# How Checkr Built a Hybrid API Management System With Kong Gateway
Kong
*This article was written by Ivan Rylach, a staff software engineer from Checkr. *
Checkr is the leading technology company in the background check industry. The company was moving to a services-oriented architecture. To scale this process, we switched to a declarative configuration for API management. As the staff software engineer at [Checkr](https://checkr.com)Checkr, I faced more scenarios where declarative configuration was not suitable by design. This post, and the video below, will explain these cases. I will also walk through the hybrid API architecture we created using many tools, including [Kong Gateway](https://konghq.com/get-started#install)Kong Gateway, to address them.
A ***declarative configuration**** allows you to define the result you want, and the system finds a way to configure it. *
*An ****imperative configuration**** requires you to specify the result you want and the steps the system needs to take to configure it.*
## **Scaling API Management With Kong API Gateway**
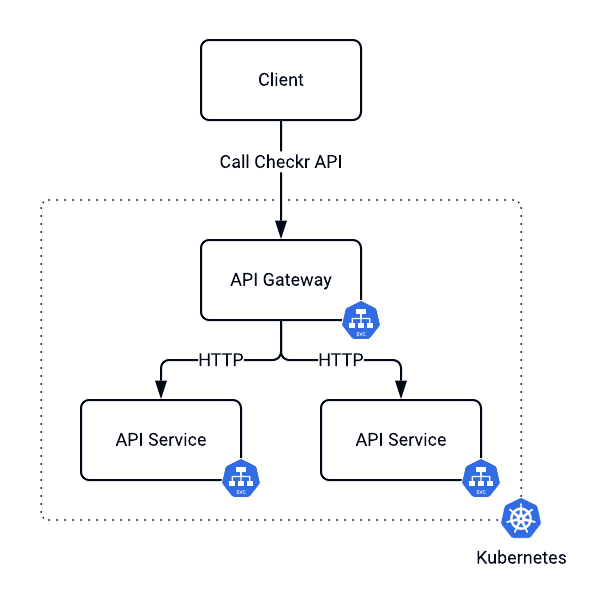
Checkr's API provides a complete background check and screen workflows. We use a few methods to suit our customers' needs. For example, some of our clients use applicant tracking systems or human resource information systems. We provide direct integration with these solutions. Other customers prefer having direct access to the API. To protect all of Checkr's solutions, we enable both API key authentication and user token authentication.
### ***As Checkr continued to grow, a standard process for managing APIs became critical. We needed a way to manage our APIs efficiently to further company growth. ***
An [API gateway](https://konghq.com/blog/learning-center/what-is-an-api-gateway)API gateway is an architectural pattern that could address this challenge. It sits between your client and API providers and acts as a single entry point for the traffic into the system. This centralized solution allows organizations to set up a governance model that puts requirements on how the traffic runs to servers and the security requirements. It also helps it enforce service license agreements and provides auditing and analytics.
## **Moving From Imperative to Declarative Management**
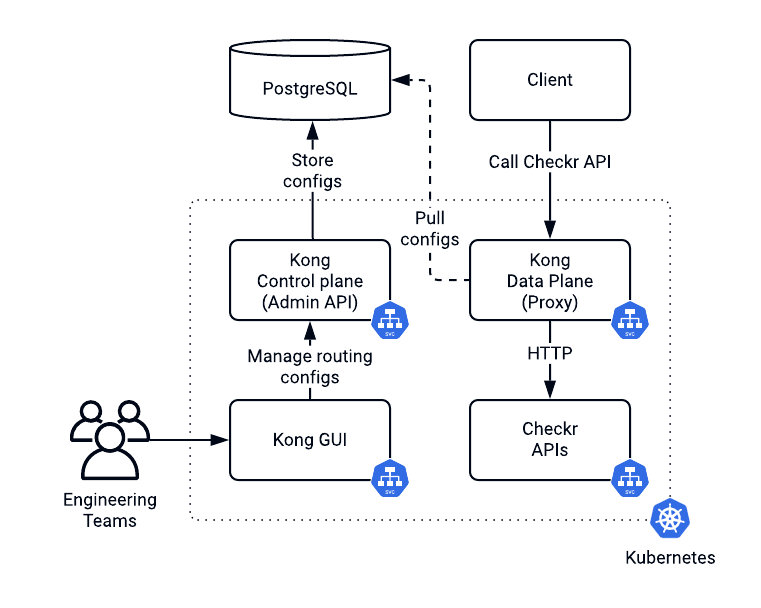
When we presented Kong into our system, Checkr was relatively small. At the time, imperative management was enough for one team to handle the API gateway. If you wanted to change it, for example, by presenting a new route or a rate limit, you could just access a GUI.
At some point, we had to present a user acceptance testing environment. That way, customers and partners could test Checkr’s API ahead of the main launch. This setup was manual and prone to error. The engineering teams discovered inconsistent API gateway configurations from one environment to another. The teams enabled some functionality in production, but it was missing in UAT. This solution did not allow us to deploy the system efficiently across regions either. We had to rethink the whole approach.
**We decided to switch to a declarative approach that would: **
- Allow us to deploy the system without manual steps
- Permit us to view the history of changes
- Require a review and approval from other members of the team
- Be available across regions
### ***Kong enabled us to move from an imperative to a declarative system. ***
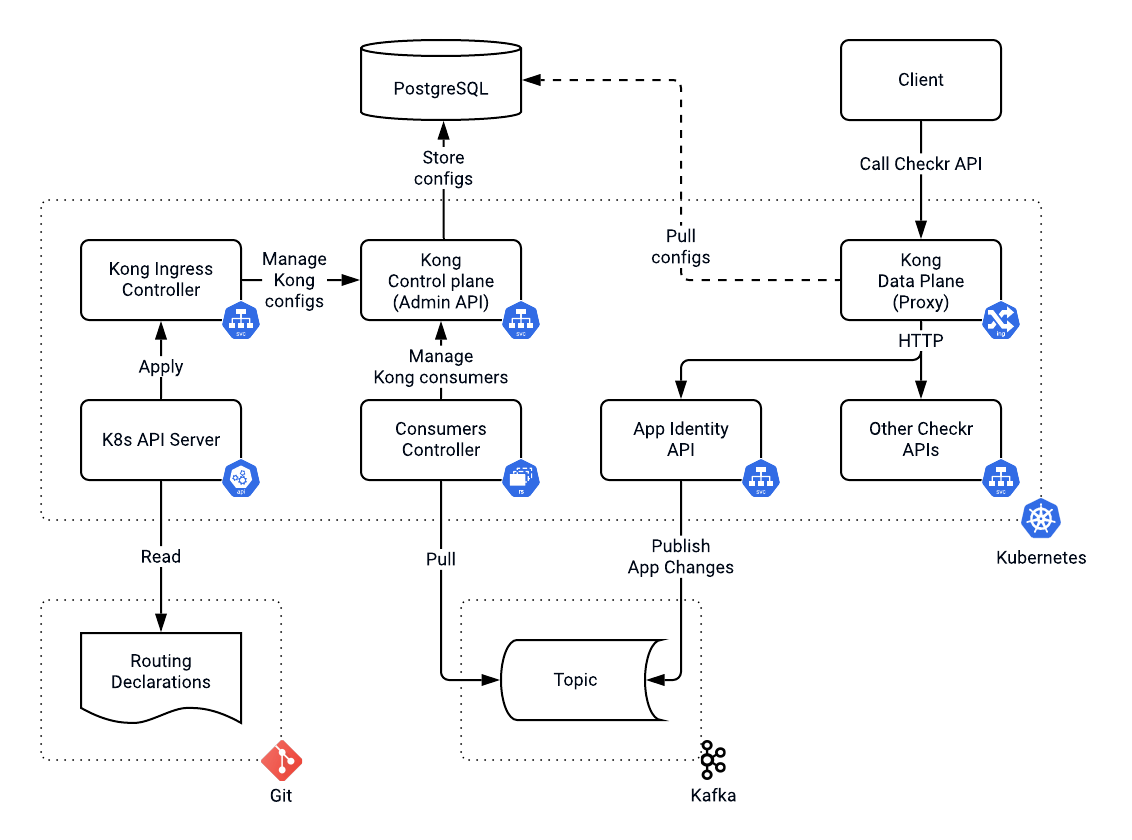
The Kong Ingress Controller allowed us to express all configurations using custom resource definitions (CRD).
Helm on its own was already a potent tool. Helm natively supports the inheritance of declarations. We used Helm templates to create Kubernetes Ingress rules via CRDs. We then applied Kong plugins to Ingresses once in the current values file. During the deployment, we overrode target hostnames for different environments, groups and regions. This approach allowed us to guarantee identical topology for the system while being flexible enough to deploy it anywhere.
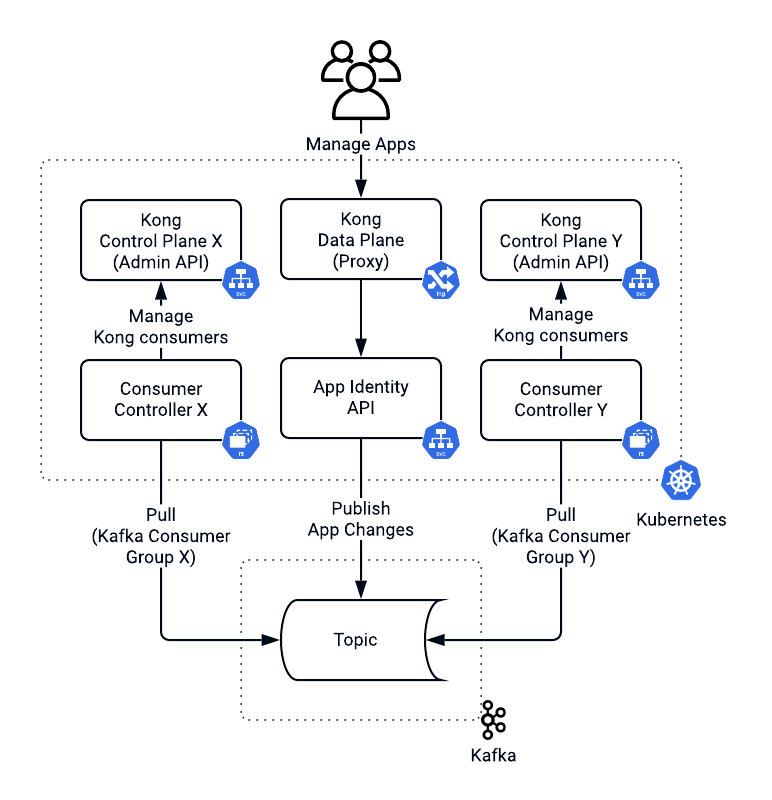
We leveraged [Kong](https://konghq.com)Kong to authenticate an incoming request by validating an API key or an authorization bearer token. We associated every API key with a Kong consumer (the application using the API) to enable rate limiting per application identity. New developers and partners could now sign up for the platform in a self-serving manner. That meant we could not manage API keys from consumers using a declarative approach. By design, it required manual intervention, which would negatively impact the user experience. Developers needed to be able to invoke our APIs as soon as they signed up.
We had to upgrade to the latest version of Kong without any downtime. This upgrade required us to go through many significant conversions. During the switch to the new major version, we would restart both our [Kong control](https://docs.konghq.com/2.0.x/hybrid-mode/#setting-up-kong-control-plane-nodes)Kong control and data planes, which increases the risks of something going wrong. We also needed a rollback strategy without any customer impact. Thereby, we decided to isolate Kong data planes and bring up the latest Kong version in parallel to the old one. A DNS configuration drove a switch between Kong data planes. With isolated data planes, management of consumers and associated API cases and plugins turned into a distributed transaction challenge. If propagation of changes failed in one of the data planes, we would need to roll it back in all others.
To ensure eventual consistency between deployments, we used a total order broadcast pattern. Doing so required a queuing mechanism like Kafka.
At Checkr, we used Kafka to orchestrate background checks and screening workflows for a while. In the solution we designed, the app identity service published all app changes to Kafka.
The consumers controller managed Kong consumers and associated plugins with one deployment per Kong control plane (admin API) and its own Kafka consumer group. Kafka promised the order of messages within a partition. Hence, app identity used the app's unique identifier as a topic partition key. Doing so ensured that we processed all changes for a given app in the same order as they occurred. This architecture allowed us to propagate app identity changes across Kong control planes. As you may remember, we had another requirement, which was cross-regional support.
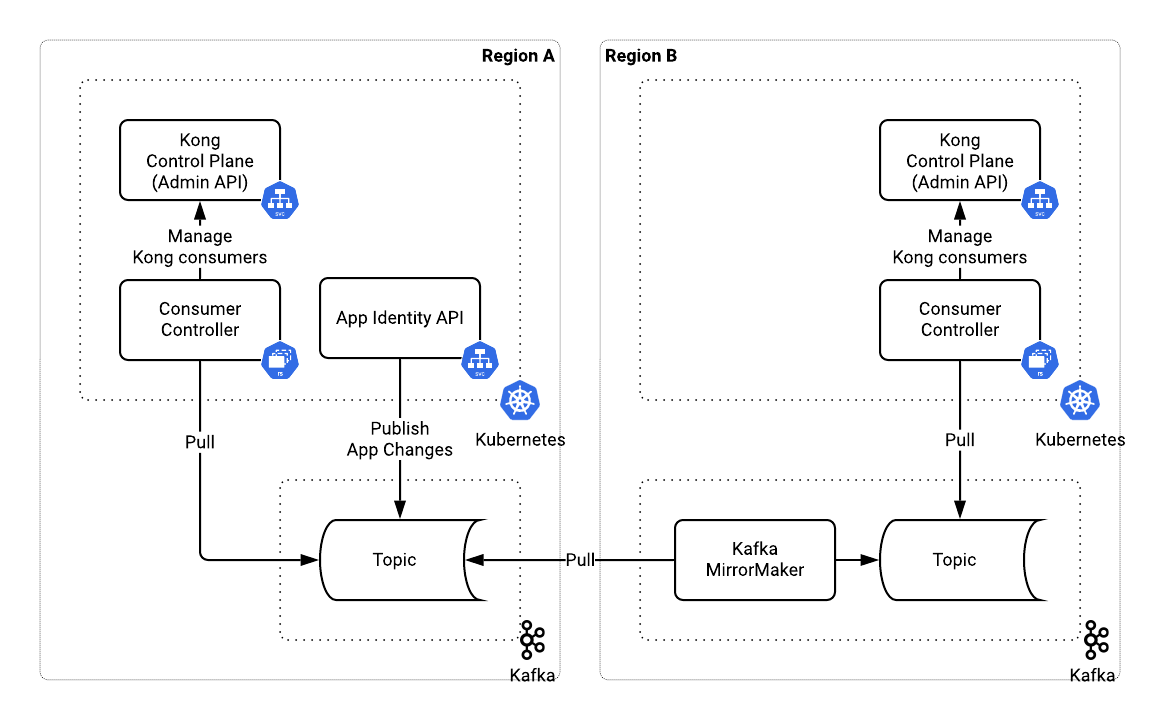
## **Enabling Multi-Region Availability**
Kafka helped us have multiregional deployments of the system by propagating consumer changes. [Kafka MirrorMaker](https://kafka.apache.org/documentation/#basic_ops_mirror_maker)Kafka MirrorMaker replicated a Kafka topic into another region where we could deploy local consumer controllers. Upon setup, all deployments across all regions became typologically identical. The only difference was the producer of events in a Kafka topic - app identity service in the primary region and MirrorMaker in others. Now, let’s put it all together.
## **Establishing the New Hybrid System**
We had a hybrid system with a global control plane where routes and configurations were stored using Git. Routes and configurations did not change frequently and needed auditing and manual validation. Consumers, their API keys and the rate limit settings propagated into Kong automatically, assuring eventual convergence toward the same state.
The rest of the organization could now expose their new services' APIs using Helm templates for Kong Kubernetes CRDs. We stored Helm files in the same repository as the application source code. All changes to the traffic routing followed the standard software development lifecycle.
With this, the described architecture delivered on all requirements that we have set in the beginning. We enabled the company's efficient growth. And we had automated deployments of the platform to any environment and region.
This article was written by Jeremy Justus and Ross Sbriscia, senior software engineers from UnitedHealth Group/Optum. As part of the UnitedHealth Group (UHG), Optum optimizes healthcare technology, and one of our important missions is to provide the
Imagine 47 million requests hitting your platform last month. Can you prove who made each one—and invoice with confidence? If that question tightens your stomach, you're not alone. Metered billing for APIs promises fair, transparent pricing that s
Today, we’re excited to announce the release of Kong Gateway 2.8 , which further simplifies API management and improves security for all services across any infrastructure. This announcement demonstrates Kong’s continued commitment to our customers
Imagine you have a single Service, order-api . You want to apply a strict rate limit to most traffic, but you want to bypass that limit—or apply a different one—if the request contains a specific X-App-Priority: High header. Previously, you had t
How OAuth 2.0 Token Exchange Reshapes Trust Between Services — and Why the API Gateway Is Exactly the Right Place to Enforce It
Modern applications don’t run as a single monolithic. They are composed of services — frontend APIs, backend microservi
The challenges of an acquisition frequently appear in a number of critical areas, especially when dealing with a platform as important as Kafka: API Instability and Change : Merged entities frequently rationalize or re-architect their services, whic
Traditional APIs are, in a word, predictable. You know what you're getting: Compute costs that don't surprise you Traffic patterns that behave themselves Clean, well-defined request and response cycles AI APIs, especially anything that runs on LLMs