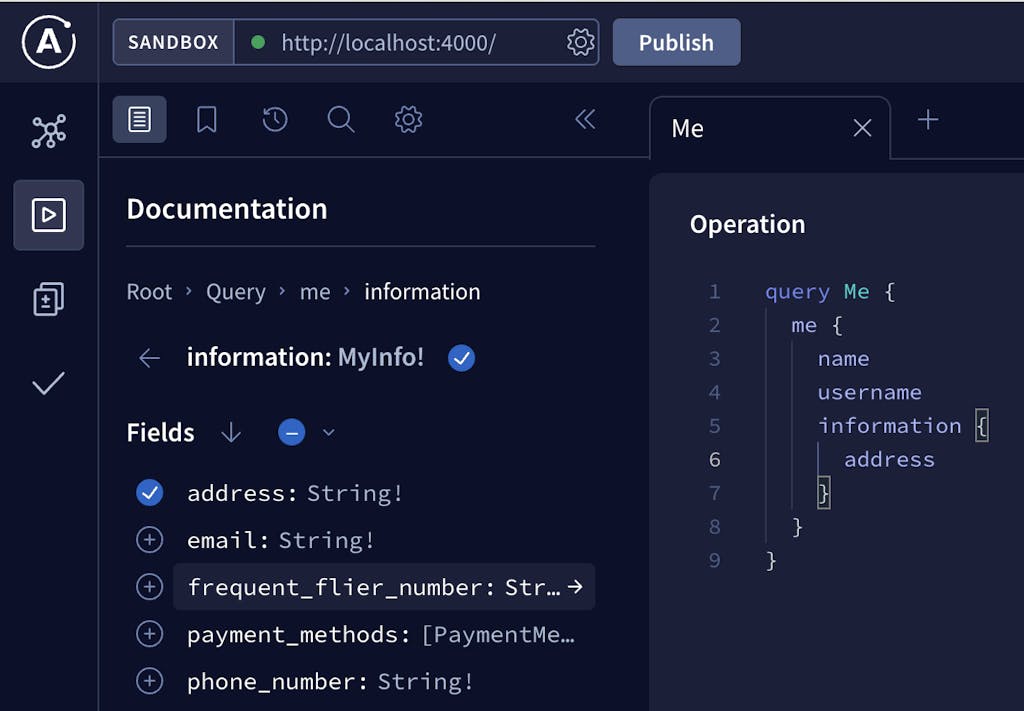
From the perspective of the client, what exactly makes the GraphQL API different from the upstream domain REST APIs? The dynamic nature of the GraphQL query capabilities puts more power in the hands of the client making requests. Imagine KongAir is building a mobile application with a screen that shows the user their personal information including their username, address, and frequent flier number. The following client query provides this information:
curl -s -X POST \
-H 'Accept: application/json' -H 'Content-Type: application/json' \
-H "Authorization: Bearer $DFREESE" http://localhost:4000 \ --data '{"query":"{ me { username information { address frequent_flier_number } } }"}'
And the server responds with these specific fields:
{"data":{"me":{"username":"dfreese","information":{"address":"567 Street St","frequent_flier_number":"FF987abc"}}}}
The same application has a different screen that shows the user their current bookings. This requires a different upstream domain API, but the GraphQL service can compose it together with the customer information for us. We don't have to create a new BFF API; we just construct a different query on the client side. Here is an example request for the user's bookings:
You may find this easier to use than a command line for exploring the capabilities of the GraphQL service. To successfully make requests to the KongAir API, you will need to configure the Sandbox with the bearer tokens. Open the IDE Settings, then Connection Settings and provide the token information in the Shared headers section.
### Summary
GraphQL offers a compelling solution for building dynamic APIs and is particularly useful for clients that present data to end users. These types of experience APIs are beneficial to clients that need to avoid the rigidity of traditional REST-based APIs and GraphQL provides a key abstraction layer towards that goal.
But once you've integrated GraphQL into your API ecosystem, the job isn't complete. GraphQL APIs need management, as all API technologies do. Protecting the API is paramount as you expose it to end-user applications and the full outside world.
Choosing the right API architecture is crucial for building efficient and scalable applications and the two prominent contenders in this arena are GraphQL and REST, each with its unique set of characteristics and benefits. Understanding the similari
Kong
# Insomnia 13: Native Kong Konnect Integration for Real-Time API Testing
Have you ever…. Copied an API spec out of Kong Konnect, or where you manage your APIs, pasted it into your API client, and immediately wondered if it’s the latest version? Sent an email to your platform team with the subject line “ which endpoint sh
Haley Giuliano
# 6 Reasons Why Kong Insomnia Is Developers' Preferred API Client
So, what exactly is Kong Insomnia? Kong Insomnia is your all-in-one platform for designing, testing, debugging, and shipping APIs at speed. Built for developers who need power without bloat, Insomnia helps you move fast whether you’re working solo,
Juhi Singh
# Unpacking Distributed Applications: What Are They? And How Do They Work?
Distributed architectures have become an integral part of modern digital landscape. With the proliferation of cloud computing, big data, and highly available systems, traditional monolithic architectures have given way to more distributed, scalable,
Paul Vergilis
# Day 0 Service Mesh: Simplifying Microservices Management
The acceleration of microservices and containerized workloads has revolutionized software delivery at scale. However, these distributed architectures also introduce significant complexity around networking, security, and observability. As developmen
Here at Kong, we're advocates for architecting your application as a group of microservices . In this design style, individual services are responsible for handling one aspect of your application, and they communicate with other services within you
We looked at service design considerations in the first part of this blog series . In this next part, I'd like to share some best practices for API versioning - a topic that comes up quite often with every customer as it is one of the key concerns
Vikas Vijendra
# GraphQL vs REST: Key Similarities and Differences Explained
Choosing the right API architecture is crucial for building efficient and scalable applications and the two prominent contenders in this arena are GraphQL and REST, each with its unique set of characteristics and benefits. Understanding the similari
Kong
# Insomnia 13: Native Kong Konnect Integration for Real-Time API Testing
Have you ever…. Copied an API spec out of Kong Konnect, or where you manage your APIs, pasted it into your API client, and immediately wondered if it’s the latest version? Sent an email to your platform team with the subject line “ which endpoint sh
Haley Giuliano
# 6 Reasons Why Kong Insomnia Is Developers' Preferred API Client
So, what exactly is Kong Insomnia? Kong Insomnia is your all-in-one platform for designing, testing, debugging, and shipping APIs at speed. Built for developers who need power without bloat, Insomnia helps you move fast whether you’re working solo,
Juhi Singh
# Unpacking Distributed Applications: What Are They? And How Do They Work?
Distributed architectures have become an integral part of modern digital landscape. With the proliferation of cloud computing, big data, and highly available systems, traditional monolithic architectures have given way to more distributed, scalable,
Paul Vergilis
# Day 0 Service Mesh: Simplifying Microservices Management
The acceleration of microservices and containerized workloads has revolutionized software delivery at scale. However, these distributed architectures also introduce significant complexity around networking, security, and observability. As developmen
Here at Kong, we're advocates for architecting your application as a group of microservices . In this design style, individual services are responsible for handling one aspect of your application, and they communicate with other services within you
We looked at service design considerations in the first part of this blog series . In this next part, I'd like to share some best practices for API versioning - a topic that comes up quite often with every customer as it is one of the key concerns
Vikas Vijendra
# GraphQL vs REST: Key Similarities and Differences Explained
Choosing the right API architecture is crucial for building efficient and scalable applications and the two prominent contenders in this arena are GraphQL and REST, each with its unique set of characteristics and benefits. Understanding the similari
Kong
# Insomnia 13: Native Kong Konnect Integration for Real-Time API Testing
Have you ever…. Copied an API spec out of Kong Konnect, or where you manage your APIs, pasted it into your API client, and immediately wondered if it’s the latest version? Sent an email to your platform team with the subject line “ which endpoint sh
Haley Giuliano
# 6 Reasons Why Kong Insomnia Is Developers' Preferred API Client
So, what exactly is Kong Insomnia? Kong Insomnia is your all-in-one platform for designing, testing, debugging, and shipping APIs at speed. Built for developers who need power without bloat, Insomnia helps you move fast whether you’re working solo,
Juhi Singh
# Unpacking Distributed Applications: What Are They? And How Do They Work?
Distributed architectures have become an integral part of modern digital landscape. With the proliferation of cloud computing, big data, and highly available systems, traditional monolithic architectures have given way to more distributed, scalable,
Paul Vergilis
# Day 0 Service Mesh: Simplifying Microservices Management
The acceleration of microservices and containerized workloads has revolutionized software delivery at scale. However, these distributed architectures also introduce significant complexity around networking, security, and observability. As developmen
Here at Kong, we're advocates for architecting your application as a group of microservices . In this design style, individual services are responsible for handling one aspect of your application, and they communicate with other services within you
We looked at service design considerations in the first part of this blog series . In this next part, I'd like to share some best practices for API versioning - a topic that comes up quite often with every customer as it is one of the key concerns
Vikas Vijendra
## Ready to see Kong in action?
Get a personalized walkthrough of Kong's platform tailored to your architecture, use cases, and scale requirements.