## Athenahealth Sets Up a Self-Healing API Gateway with Kong
A billion daily healthcare transactions, unified through Kong with resilience engineered into every request
1 Billion
API requests daily
<1 ms
response latency
0
config loss across multi-region deployments
## Sustaining 1 billion secure healthcare API calls daily
Athenahealth operates one of the most interconnected healthcare technology networks in the United States, supporting practices of every size with cloud-based clinical and revenue cycle solutions, processing nearly a billion API interactions every day.
## Powering healthcare data exchange at national scale
In modern healthcare, system reliability is inseparably entwined with patient care. Athenahealth, a trailblazer in cloud-based healthcare technology, supports clinical practices of every size with software that streamlines administrative workflow and enables physicians to deliver better patient outcomes. Each appointment booked, prescription sent, insurance verification submitted, or lab order transmitted depends on the infrastructure underneath it.
At the center of that infrastructure is Kong Gateway, the unified entry point for Athenahealth’s API ecosystem.
"Kong is our central front door."
Athenahealth runs 500–700+ microservices, operates across a hybrid footprint of AWS and on-prem data centers, and serves over 10,000 distinct API clients. The platform handles nearly one billion requests per day, including HL7 and FHIR exchanges that drive interoperability networks between providers, labs, payers, and clinical systems. More than 20 custom Kong plugins ensure routing, rate-limiting, and security remain tailored to the unique requirements of regulated healthcare environments.
At this scale, resilience isn’t an afterthought. It must be engineered into the foundation.
## Scaling healthcare APIs with consistency, speed, and the ability to absorb failure
As Athenahealth’s traffic volume accelerated, intermittent issues surfaced — each small on its own, but compounding when multiplied by millions of calls per hour. The engineering team recognized a pattern: quick fixes solved symptoms, not long-term stability. They needed durable design principles that would hone performance even under failure conditions.
Several constraints demanded attention.
- -
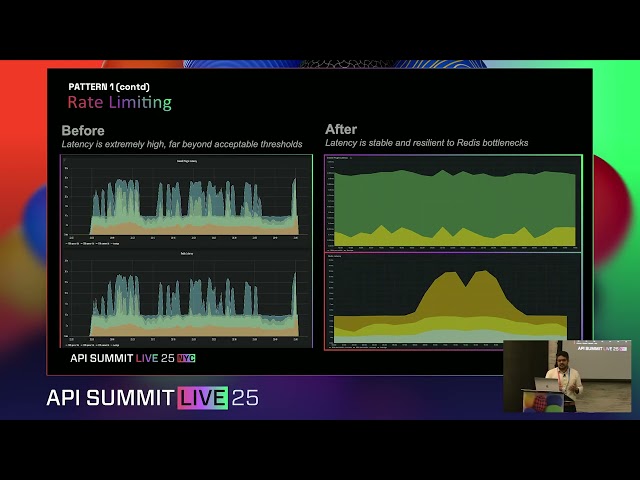
**Redis rate-limit enforcement became a bottleneck under stress **— Initially, rate-limits were counted by making live calls to Redis. As traffic scaled, this pattern created latency spikes. During upgrades or system strain, Redis slowed, and that slowdown cascaded through Kong, delaying requests dramatically. In worst cases, response time ballooned to 30 seconds, unacceptable for clinical workflows.
- -
**Quotas drifted between U.S. regions** — Because clients accessed Athenahealth services from multiple geographic zones, rate limits sometimes differed between east and west regions. Without synchronization, the system risked inconsistent enforcement, a compliance and reliability concern in healthcare environments. “The same client could travel to different destinations…in the east we had one quota, in the west a different quota," Mohideen said.
- -
**Low-volume clients saw unexpected latency** — Some healthcare integrations generate only 5–10 requests daily. This low frequency translates into cache expiry before the next call, forcing the gateway to fetch data repeatedly from Redis. In a 60+ node deployment, requests could land anywhere, and every uncached route introduced avoidable latency.
- -
**Configuration updates risked being lost across regions** — With 10,000+ partners, onboarding and updating rate-limits is routine. If an update reached one region but failed in another, the system state could diverge. During failover events, configuration mismatches could propagate operational issues.
- -
**Observability lacked the depth required for incident response** — With hundreds of services, Athenahealth needed faster ways to identify slow routes, failing endpoints, rising error rates, and partners breaching thresholds. Raw access logs weren’t enough; debugging required structured intelligence.
The patterns were clear: for the system to be resilient, it needed to anticipate failure, tolerate breakdown, and maintain performance even when components degraded.
“Keeping the system resilient, scalable, consistent… every time we encountered a problem, one-off fixes weren’t enough.”
## Building resilience as a framework, not a patch
The engineering team developed a set of resiliency patterns designed to scale gracefully, self-recover, and maintain uniform performance regardless of load or node location. Instead of relying on external systems for every real-time decision, they redesigned internal mechanisms to reduce dependency overhead and improve predictability.
### Pattern 1: Distributed rate limiting with dual counters
Athenahealth introduced a local shared-memory rate-limit tracker that updates instantly without contacting Redis for each request. Two counters run in parallel.
To eliminate Redis bottlenecks and keep latency near zero even during peak demand, Athenahealth implemented a dual-counter strategy inside Kong. A Global counter handles periodic synchronization with Redis and other gateway nodes, maintaining a shared source of truth for rate limiting across regions. In parallel, a local delta counter tracks request volumes in real time directly within the node, removing the need for constant remote lookups.
This architecture gives the team the best of both worlds — globally consistent enforcement without sacrificing local performance. In practice, it means rate-limits stay accurate across clusters while requests continue flowing at millisecond speed.
A background NGINX timer synchronizes state in batches at around 100ms intervals. This reduced Redis calls massively, stabilized throughput, and eliminated latency spikes during backend stress. After implementation, the system maintained consistent sub-millisecond response times, even during Redis pressure events.
### Pattern 2: Consistent quotas using Redis hash-tag placement
To resolve regional drift, Athenahealth used deterministic key placement so that all rate-limit updates for a given client route to the same shard. Regardless of where requests originate, quota enforcement remains identical across clusters, which also improves predictability during failover.
### Pattern 3: Proactive cache prefetching
Rather than waiting for the first request to warm cache, the team loaded frequently-used route metadata at startup. From there, periodic refresh processes kept the cache warm without client interaction. The result was dramatic: earlier ~10ms request times dropped consistently to under 1 millisecond, even for low-volume clients. If Redis became unavailable, cached entries allowed services to continue operating, serving stale data temporarily, but never failing outright.
### Pattern 4: Queue-backed configuration management
A queue was inserted ahead of Kong configuration APIs, acting as a buffer. If a region became unreachable, updates accumulated and replayed automatically when healthy. No partner configuration is lost, even during a disaster recovery event.
### Pattern 5: Deep observability and normalized routing logs
Athenahealth built a log-enrichment plugin to embed route metadata, latency fields, status breakdowns, and standardized path mappings into access logs. Using Backstage and OpenAPI specifications, paths were normalized automatically, allowing engineers to correlate performance issues with specific endpoints instantly. The plugin runs only at the log phase, meaning no added latency to live requests.
Custom Prometheus metrics were introduced, including:
- - concurrency per service
- - background sync latency for rate-limit updates
- - per-partner usage and breach history
- - success/failure counts for each plugin execution
These dashboards transformed troubleshooting from forensic labor into proactive detection.
### Pattern 6: Automated failover via Route 53 health probes
Previously, failovers required manual DNS switches which were stressful during incidents and prone to operational friction. With health-based routing in place, traffic now shifts automatically when regional service degradation is detected. Engineers receive an alert but no action is required to maintain uptime.
## A gateway to anticipate stress, absorb failure, and self-recover
With Kong as its unified gateway and resiliency patterns embedded into engineering DNA, Athenahealth achieved the one thing healthcare technology demands — confidence at scale.
Athenahealth now operates a gateway capable of withstanding traffic surges, backend stalls, cold-cache scenarios, and regional outages without degrading user experience. Improvements were measurable and sustained.
Athenahealth’s platform performance strengthened measurably following the resiliency overhaul. By removing Redis from the hot path, the team eliminated the 30-second latency spikes that occasionally surfaced under load, reducing request processing to a consistent roughly around 1 millisecond even at high volume. With deterministic quota synchronization in place, rate-limits now remain perfectly aligned across east and west regions, preventing drift and ensuring fairness regardless of traffic origin. Cache performance also improved significantly — low-volume clients who once faced cold-start latency now experience near-instant responses, powered by proactive cache warming.
Operational reliability advanced at the same pace. Configuration updates are now guaranteed across 10,000+ partners without risk of loss, thanks to a queue-driven replication model that survives regional outages. Automated failover further removed friction by shifting DNS routing without human intervention, eliminating the midnight manual cutover events that once accompanied production incidents. Finally, with enriched logs, normalized routes, and granular metrics, observability has moved from reactive diagnosis to rapid insight, accelerating debugging and strengthening incident readiness across the entire gateway.
The organization now operates with greater confidence. APIs remain fast, predictable, and secure, even when components underneath strain or shift.
Athenahealth didn’t just build an API platform that works at scale. They built one that heals itself.
Athenahealth’s journey demonstrates the power of designing for resilience instead of reacting to instability. Through distributed counters, proactive caching, deterministic quota routing, event-queued updates, deep observability, and automated failover, the company now sustains nearly a billion secure healthcare API calls daily with millisecond-level responsiveness.
The gateway is not merely scalable; it is stable, recoverable, and future-proofed.
More Customer Stories
“We use Kong Konnect for vitals, management, and the dev portal that exposes our APIs—all as a central platform for automation."
“Our REST communication layer gives partners flexibility. They just use a POST endpoint, and Kong handles the rest.”
"PEXA is classified as critical infrastructure for Australia, which means our APIs can never go down. Kong sits at the center of that resilience."
Container leasing industry leader replaces legacy EDI with real-time API management
Global investment advisor builds a Kong-powered APIOps platform, saving $2.4M annually and embedding governance by default
400+
applications standardized
One of the world’s largest gaming companies uses Kong to process 7 billion requests weekly, with low latency and while meeting strict regulatory requirements
2 Billion
Requests on Super Bowl Sunday
Global payments leader streamlines API governance, accelerates delivery, and explores agentic automation through spec-first design and Model Context Protocol (MCP).