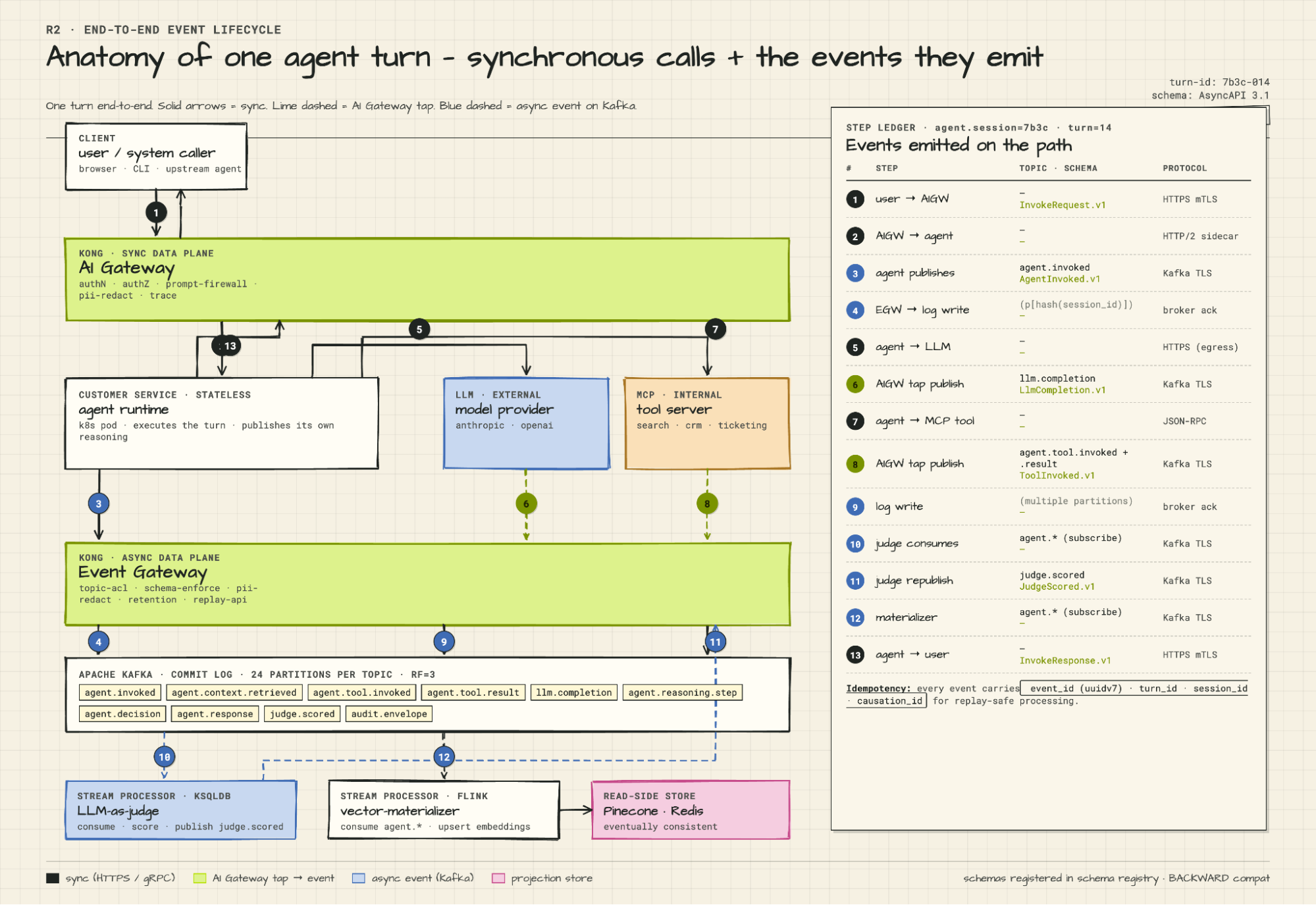
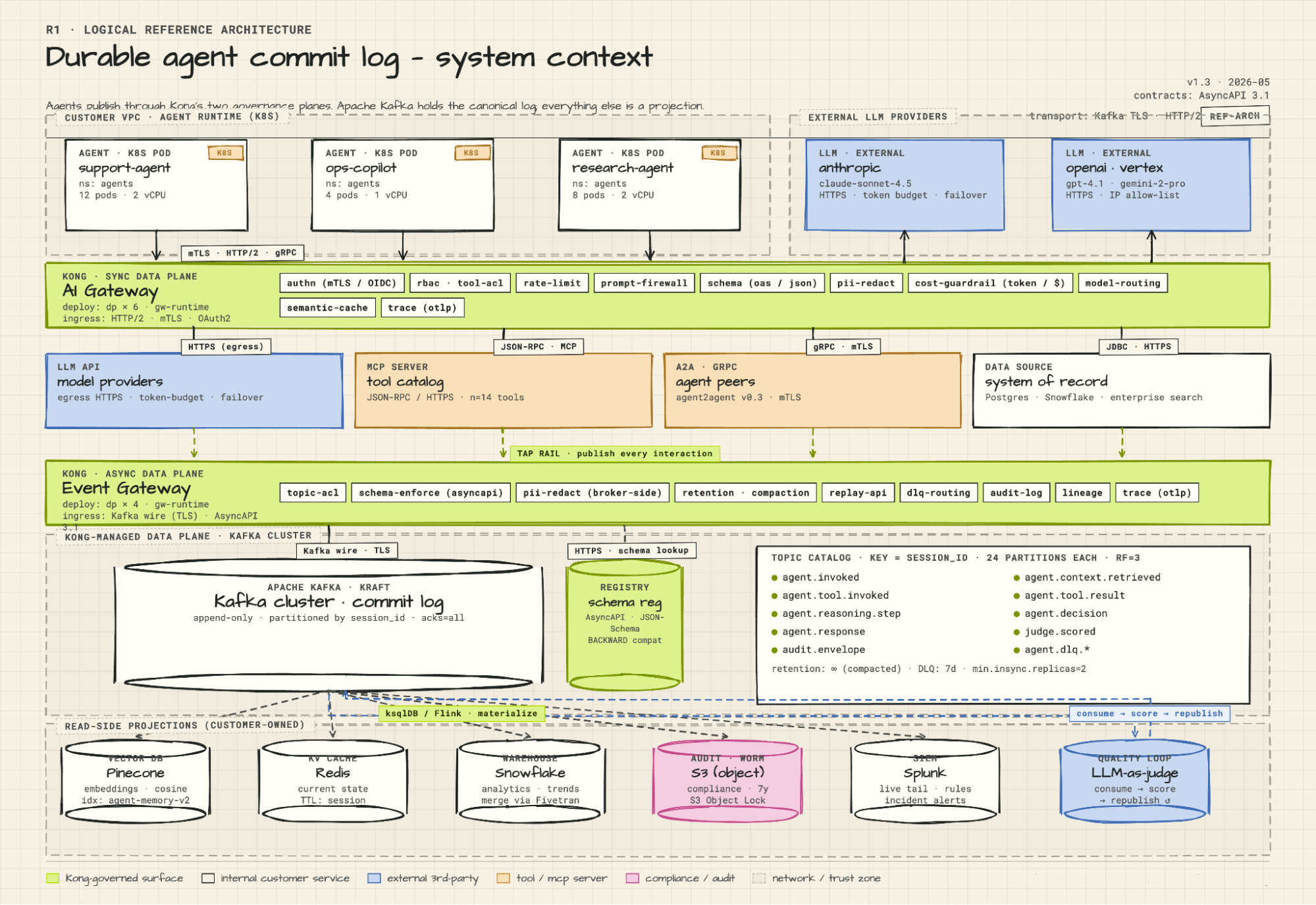
**Steps 1–2: Request ingress.**
The client — a browser, a CLI, or an upstream agent — sends a request to Kong AI Gateway over HTTPS with mTLS (mutual TLS, two-way authentication). Kong AI Gateway authenticates the caller, checks rate limits, runs the prompt firewall, applies any PII redaction on the input, and routes the request downstream to the agent runtime via HTTP/2 sidecar. Every event in the ledger that follows carries four identifiers: `event_id` (a uuidv7 — a time-ordered UUID format that sorts chronologically), `turn_id`, `session_id`, and `causation_id`. The `causation_id` links each event back to the event that triggered it, making the full causal graph reconstructable from the log without any external metadata.
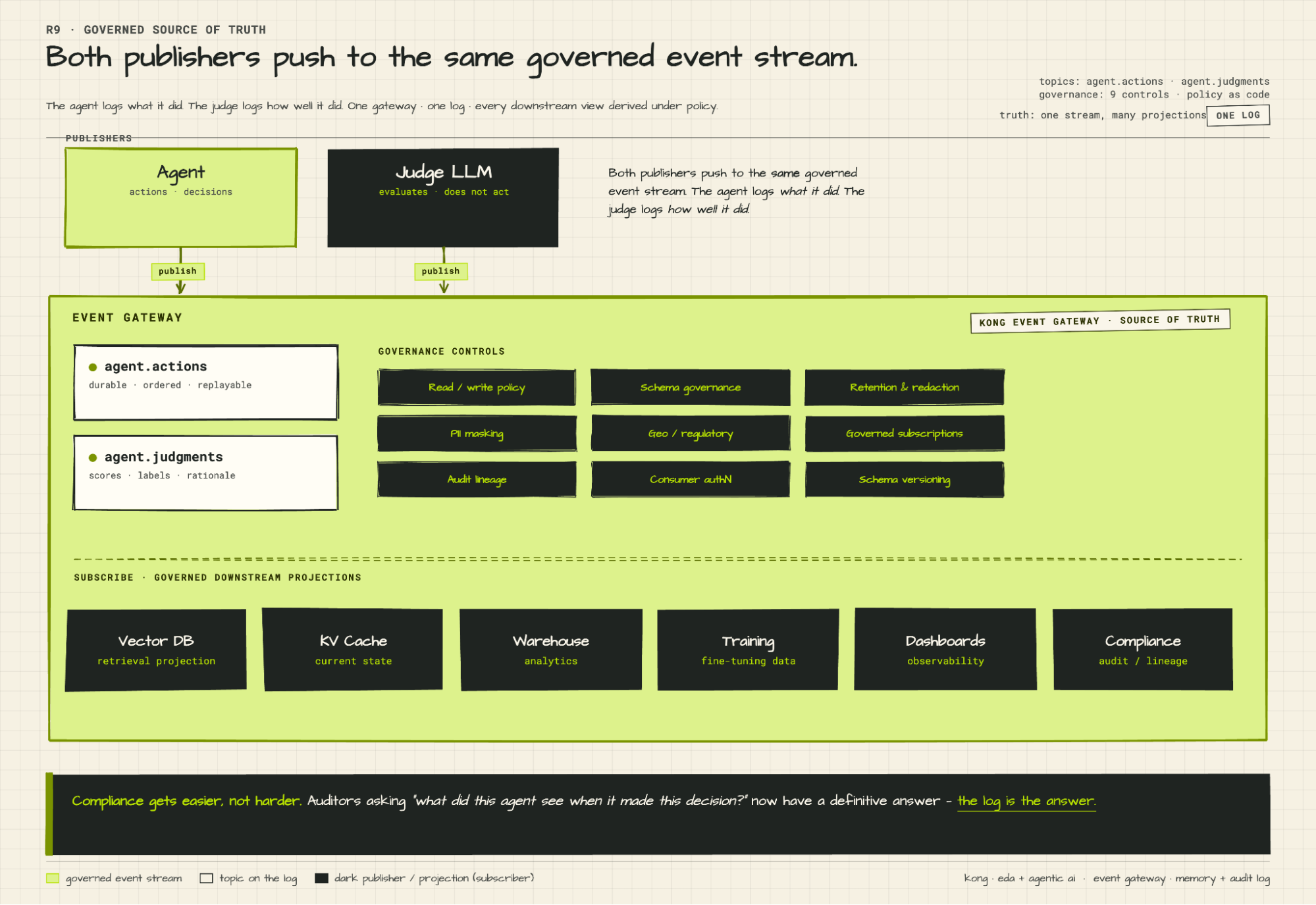
**Step 3: Agent publishes its invocation.**
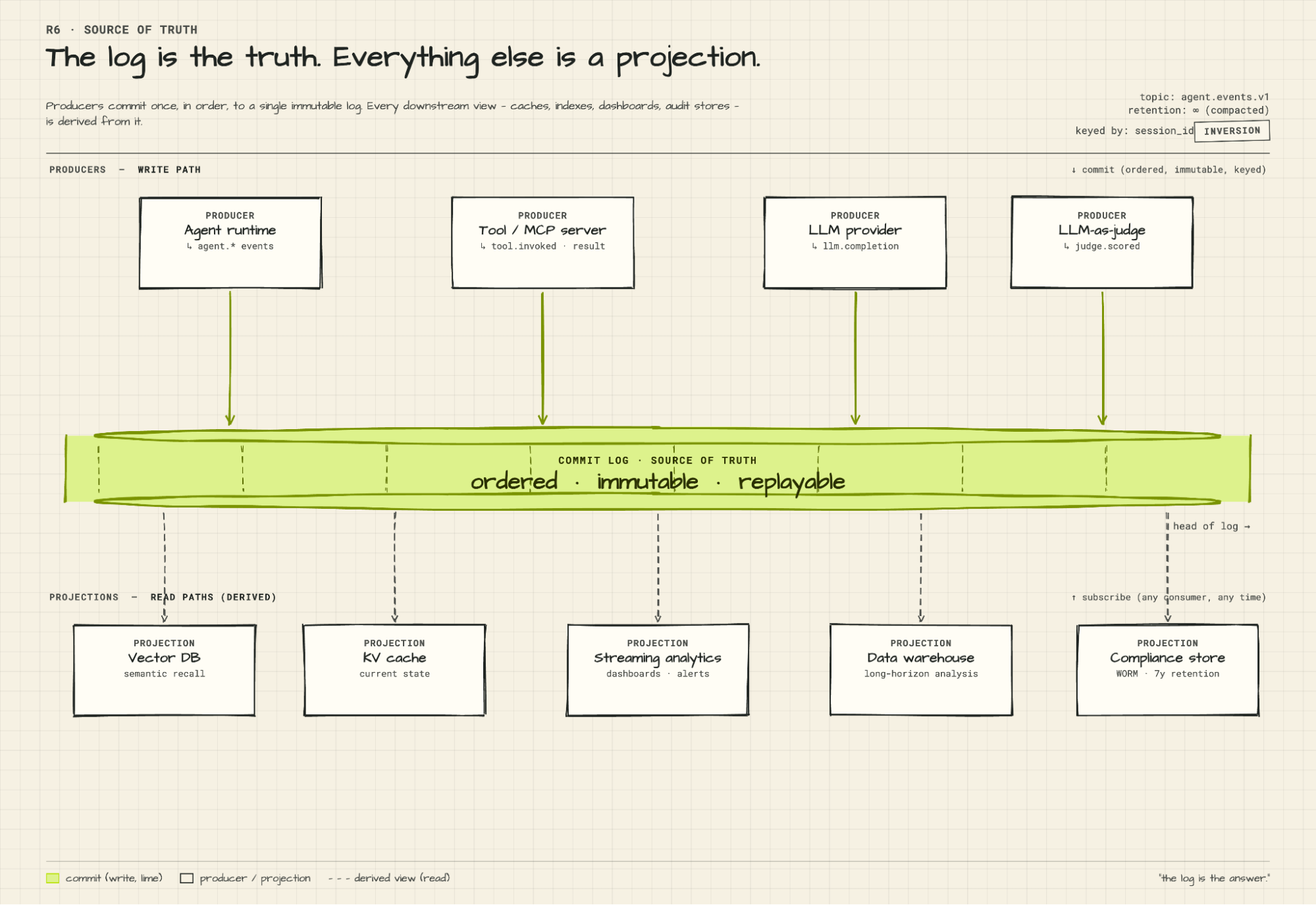
The agent runtime starts the turn and immediately publishes to the `agent.invoked` topic via Kong Event Gateway. Schema: `AgentInvoked.v1`. This is the agent's declaration that a turn has begun, logged before any reasoning happens.
**Step 4: Event Gateway commits to Kafka.**
Kong Event Gateway validates the schema, enforces the topic ACL (access control list), and writes the event to the Kafka commit log on the partition determined by `hash(session_id)`. The broker sends back an `ack` once all in-sync replicas confirm the write.
**Steps 5–6: LLM call and tap.**
The agent calls the LLM provider via Kong AI Gateway. Kong AI Gateway enforces the token budget, redacts PII from the prompt, and proxies the request to Anthropic or OpenAI over HTTPS. When the completion comes back, Kong AI Gateway taps it and publishes `llm.completion` → `LlmCompletion.v1` to Kafka. The agent receives its completion. The log receives a structured record of exactly what the model was asked and what it returned — captured at the wire level, not inside the agent.
**Steps 7–9: Tool invocation and tap.**
The agent calls an MCP tool over JSON-RPC. Kong AI Gateway enforces tool-level RBAC before the call goes through. On the way back, Kong AI Gateway taps both the invocation and the result, publishing `agent.tool.invoked` and `agent.tool.result` → `ToolInvoked.v1` to Kafka. Kong Event Gateway writes both events to the commit log. If the session has parallel tool calls in flight, they land in the same partition in the order they complete, preserving the causal sequence.
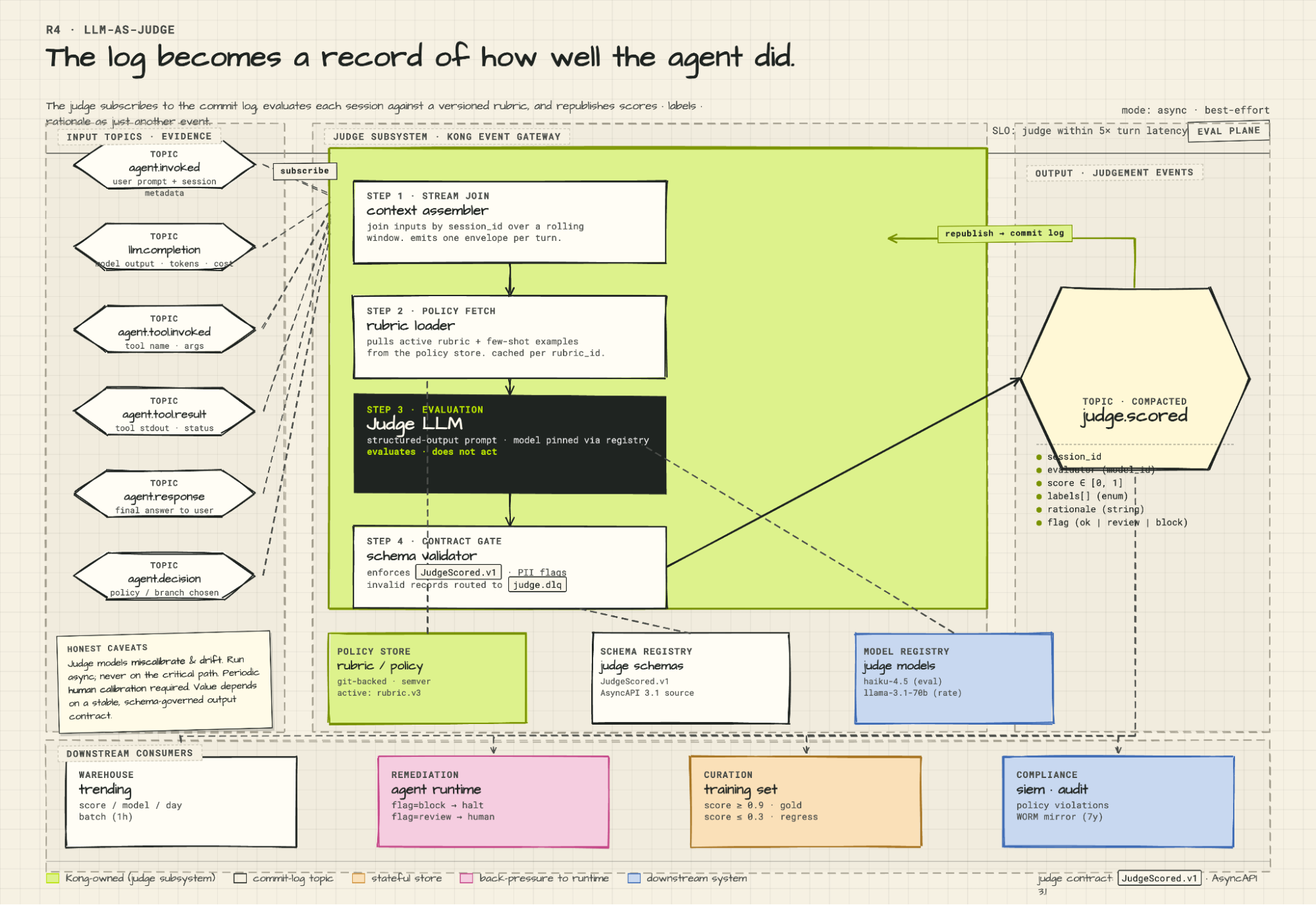
**Steps 10–11: Judge LLM scores the turn.**
A separate judge LLM running inside ksqlDB subscribes to `agent.*` topics and consumes the turn as events land. The critical distinction: it evaluates, it does not act. It scores reasoning quality, flags anomalies, and publishes `judge.scored` → `JudgeScored.v1` back to Kafka via Kong Event Gateway with three fields: a numeric score, a classification label, and a natural-language rationale. The log is now a record not just of what the agent did, but how well it did it. Aggregated over time, that's continuous quality trending — drift in reasoning quality shows up as a trend in the scores before it shows up as a production incident. A failure judgment can trigger a downstream alert in Splunk or, if you wire it, become an input event for an automated remediation workflow. The judgment stream also produces curated training data: every scored interaction, labeled by the judge, is a candidate for fine-tuning the next model version. One caveat worth stating directly: judge models miscalibrate and drift. They need periodic human calibration. Most run asynchronously, which means judgment lag is a real operational variable. The value of the judge loop depends entirely on consistent, schema-governed event output — if the underlying action events are malformed or inconsistent, the judge's scores are meaningless. This is why schema governance isn't optional infrastructure; it's what makes the quality loop reliable.