The first thing we needed was a way to identify which tests were flaky and how often they failed. Luckily, the team had already built a dashboard on top of Datadog's CI Visibility feature that gives us a clear picture of the flakiest tests and their failure rates.
We used that dashboard as the benchmark for our fixes, and used its list to seed the agents.
Here's the agentic workflow we settled on after a few rounds:
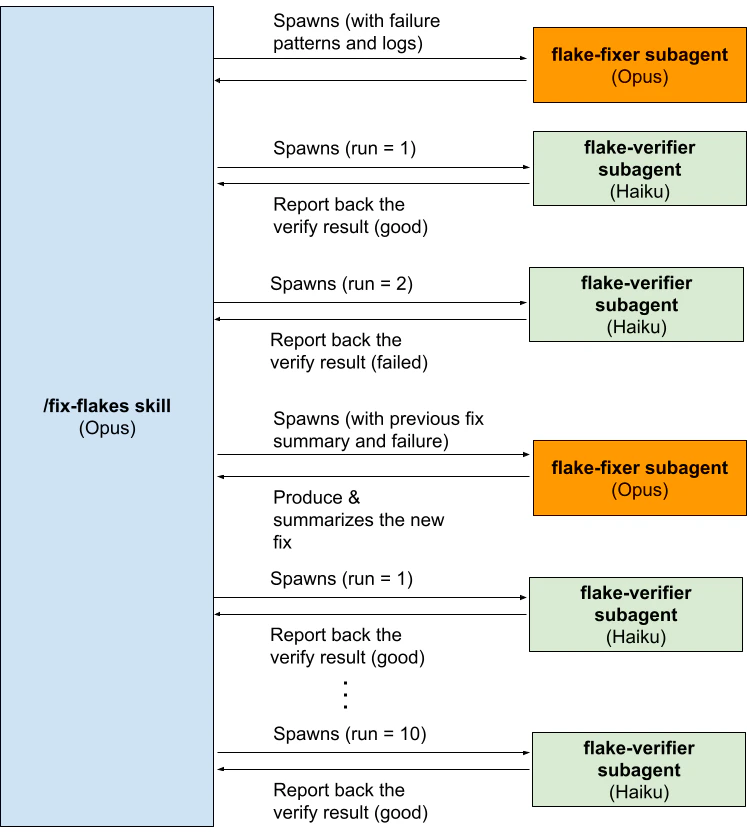
At the top level is the **fix-flakes** skill, the orchestrating agent, which runs on Opus. It takes a seed file — a flaky test's Datadog CSV export — and reads it to download all the CI logs from that test's recent failures. This step matters: failure logs usually contain vital clues about what's going wrong (as an example, a test failure after running for exactly 20 seconds could signal agents to look closely at timeout conditions), and they keep the agent grounded instead of guessing and hallucinating.
Once the failing test is identified and its logs are downloaded, **fix-flakes** spawns an Opus **flake-fixer** subagent to investigate and produce a fix. This is usually the most expensive step in token terms, but it generally runs in under 10 minutes — the **flake-fixer** often has to sift through multiple log files and dozens of source and test files to form a hypothesis and write a fix.
When **flake-fixer** is satisfied, it creates a branch, commits the fix, and pushes it to the repository. It then reports a summary of its theory and reports back to the orchestrator and exits.
The orchestrator then launches a **flake-verifier** subagent to check the fix. **flake-verifier** is a smaller Haiku agent, because each rerun produces more than one failure — there are other flaky tests in the suite — and the agent has to decide whether the test in question is fixed while filtering out the rest as noise. The CI output is scattered across many unstructured log files, and we found Haiku to be the easiest and most reliable way to judge whether a rerun succeeded. flake-verifier polls the run periodically until it can call success or failure, then reports back.
The orchestrator keeps spawning **flake-verifier** subagents to match the "rerun streak" configured when the skill is invoked. If no failure shows up across the full streak, **fix-flakes** open a PR for review. If a **flake-verifier** reports a recurrence at any point, the orchestrator downloads and combines the new failure logs with the previous **flake-fixer** summaries, spawns a fresh **flake-fixer**, and repeats — until the test is fixed and verified, or a maximum attempt count is reached, at which point it reports the failure.
Finally, the verified PR goes through normal human code review, same as any PR a person opens, and gets merged.









