**1. What is prompt hacking?**
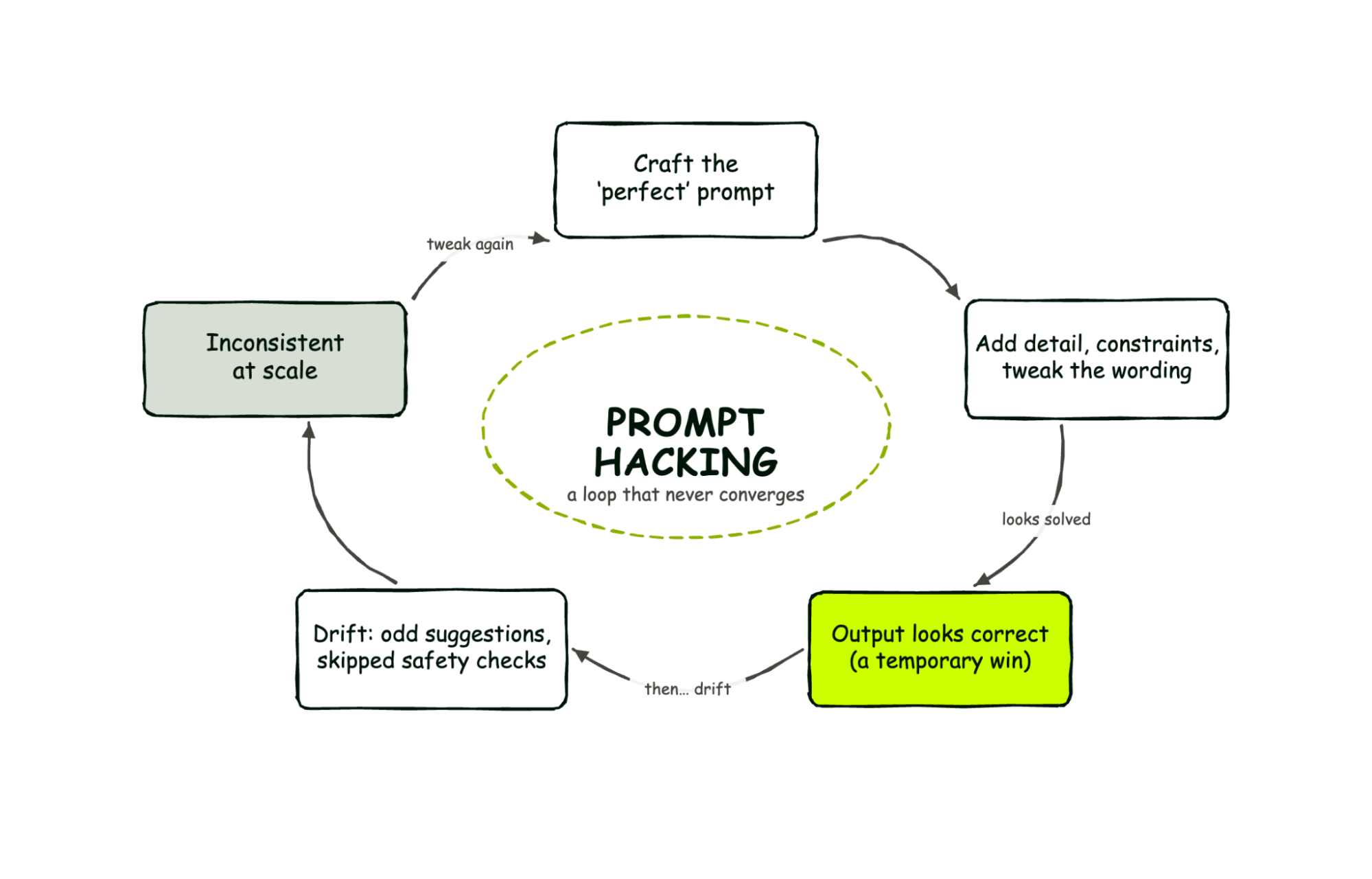
Prompt hacking is the practice of iteratively refining LLM instructions to coerce consistent, reliable outputs from generative AI models. Teams add constraints, restructure wording, and fine-tune context in an effort to control model behavior. While it can produce short-term improvements, prompt hacking treats a probabilistic system as if it were deterministic software, which leads to fragile results that drift over time.
**2. Why does prompt engineering fail at enterprise scale?**
Prompt engineering fails at scale because LLM outputs depend on statistical sampling, token probabilities, and dynamic training patterns — not fixed logic. A prompt that works today may produce different results tomorrow due to model updates, context shifts, or infrastructure changes. Enterprises need repeatable execution, but prompt-level control cannot guarantee it across thousands of requests and changing conditions.
**3. What is architectural determinism in AI?**
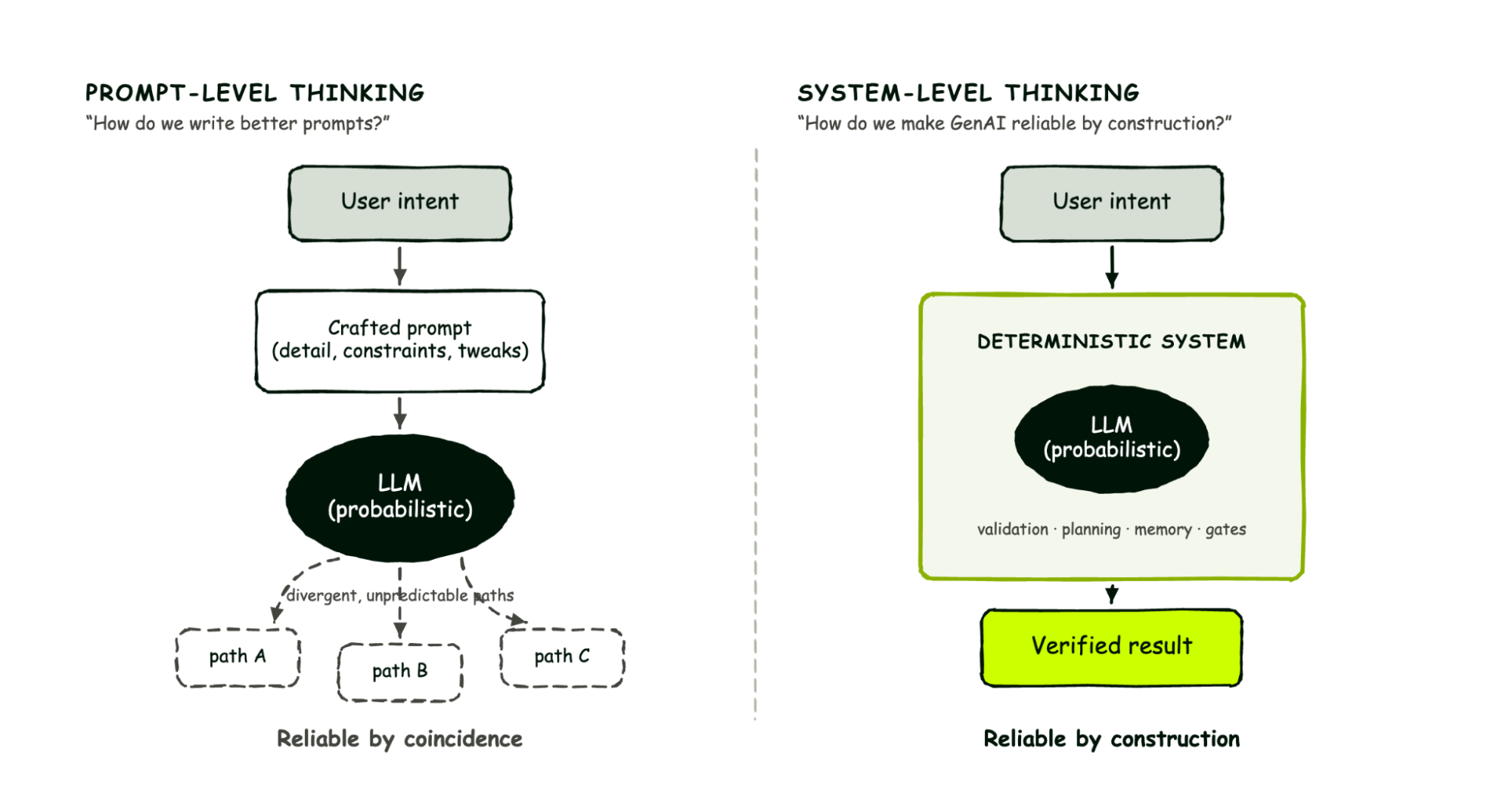
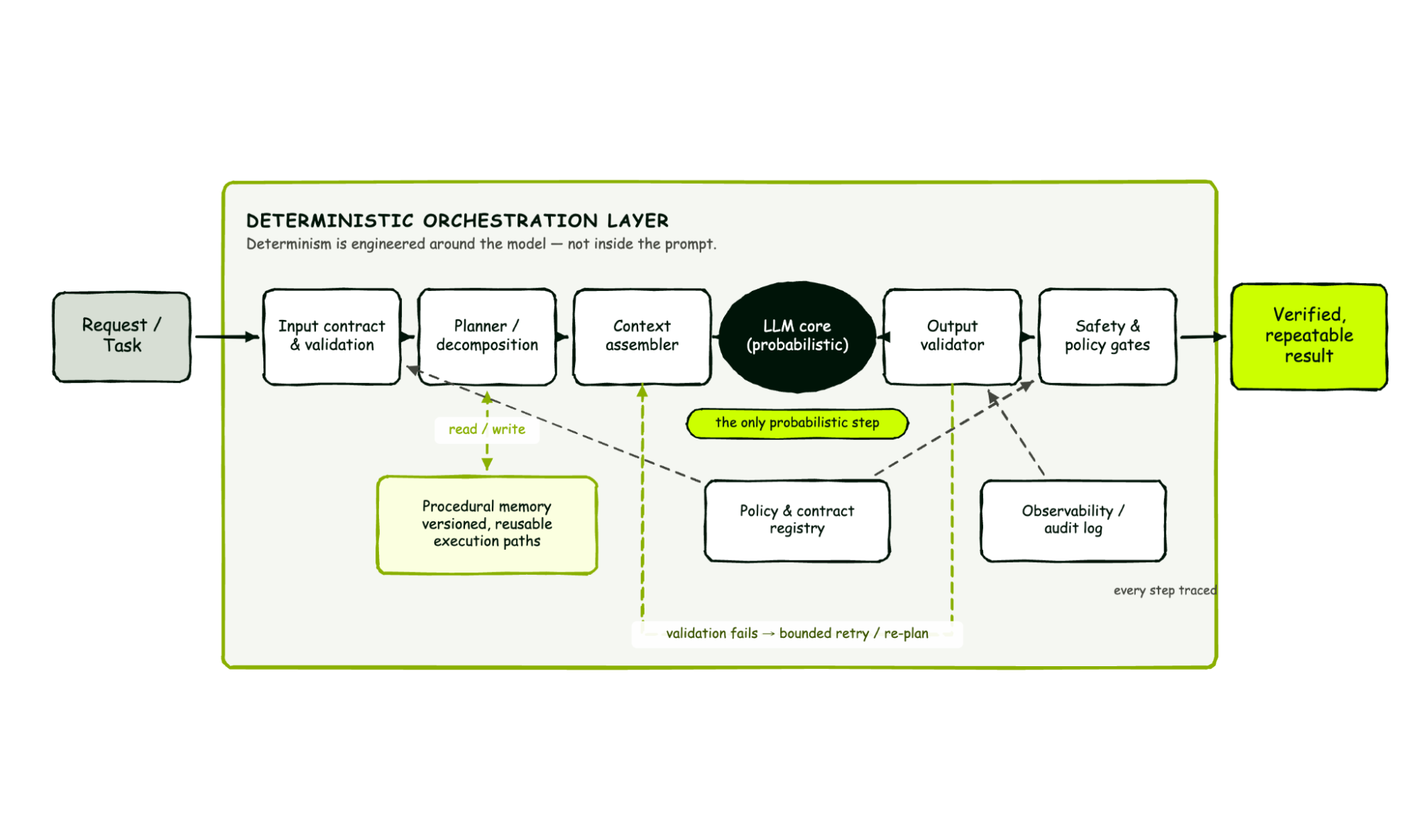
Architectural determinism is a design approach where reliability is engineered into the systems surrounding an AI model rather than into the prompt itself. Instead of refining instructions, teams build governance layers, validation steps, and structured workflows that constrain model outputs at the system level. This shifts responsibility for consistency from the model to the architecture.
**4. What is the difference between prompt engineering and system-level AI governance?**
Prompt engineering focuses on crafting better inputs to influence model behavior. System-level AI governance applies external controls — authentication, traffic management, policy enforcement, and observability — around the model at the infrastructure layer. Solutions like an AI gateway enforce these controls on every LLM request automatically, making AI reliable by construction rather than relying on the model interpreting instructions correctly.
**5. How can enterprises make generative AI reliable for production?**
Enterprises make generative AI production-ready by wrapping models in architectural controls rather than relying on prompt refinement. This includes structured validation of outputs, deterministic workflow orchestration, traffic governance with policy enforcement, and real-time observability. An AI gateway that governs LLM traffic with rate limiting, guardrails, and access controls provides the reliability layer that prompts alone cannot deliver.
**6. Why can't LLMs produce deterministic output?**
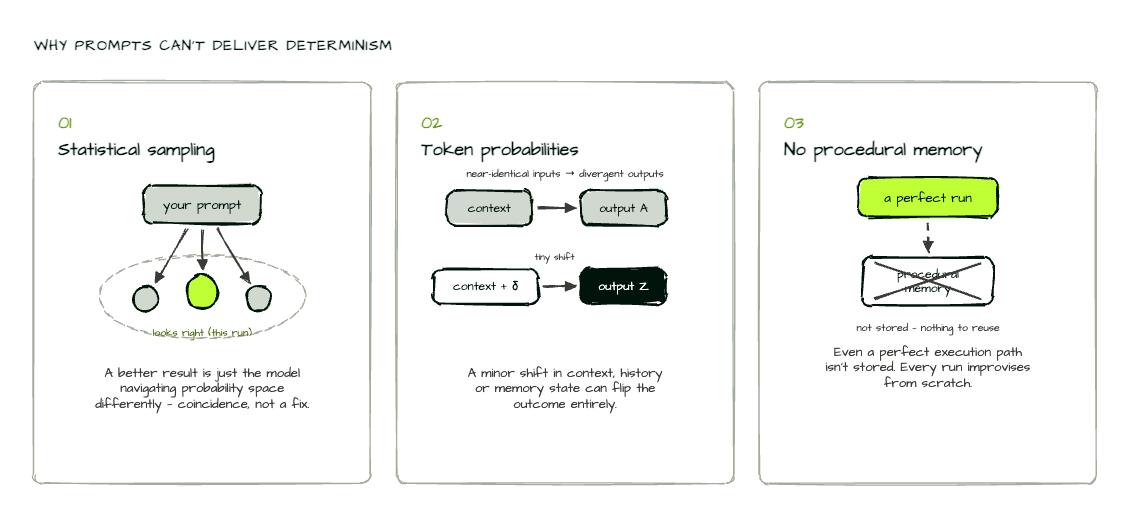
LLMs generate text through probabilistic sampling across learned token distributions, which means every response involves an element of randomness. Adjusting parameters like temperature or seed values reduces variability but does not eliminate it. Model updates, provider-side optimizations, and changes in conversation context further alter outputs, making true determinism impossible at the model layer alone.
**7. What replaces prompt engineering for enterprise AI?**
The shift is from prompt engineering to system architecture. Enterprises design deterministic execution frameworks with structured inputs, validation checkpoints, and governance policies enforced by an AI gateway layer. This approach treats the model as one component within a controlled pipeline — with traffic management, cost controls, and security applied at the infrastructure level — producing repeatable results regardless of prompt wording.
**8. What are the risks of relying on prompt engineering for mission-critical AI?**
Relying solely on prompt engineering for mission-critical systems creates unmanageable technical debt. Minor context changes can produce radically different outputs, and the model cannot store procedural learning between executions. This means every request is an act of improvisation. For enterprises, this translates to inconsistent automation, compliance risk, and operational failures that scale with the volume of AI-driven decisions.