* This is part of a 3-part series on APIs, sustainability, and climate change. Check out *[*part 1*](https://konghq.com/blog/climate-change-reduce-impact-api)*part 1** on managing a greener API lifecycle, and *[*part 2*](https://konghq.com/blog/apis-building-blocks-green-innovation)*part 2** on ways to embed and innovate on top of third-party APIs to make greener products. In this final part, we will look at the environmental impact of common architecture trends and recommend steps to take to minimize the impact of each.*
## Monolith to Microservices
Ah, if I had a pound every time someone said this phrase. Overwhelmingly the most popular transformation I see companies making, and with many business critical processes still being powered by systems built in and before the 1970s, a transformation that won't let up any time soon.
Now, you might think that replacing systems built in the 1970s with modern technology delivers an immediate efficiency gain. After all, it's difficult to optimize a heavy monolith as all the system resources are shared by all the modules, and the technology stack tends to be older and less efficient.
Microservices are independently scalable and can be individually configured, resulting in less wasteful usage of resources: we have the power to auto-scale or burst the deployment footprint for traffic peaks so we have less sitting around idle the rest of the time, and we can reduce the size of individual VMs to maximize utilization and therefore [consume less energy](https://principles.green/principles/applied/microservices/#heading-increase-your-compute-utilization)consume less energy. Containers are a great way to do this; for example, [Nordstrom](https://kubernetes.io/case-studies/nordstrom)Nordstrom increased CPU utilization from 4% to 40% when they containerized their applications and adopted Kubernetes.
However, as we decompose the monolith into microservices, we go from a handful of in-app connections to an exponentially increasing number of microservices all talking to each other over various networks. We've gone from big, centralized systems to very chatty, distributed services; i.e. a considerable increase in network traffic.
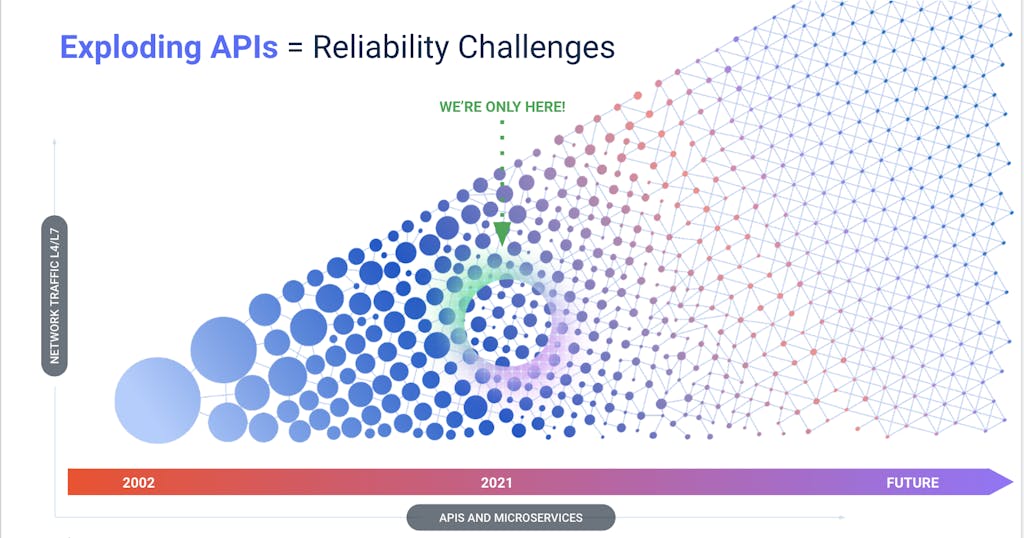
We need to ensure this increase does not translate into a net increase in resource consumption. To prevent this, we should use the most appropriate transfer protocol for the traffic; consider implementing services in gRPC rather than REST, which tests have shown is 7 to 10 times faster due to the use of [HTTP/2](https://medium.com/@EmperorRXF/evaluating-performance-of-rest-vs-grpc-1b8bdf0b22da)HTTP/2 and streaming, and the highly compressed Protobuf message format. Consider compressing large payloads before sending them over the wire.
## Service Mesh: A Network Necessity
With an increasing amount of network traffic, it becomes imperative to manage that traffic: we need to eradicate unnecessary requests, shorten the distance traveled, and optimize the way messages are routed. We achieve this with a service mesh. Technologies like [Kong Mesh](https://konghq.com/kong-mesh)Kong Mesh manage all inbound and outbound traffic on behalf of every microservice, implementing load balancing, circuit breaking, and reliability functions as well as security and service discovery: capabilities that minimize unnecessary requests and give you visibility of the requests that do take place.
For example, circuit breakers prevent traffic from being routed to faulty instances: traffic that would otherwise be abandoned and wasted. This all happens through a sidecar proxy deployed next to the microservice itself, which means fewer network hops and therefore less traffic in the first place compared to implementing these capabilities centrally, or the wasted resources caused by application developers coding this logic into each microservice individually. Most service mesh technologies are limited to Kubernetes deployments, meaning these benefits can only be realized for microservice-to-microservice communication within the K8s ecosystem.
Although the CNCF's [most recent survey](https://www.cncf.io/wp-content/uploads/2020/11/CNCF_Survey_Report_2020.pdf)most recent survey says 83% of respondents are using K8s in production, this does not mean all workloads are now in K8s: we see most organizations actually need to manage microservice traffic across VMs and other environments too. This is why we've built Kong Mesh to support VMs and bare-metal deployments as well as K8s; it is not enough to only manage your Kubernetes traffic.
**Recommendations: **
- - Containerize workloads and optimize for maximum CPU utilization
- - Use appropriate protocols to reduce the consumption of each network call
- - Manage network traffic through a deployment agnostic service mesh
## Event-driven Architectures
In our digital world, consumers expect a real-time response after an interaction. I recently changed my direct debit details online with my Internet provider, and immediately thought something had gone wrong when my profile wasn't instantly updated to reflect my new details. Turns out everything was fine and they just didn't support real-time updates yet, but between you and I, I still don't trust them because their digital capabilities are weak.
We've been going through the shift from batch processing to real-time processing for several years, to deliver these enhanced capabilities that people like you and me expect. But the way we implement real-time processes is important for our sustainability goals.
A few years ago, I saw an over-rotation in the use of synchronous, RESTful APIs. Don't get me wrong, they are absolutely vital for pretty much every part of digital transformation: APIs unlock our data and make it available, on-demand, in easy-to-use formats; however, APIs are not the answer to everything. Consider what real-time means: the way a system immediately reacts to something that has happened; an event, essentially.
The way this is implemented with RESTful APIs is through polling. An API is configured to run every X seconds, to check if something has happened. If nothing, then hold your fire and wait for the next poll X seconds later to see if something's happened then. If something has happened, then take that data and do the downstream processing (for example, updating a customer's direct debit details on their profile).
Now here's the killer… [98.5%](https://resthooks.org)98.5% of API polls don't return any new information. Nothing. This means the vast majority of polls are a total waste of energy. We have a whole load of APIs sitting there idle, doing absolutely nothing other than burning up resources. It's like a small child in the back of your car constantly asking "are we nearly there yet?", forcing you to say "no not yet" for the hundredth time. Exhausting!
Wouldn't it be better if you could just update them when you were nearly there yet? Lower stress levels, less energy used. This is the power of event-driven architectures (EDA): a system that will only act when there is something that needs to be done. When an "event" occurs, such as a payment details update, that should then invoke downstream services to do the relevant updating.
This downstream processing should be fast, but asynchronous; it results in a bad user experience if the system – and response back to the client – is blocked waiting for all this processing to occur. Therefore we switch patterns from these synchronous, request-response APIs that are constantly polling for changes and waiting for each other, to something like a [pub/sub](https://www.enterpriseintegrationpatterns.com/PublishSubscribeChannel.html)pub/sub pattern, where we publish events onto a message broker, e.g. Kafka, for subscribed consumers to then receive and act upon.
It's like sharing a life update in a WhatsApp group: all your family and friends in that group will receive the message and hear about your update at the same time, rather than each family member constantly texting you every hour to see if anything's changed. You've only had to send one message, rather than one or many to each family member individually. They haven't had to text you at all, they just receive a message when there's news. The overall energy spent is much lower.
Following an EDA approach, we're only using compute when it's actually needed rather than wasting it with services waiting for a change in an idle state. Of course, synchronous APIs are still necessary for our overall system, and plugins like Kong's [Kafka Upstream plugin](https://docs.konghq.com/hub/kong-inc/kafka-upstream)Kafka Upstream plugin give us an easy way to transform API requests into Kafka messages for a combination of API and event-driven architectures.
**Recommendations:**
- - Implement EDA for asynchronous processing
- - Replace API polling – a pull mechanism – with a push mechanism
## Reusable APIs vs Point-To-Point Integration
Every leader I speak with understands the value of an API-first integration approach, where we build and expose reusable APIs rather than building new, point-to-point integrations every time we need two systems to communicate. It's faster, cheaper, more maintainable, less prone to issues, and easier to change. I'm going to add one more benefit to this list: a well-designed API-first approach is also better for the environment.
A key principle of green software engineering is to use fewer resources at higher utilization, reducing the amount of energy wasted by resources sitting in an idle state; i.e. use things we have as much as possible rather than creating new things all the time that will only be used once. This correlates to integration patterns: the more we reuse APIs, the less time they're idle and therefore the less energy they waste (assuming every API call is necessary). On the contrary, in a point-to-point approach, code is built for one specific purpose: to connect A to B. It cannot be reused for connecting B to A, sending data in the opposite direction. It cannot be reused for connecting A to C.
Now consider the fact that there are n(n – 1) connections in a network of n nodes. Let's say you have 10 systems: this means there are 90 different connections between them. Now let's be realistic because no company has just 10 systems; the average company [integrates over 400](https://solutionsreview.com/data-integration/companies-are-drawing-from-over-400-different-data-sources-on-average)integrates over 400, equating to a totally unmanageable 159,600 single-use connections when following a point-to-point approach. That's 159,600 individual services, all deployed on infrastructure running somewhere, using energy from somewhere to power them to sit idle the vast majority of the time. What a waste.
When you have this many connections, the overall architecture is complex. Pathways between systems are convoluted and unexpected; things are so tangled that this state is often called "spaghetti code". This is the opposite of what we picture when we describe an efficient system: here we have a lot of wasted network traffic, trying to find the shortest path from A to B, and wasted traffic means wasted energy consumption.
On the other hand, an API-first approach leads to much simpler architectures and highly reused services, particularly those sitting around back-end systems. This means more efficient message routing and load balancing, simpler code (as integration logic isn't rewritten a gazillion times into each service individually), and higher utilization of deployed code.
More holistically, it's easier to make a simpler, API-first architecture more sustainable. It's impossible to assess a current state when you have no idea what's in it, and it's impossible to know if you're making things more efficient when you don't know your starting point. When you have a smaller number of managed APIs registered in a gateway, you can see all the connections in your estate. When you have point-to-point code sitting all over the place doing overlapping and unknown things, you can't.
Managing your APIs in a gateway like [Kong](https://konghq.com/kong)Kong gives you the ability to understand, audit, and therefore refactor your API implementations for efficiency. It gives you visibility of how, where, and when each API is used, giving you valuable insight when it comes to optimizing APIs for reuse and minimal network traffic.
**Recommendations:**
- - Choose an API-first approach to integration rather than point-to-point code
- - Manage all APIs in a gateway for auditability and optimization
## You, Dear Reader, Now Have To Do Your Bit
Whether motivated by your conscience (I hope) or by the fact more efficiency means higher profits for your business (sadly still most companies' top priority) I ask two things of you:
- - Change. Take action. You don't even need to stand up! The next time you're building or versioning an API, build it following green engineering principles. The next time you're breaking down a monolith into microservices, minimize the microservice traffic. Remove unnecessary network hops. Bring this up in decision sessions and architecture review boards. Educate your colleagues, do more of your own research. Just please don't read this, agree with it, and then continue doing everything exactly as before.
## We’re Just Getting Started
Now I bet some of you may disagree with some of the things I've said, or have further suggestions of other things we can do. I want to hear it. Come and challenge me and brainstorm with me because we all need to put our heads together to figure this out. There is no blueprint, we have to build it as we go. And right now we're just at the beginning.
*This is part 3 of a series on APIs, sustainability, and climate change. Check out *[*part 1*](https://konghq.com/blog/climate-change-reduce-impact-api)*part 1** for ways to build more efficient and sustainable APIs, and *[*part 2*](https://konghq.com/blog/apis-building-blocks-green-innovation)*part 2** for ways we can use third-party APIs to improve our own processes and build innovative new ones that help fight the problem.*








