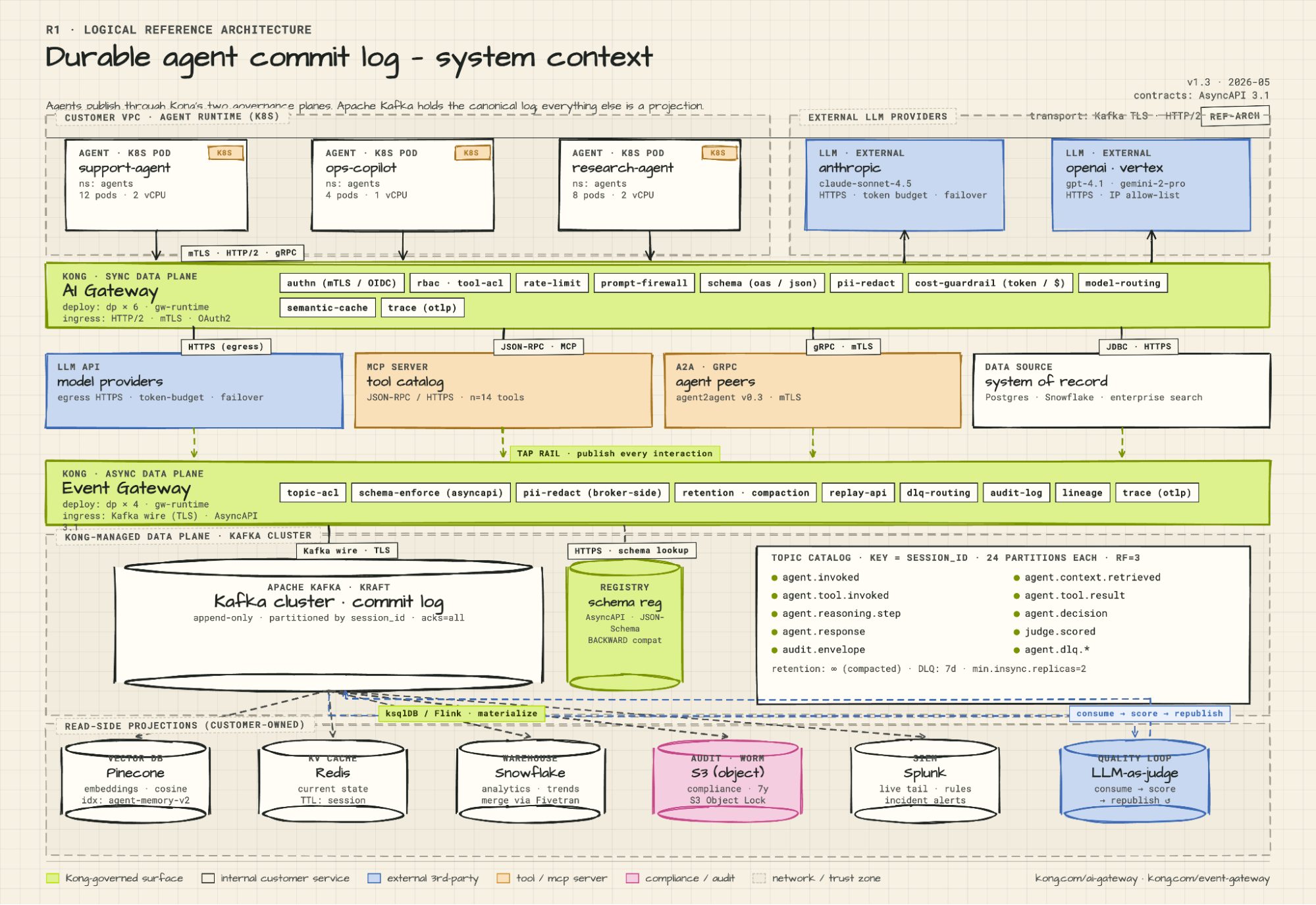
Kafka was designed around the log as a first-class abstraction. Topics retain data indefinitely by default; deletion and compaction are explicit choices you make, not the default behavior. This is the right default for an agent memory layer. The log accumulates. You keep it. You make intentional decisions about what to expire and when.
Tiered storage — available in Apache Kafka 3.6 and above, and in managed offerings like Confluent, Redpanda, and WarpStream — makes years of retention economically practical by moving older log segments to cheap object storage while keeping them queryable. For an agentic system that might need to replay interactions from a year ago to support an audit or a training run, tiered storage means the economics of retention are a configuration decision, not an infrastructure crisis.
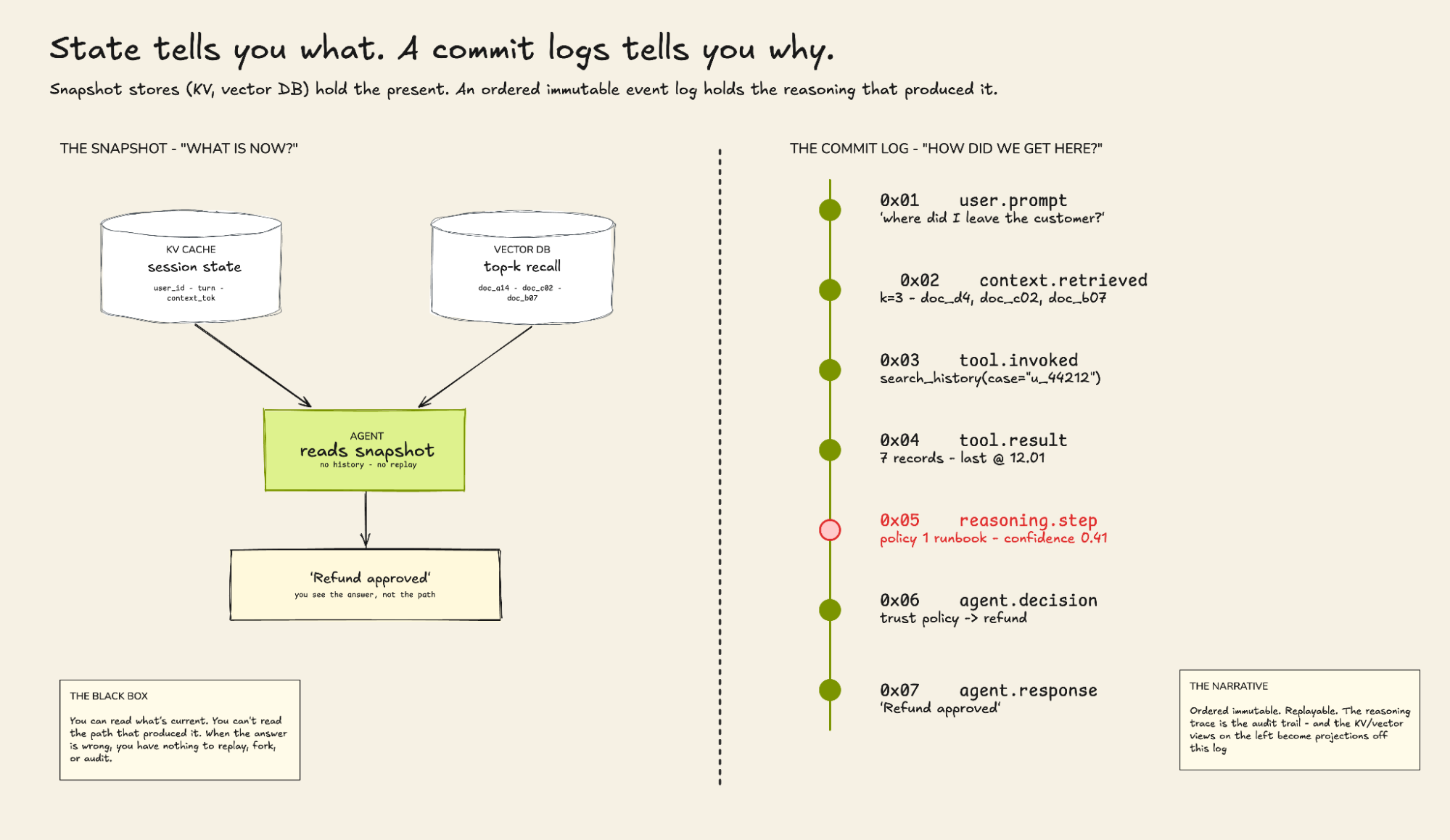
Kafka's ordering model is the cleanest implementation of what an event log needs to be. Within a partition, events are strictly ordered by offset — a monotonically increasing integer assigned at write time. An agent action at offset 4,283,019 happened after the action at offset 4,283,018. You can point to a specific moment in the agent's history with a single number. You can replay from that exact moment. You can fork from that exact moment. You can give an auditor a precise, verifiable reference to the agent's state at a specific point in a session. This sounds simple. It's not a given. Several streaming systems make ordering guarantees that are weaker, more conditional, or harder to operationalize. Kafka makes the strong guarantee, and the surrounding tooling assumes it.
The `session_id`-to-partition mapping is the practical expression of this guarantee in an agentic context. When you partition by `hash(session_id)`, every event from a single agent session — every tool call, every reasoning step, every decision, every model response — lands in the same partition in the order it occurred. The causal chain of an agent's reasoning is preserved at the storage layer, before any consumer touches it, without any special logic in the agent itself.
Schema governance in the Kafka ecosystem is mature in a way that matters. A decade of production experience with schema registries (Confluent Schema Registry, Apicurio), compatibility rules (`BACKWARD`, `FORWARD`, `FULL`), and governance workflows has produced tooling and operational practices that work reliably at scale. AsyncAPI 3.1 — the specification for event-driven APIs, roughly the equivalent of OpenAPI for async communication — has strong Kafka support and is the right contract layer for agentic event topics. When you enforce `BACKWARD` compatibility, a new version of the `agent.tool.invoked` schema doesn't break your compliance consumer or your SIEM connector, because it can still be read by systems built against the previous version. Schema drift silently destroys the value of a long-lived action log. Kafka's governance ecosystem exists specifically to prevent it.
The downstream ecosystem argument is the one that's easiest to underestimate. When you choose Kafka as your memory backbone, you're not just choosing a protocol for storing events. You're choosing access to Kafka Connect with hundreds of pre-built source and sink connectors, Flink for stateful stream processing, ksqlDB (a streaming SQL engine) for continuous evaluation and aggregation, and Spark Structured Streaming for large-scale analytics. Every downstream system your agentic stack needs to feed — Pinecone for vector search, Snowflake for analytics, Splunk for security monitoring, S3 for compliance archival — already has a battle-tested, production-grade Kafka connector. You configure these integrations. You don't build them. That is a meaningful difference in the pace at which you can stand up a complete agentic memory architecture.